在Spark誕生之初,就有人詬病為什么AMP實驗室選了一個如此小眾的語言——Scala,很多人還將原因歸結為學院派的高冷,但后來事實證明,選擇Scala是非常正確的,Scala很多特性與Spark本身理念非常契合,可以說它們是天生一對。Scala背后所代表的函數式編程思想也越來越為人所知。函數式編程思想早在50多年前就被提出,但當時的硬件性能太弱,并不能發揮出這種思想的優勢。目前多核CPU大行其道,函數式編程在并發方面的優勢也逐漸顯示出了威力。這就好像Java在被發明之初,總是有人說消耗內存太多、運行速度太慢,但是隨著硬件性能的翻倍,Java無疑是一種非常好的選擇。
函數式編程屬于聲明式編程,與其相對的是命令式編程,命令式編程是按照“程序是一系列改變狀態的命令”來建模的一種建模風格,而函數式編程思想是“程序是表達式和變換,以數學方程的形式建立模型,并且盡可能避免可變狀態”。函數式編程會有一些類別的操作,如映射、過濾或者歸約,每一種都有不同的函數作為代表,如filter、map、reduce。這些函數實現的是低階變換,而用戶定義的函數將作為這些函數的參數來實現整個方程,用戶自定義的函數成為高階變換。
命令式編程將計算機程序看成動作的序列,程序運行的過程就是求解的過程,而函數式編程則是從結果入手,用戶通過函數定義了從最初輸入到最終輸出的映射關系,從這個角度上來說,用戶編寫代碼描述了用戶的最終結果(我想要什么),而并不關心(或者說不需要關心)求解過程,因此函數式編程絕對不會去操作某個具體的值,這類似于用戶編寫的代碼:
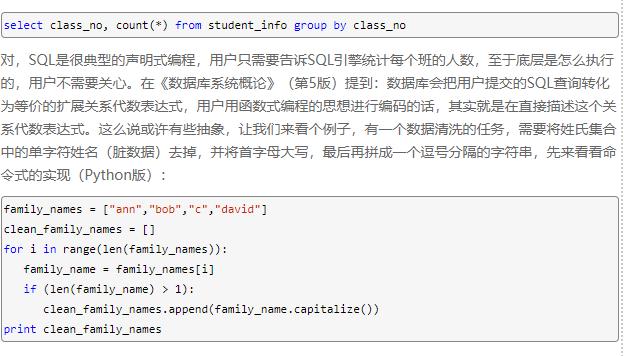
spark的廣播變量在執行端賦值?再來看看函數式(Scala版)的實現:
val familyNames = List("ann","bob","c","david")println(familyNames.filter(p => p.length() > 1).map(f => f.capitalize).reduce((a,b) => a + "," + b).toString())從這個例子我們可以看出,在命令式編程的版本中,只執行了一次循環,在函數式編程的版本里,循環執行了3次(filter、map、reduce),每一次只完成一種邏輯(用戶編寫的匿名函數),從性能上來說,當然前者更為優秀,這說明了在硬件性能羸弱時,函數式的缺點會被放大,但我們也看到了,在函數式編程的版本不用維護外部狀態i,這對于并行計算場景非常友好。
在嚴格的函數式編程中,所有函數都遵循數學函數的定義,必須有自變量(入參),必須有因變量(返回值)。用戶定義的邏輯以高階函數的形式體現,即用戶可以將自定義函數以參數形式傳入其他低階函數中。讀者可能對函數作為參數難以理解,其實從數學的角度上來說,這是很自然的,下面是一個數學表達式:
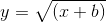
括號中的函數f1 = x + b作為參數傳給函數f2 =

scala變量的定義,,這其實是初中的復合函數的用法。相對于高階函數,函數式語言一般會提供一些低階函數用于構建整個流程,這些低階函數都是無副作用的,非常適合并行計算。高階函數可以讓用戶專注于業務邏輯,而不需要去費心構建整個數據流。
函數式編程思想因為非常簡單,所以特別靈活,用“太極生兩儀,兩儀生四象,四象生八卦”這句話能很好地反映函數式編程靈活多變的特點,雖然函數式編程語言能顯著減少代碼行數(其實很多代碼由編程語言本身來完成了),但通常讓讀代碼的人苦不堪言。除上述之外,函數式還有很多特性以及有趣之處值得我們去探索。
