Scrapy
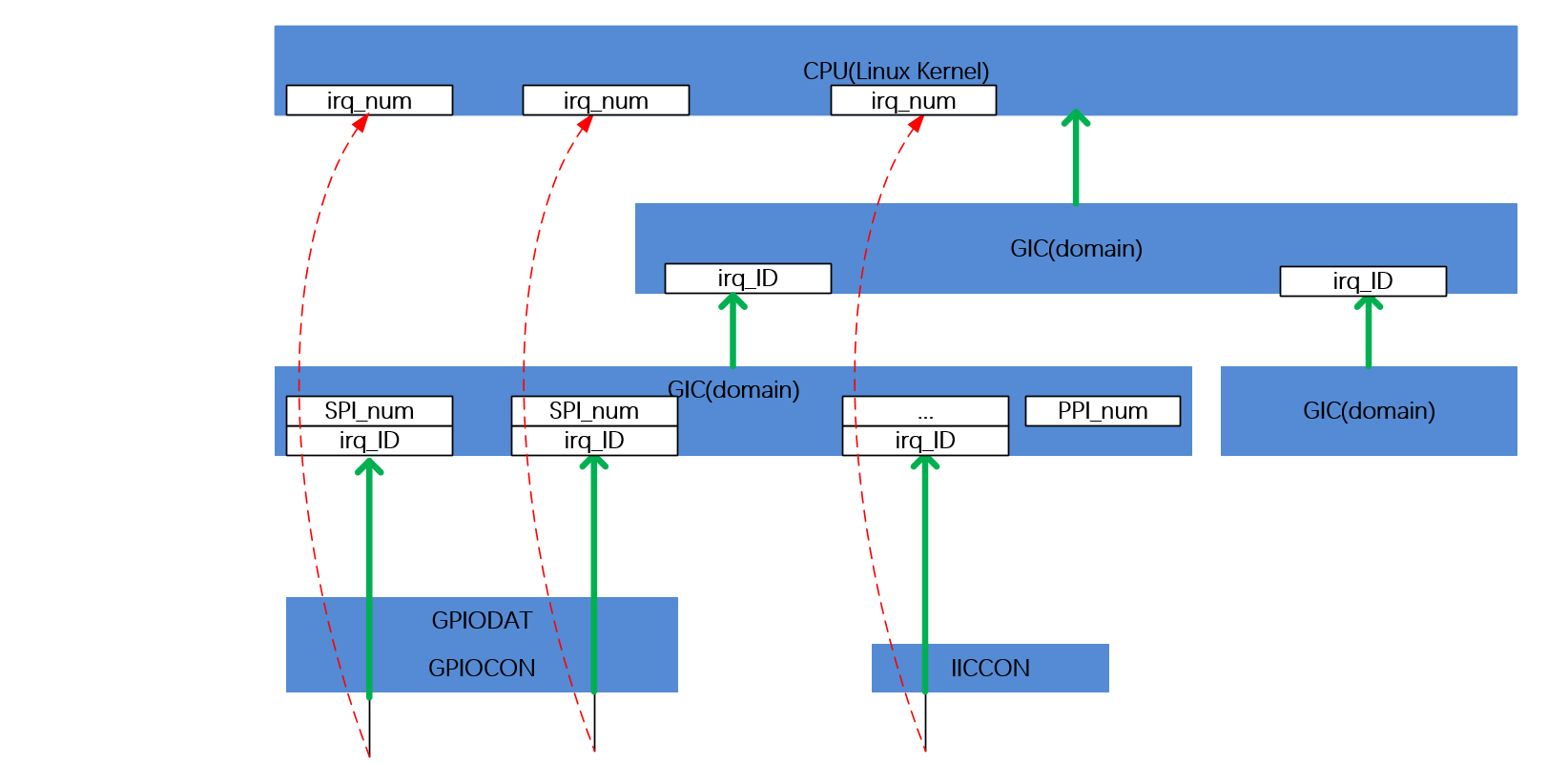
Scrapy是一個使用Python編寫的輕量級網絡爬蟲,使用起來非常的方便。Scrapy使用了Twisted異步網絡庫來處理網絡通訊。整體架構大致如下:

創建一個Scrapy項目
S-57格式是國際海事組織(IMO)頒布的電子海圖標準,本身是一種矢量海圖。這些標準都公布在http://www.s-57.com/上。以該網頁為抓取對象,進入存儲代碼的目錄中,運行下列命令,創建項目 crawls57:
scrapy startproject crawls57
該命令將會創建包含下列內容的?crawls57?目錄:
crawls57/scrapy.cfgcrawls57/__init__.pyitems.pypipelines.pysettings.pyspiders/__init__.py...
這些文件分別是:
scrapy.cfg: 項目的配置文件crawls57/: 該項目的python模塊。之后您將在此加入代碼。crawls57/items.py: 項目中的item文件.crawls57/pipelines.py: 項目中的pipelines文件.crawls57/settings.py: 項目的設置文件.crawls57/spiders/: 放置spider代碼的目錄.
