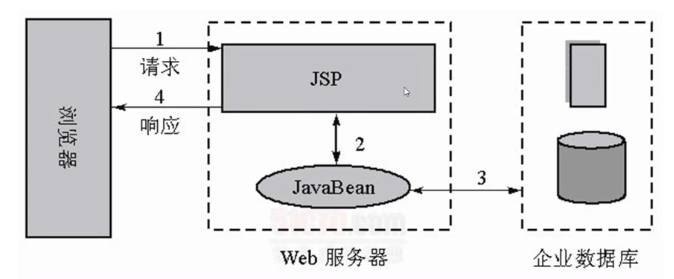
一台电脑他可以部署很多个服务器
那我们通过ip地址(本地回环地址127.0.0.1/localhost)找到这个电脑了通过端口来区分不同的服务器.
注意:
// 1. 导入模块
const fs = require("fs");
const http = require("http");
const path = require("path");
// 2. 创建web服务器
const server = http.createServer((request, response) => {// 3. 读文件返回// 3.1 拼接妖谱读取的文件路径const fullPath = path.join(__dirname, "web", "index.html");// 3.2 读取这个文件的内容fs.readFile(fullPath, "utf-8", (err, data) => {if (err == null) {response.end(data);} else {console.log("404");}});
});
// 4. 开启服务器
server.listen(4399, () => {console.log("success");
});

// 1. 导入模块
const fs = require("fs");
const http = require("http");
const path = require("path");// 2. 创建服务器
const server = http.createServer((request, response) => {// 3. 设置返回给用户的内容// 3.1 首先你要知道用户请求的是那样一个页面(哪一个资源)console.log(request.url);// response.end("666");// 3.2 拼接要读取文件的路径const fullPath = path.join(__dirname, "web", request.url);// 3.3 读取这个文件// 服务器会有一个嗅探功能// 它根据你请求的资源名字,能够知道你请求的什么类型的资源// 知道了什么类型的资源后,就可以根据这种类型的资源返回内容fs.readFile(fullPath, (err, data) => {if (err == null) {response.end(data);} else {console.log("404");}});
});// 开启服务器
server.listen(4399, () => {console.log("服务器开启了...");
});
服务器干什么用。前端传参
get传参:拼接在url上面
http://127.0.0.1:4399/joke?id=8&username=admin
post传参:不是拼接在url上面
请求体中传递
const fs = require("fs");
const path = require("path");
const http = require("http");
const url = require("url");const server = http.createServer((req, res) => {// console.log(req.url); // /?id=8&username=admin// 我们可以通过req.url拿到前端传递过来的参数// 但是要做字符串处理// 我们可以使用node.js的一个模块:url模块// 调用它的parse方法// 第一个参数:就是要处理的url// 第二个参数:如果给true的话就返回一个对象let urlObj = url.parse(req.url, true);// console.log(urlObj);// 这个返回的对象里面有一个query属性,它也是一个对象,这个属性里面就youget传递过来的参数console.log(urlObj.query);// 那就可以在这里根据这个接收到的id,去数据库中获取这个id的英雄的所有详细信息// 返回给调用者// 如果在这里拿到了id对应的英雄的详细信息了,就可以返回,res.end(JSON.stringify(urlObj.query)); // 只能返回字符
});server.listen(4399, () => {console.log("服务器开启了...");
});
nodejs后端开发、
const http = require("http");
const querystring = require("querystring");const server = http.createServer((req, res) => {// req是请求对象// 因为这里是post的方式传递过来的参数,不是在url中的,所以用req.url是拿不到的// console.log(req.url)// 那如何拿呢?// 一小块一小块的拿// 1. 你得有一个容器let postData = "";// 2. 给req对象一个data事件// 事件处理程序,参数是当前这次传递过来的这一小块内容req.on("data", (chunk) => {postData += chunk;});// 3. 给req对象一个end事件// 表示数据传递完毕了req.on("end", () => {// 打印看看// console.log(postData); // username=admin&password=123456// 4. 解析这个传递过来的参数数据let postObj = querystring.parse(postData);console.log(postObj); // { username: 'admin', password: '123456' }// 5.//那在这里就可以根据这个传递过来的账号和密码,去数据库中判断是否是正确的//如果正确的那在这里就可以告诉用户,账号密码正确res.end("sb");});
});server.listen(4399, () => {console.log("服务器开启了...");
});
var Crawler = require("crawler");
var fs = require("fs");var c = new Crawler({encoding: null,jQuery: false, // set false to suppress warning message.callback: function (err, res, done) {if (err) {console.error(err.stack);} else {fs.createWriteStream(res.options.filename).write(res.body);}done();},
});// 爬取数据
//爬一个b站中的视频
//不是什么样的数据都可以爬下来,有些网站做了反爬
//反爬的机制:
// 看你这个请求是不是服务器,如果是就不给你数据
// 我们这里是node.js是服务端,有时候有的数据就不给你.
//解决的办法 ,伪装:
// 把我们这个node.js后端服务器请求伪装成客户端(浏览器);
c.queue({uri:// "http://msn-img-nos.yiyouliao.com/inforec-20200703-f906b655a759e35e6ee1e7470184f66f.jpg?time=1593758869&signature=663062FDBD08E6A3E802F2055B3D5F2E","https://cn-sxty2-cu-v-04.bilivideo.com/upgcxcode/46/29/203472946/203472946-1-16.mp4?expires=1593766200&platform=html5&ssig=faGf3-U7N-hzj6U60zc8Xw&oi=1006738461&trid=33046ef58ce948ddb69f3f9978c397e0h&nfc=1&nfb=maPYqpoel5MI3qOUX6YpRA==&mid=241600263&logo=80000000",filename: "06-npmUse/temp/meinv.avi",header: { "User-Agent": "requests" }, // 让服务端伪装成客户端
});
使用npm5之前的版本,是不会生成package-lockjson这个文件的。
npm5以后,包括npm5这个版本, 才会生成package-lock.json文件
当使用npm安装包的时候,npm都会生成或者更新package-lock.json文件
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态







![BZOJ 4421: [Cerc2015] Digit Division 排列组合](/upload/rand_pic/2-1461.jpg)