在純粹的函數式編程中,是不存在變量的,所有的值都是不可變(immutable)的,也就是說不允許像命令式編程那樣多次給一個變量賦值,比如在命令式編程中我們可以這樣寫:
x = x + 1
scala匿名函數。這是因為x本身就是一個可變狀態,但在數學家眼中,這個等式是不成立的。
沒有了變量,函數就可以不依賴也不修改外部狀態,函數調用的結果不依賴于調用的時間和位置,這樣更利于測試和調試。另外,由于多個線程之間不共享狀態,因此不需要用鎖來保護可變狀態,這使得函數式編程能更好地利用多核的計算能力。
如果使用低階函數與高階函數來完成我們的程序,這時其實就是將程序控制權讓位于語言,而我們專注于業務邏輯。這樣做的好處還在于,有利于程序優化,享受免費的性能提升午餐,如語言開發者專注于優化低階函數,而應用開發者則專注于優化高階函數。低階函數是復用的,因此當低階函數性能提升時,程序不需要改一行代碼就能免費獲得性能提升。此外,函數式編程語言通常只提供幾種核心數據結構,供開發者選擇,它希望開發者能基于這些簡單的數據結構組合出復雜的數據結構,這與低階函數的思想是一致的,很多函數式編程語言的特性會著重優化低階函數與核心數據結構。但這與面向對象的命令式編程是不一樣的,在OOP中,面向對象編程的語言鼓勵開發者針對具體問題建立專門的數據結構。
惰性求值(lazy evaluation)是函數式編程語言常見的一種特性,通常指盡量延后求解表達式的值,這樣對于開銷大的計算可以做到按需計算,利用惰性求值的特性可以構建無限大的集合。惰性求值可以用閉包來實現。
flink算子?由于在函數式編程中,函數本身是無狀態的,因此給定入參,一定能得到一定的結果。基于此,函數式語言會對函數進行記憶或者緩存,以斐波那契數列舉例,首先用尾遞歸來實現求斐波那契數列,Python代碼如下:
def Fibonacci(n):if n == 0 :res = 0elif num == 1:res = 1else:res = Fibonacci(n - 1) + Fibonacci(n - 2)return res當n等于4時,程序執行過程是:
Fibonacci(4)Fibonacci(3)Fibonacci(2)Fibonacci(1)Fibonacci(0)Fibonacci(1)Fibonacci(2)Fibonacci(1)Fibonacci(0)為了求Fibonacci (4),我們執行了1次Fibonacci(3)、2次Fibonacci(2)、3次Fibonacci(1)和2次Fibonacci(0),一共8次計算,在函數式語言中,執行過程是這樣的:
Fibonacci(4)Fibonacci(3)Fibonacci(2)Fibonacci(1)Fibonacci(0)一共只用4次計算就可求得Fibonacci(4),對于后面執行的Fibonacci(0)、Fibonacci(1),由于函數式語言已經緩存了結果,因此不會重復計算。
scala泛型、函數副作用指的是當調用函數時,除了返回函數值之外,還對主調用函數產生附加的影響,例如修改全局變量或修改參數。在函數式編程中,低階函數本身沒有副作用,高階函數不會(很少)影響其他函數,這對于并發和并行來說非常有用。
函數式編程思想與其他編程思想相比,并沒有所謂的優劣之分,還是取決于場景,Spark選擇Scala也是由于函數式語言在并行計算下的優勢非常契合Spark的使用場景。
Spark的開發語言是Scala,這是Scala在并行和并發計算方面優勢的體現,這是微觀層面函數式編程思想的一次勝利。此外,Spark在很多宏觀設計層面都借鑒了函數式編程思想,如接口、惰性求值和容錯等。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态