1.工具: chrome瀏覽器 vscode
2.先來分析一下學校教務處成績管理系統的結構,用的竟然是frame標簽!!首先是一個輸入學號的表單,找到表單后發現是一個post提交
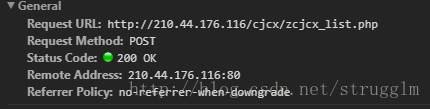
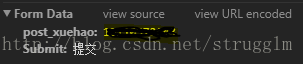
這里是提交的數據
3.找到這些模擬登陸就變得很容易了,下面貼代碼
import cgi
import cgitb
import json
import io
import pandas
import requests
from bs4 import BeautifulSoup
import jsonform=cgi.FieldStorage()
studentId=form.getvalue('id')def requestsData(url,headers,data):r=requests.post(url,headers=headers,data=data)return rdef htmlParser(r):soup=BeautifulSoup(r.text,'lxml')grades=soup.find_all('table')[3]tr_list=grades.find_all('tr')td=[tr.find_all('td') for tr in tr_list][1:]for data in td:a={"subject_id":data[1].text.lstrip('\xa0'),"subject_name":data[5].text.lstrip('\xa0'),"subject_xf":data[7].text.lstrip('\xa0'),"subject_grade":data[9].text.lstrip('\xa0')}yield(a)def fileWrite(data):for a in data:with open('file.txt','a',encoding='utf-8') as f:f.write(json.dumps(a,ensure_ascii=False)+'\n')f.close()def main():url='http://210.44.176.116/cjcx/zcjcx_list.php'headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'}data={'post_xuehao':'學號'}html=requestsData(url,headers,data)fileWrite(htmlParser(html))main()
if __name__ == '__main__':main()版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态