定義Item
Item 是保存爬取到的數據的容器。在www.s-57.com的網頁上,數據分為左右兩部分,左邊是航標對象的信息,右邊是航標屬性的信息。右邊的數據較多,所以我們主要抓取左邊,即航標對象的一些數據:
import scrapyclass Crawls57Item(scrapy.Item):Object = scrapy.Field()Acronym = scrapy.Field()Code = scrapy.Field()Primitives = scrapy.Field()Attribute_A = scrapy.Field()Attribute_B = scrapy.Field()Attribute_C = scrapy.Field()Definition = scrapy.Field()References_INT = scrapy.Field()References_S4 = scrapy.Field()Remarks = scrapy.Field()Distinction = scrapy.Field()
編寫爬蟲
有了定義的Item,就可以編寫爬蟲Spider開始抓取數據。
可以直接通過命令行的方式,創建一個新的Spider:
scrapy genspider s-57 s-57.com
此時,在spiders文件夾里會生成一個 s-57.py 文件。下面我們則需要對該文件進行編輯。
根據網站s-57的結構,抓取的過程主要有兩步:
- 抓取航標對象的名稱、縮略號、ID等信息;
- 提取每一個航標對象的網頁地址,抓取它的詳細信息。
s-57.py?里默認有?parse() 方法,可以返回 Request 或者 items。每次運行爬蟲,?parse() 方法都會被調用。返回的?Request 對象接受一個參數 callback,指定?callback?為一個新的方法,就可以反復調用這個新的方法。所以,通過返回 Request 即可實現對網站的遞歸抓取。根據上述要求的抓取過程,可創建方法?parse_dir_contents() ,被?parse() 調用抓取航標對象的詳細信息,編輯代碼如下。
import scrapy from crawls57.items import Crawls57Item import reclass S57Spider(scrapy.Spider):name = "s-57"allowed_domains = ["s-57.com"]start_urls = ["http://www.s-57.com/titleO.htm",]data_code={}data_obj={}def parse(self, response):for obj in response.xpath('//select[@name="Title"]/option'):obj_name = obj.xpath('text()').extract()[0]obj_value = obj.xpath('@value').extract()[0]self.data_obj[obj_value] = obj_namefor acr in response.xpath('//select[@name="Acronym"]/option'):acr_name = acr.xpath('text()').extract()[0]acr_value = acr.xpath('@value').extract()[0]self.data_code[acr_name] = acr_valueurl = u'http://www.s-57.com/Object.asp?nameAcr='+acr_nameyield scrapy.Request(url, callback=self.parse_dir_contents)def parse_dir_contents(self, response):acr_name = response.url.split('=')[-1]acr_value = str(self.data_code[acr_name])obj_name = self.data_obj[acr_value]for sel in response.xpath('//html/body/dl'):item = Crawls57Item()item['Object'] = obj_nameitem['Acronym'] = acr_nameitem['Code'] = acr_valueitem['Primitives'] = sel.xpath('b/text()').extract()#Atrribute ABCatainfo = u''apath = sel.xpath('.//tr[1]/td[2]/b')for ata in apath.xpath('.//span'):atainfo += ata.re('>(\w+)<')[0]+"; "item['Attribute_A'] = atainfoatbinfo = u''bpath = sel.xpath('.//tr[2]/td[2]/b')for atb in bpath.xpath('.//span'):atbinfo += atb.re('>(\w+)<')[0]+"; "item['Attribute_B'] = atbinfoatcinfo = u''cpath = sel.xpath('.//tr[3]/td[2]/b')for atc in cpath.xpath('.//span'):atcinfo += atc.re('>(\w+)<')[0]+"; "item['Attribute_C'] = atcinfo#Descriptioni = 0for dec in sel.xpath('.//dl/dd'):i += 1dt = './/dl/dt[' + str(i) + ']/b/text()'dd = './/dl/dd[' + str(i) + ']/font/text()'if (sel.xpath(dt).extract()[0] == 'References'):item['References_INT'] = sel.xpath('.//tr[1]/td[2]/font/text()').extract()[0]item['References_S4'] = sel.xpath('.//tr[2]/td[2]/font/text()').extract()[0]if (len(sel.xpath(dd).extract()) == 0):continueif (sel.xpath(dt).extract()[0] == 'Definition'):ss = ''for defi in sel.xpath(dd).extract():ss += defiitem['Definition'] = ssif (sel.xpath(dt).extract()[0] == 'Remarks:'):item['Remarks'] = sel.xpath(dd).extract()[0]if (sel.xpath(dt).extract()[0] == 'Distinction:'):item['Distinction'] = sel.xpath(dd).extract()[0]yield item
相比正則表達式,用xpath抓取數據要方便許多。但是,用的時候還是免不了反復調試。Scrapy提供了一個shell環境用于調試response的命令,基本語法:
scrapy shell [url]
之后,就可以直接輸入response.xpath('...')調試抓取的數據。
爬取
進入項目的根目錄,執行下列命令啟動Spider:
scrapy crawl crawls57 -o data.json
最終,抓取的數據被存儲在?data.json 中。


![[转载]Web 研发模式演变](https://yqfile.alicdn.com/img_f2dc613df98e3cba17d5921c63cfa88d.jpeg)