暑假集訓主要是在杭電oj上面刷題,白天與算法作斗爭,晚上望干點自己喜歡的事情!
杭電oj2010、首先,確定要爬取哪些數據:
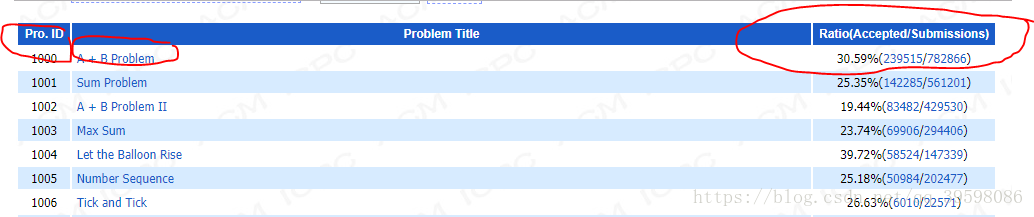
如上圖所示,題目ID,名稱,accepted,submissions,都很有用。
查看源代碼知:

所有的數據都在一個script標簽里面。
思路:用beautifulsoup找到這個標簽,然后用正則表達式提取。
話不多說,上數據爬取的代碼:
import requests
from bs4 import BeautifulSoup
import time
import random
import re
from requests.exceptions import RequestExceptionprbm_id = []
prbm_name = []
prbm_ac = []
prbm_sub = []def get_html(url): # 獲取htmltry:kv = {'user-agent': 'Mozilla/5.0'}r = requests.get(url, timeout=5, headers=kv)r.raise_for_status()r.encoding = r.apparent_encodingrandom_time = random.randint(1, 3)time.sleep(random_time) # 應對反爬蟲,隨機休眠1至3秒return r.textexcept RequestException as e: # 異常輸出print(e)return ""def get_hdu():count = 0for i in range(1, 56):url = "http://acm.hdu.edu.cn/listproblem.php?vol=" + str(i)# print(url)html = get_html(url)# print(html)soup = BeautifulSoup(html, "html.parser")cnt = 1for it in soup.find_all("script"):if cnt == 5:# print(it.get_text())str1 = it.stringlist_pro = re.split("p\(|\);", str1) # 去除 p(); 分割# print(list_pro)for its in list_pro:if its != "":# print(its)temp = re.split(',', its)len1 = len(temp)prbm_id.append(temp[1])prbm_name.append(temp[3])prbm_ac.append(temp[len1-2])prbm_sub.append(temp[len1-1])cnt = cnt + 1count = count + 1print('\r當前進度:{:.2f}%'.format(count * 100 / 55, end='')) # 進度條def main():get_hdu()root = "F://爬取的資源//hdu題目數據爬取2.txt"len1 = len(prbm_id)for i in range(0, len1):with open(root, 'a', encoding='utf-8') as f: # 存儲個人網址f.write("hdu"+prbm_id[i] + "," + prbm_name[i] + "," + prbm_ac[i] + "," + prbm_sub[i] + '\n')# print(prbm_id[i])if __name__ == '__main__':main()
爬取數據之后,想到用詞云生成圖片,來達到數據可視化。
本人能力有限,僅根據AC的數量進行分類,生成不同的詞云圖片。數據分析代碼如下:
import re
import wordcloud
from scipy.misc import imread # 這是一個處理圖像的函數
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
import osprbm_id = []
prbm_name = []
prbm_ac = []
prbm_sub = []def read():f = open(r"F://爬取的資源//hdu題目數據爬取2.txt", "r", encoding="utf-8")list_str = f.readlines()for it in list_str:list_pre = re.split(",", it)prbm_id.append(list_pre[0].strip('\n'))prbm_name.append(list_pre[1].strip('\n'))prbm_ac.append(list_pre[2].strip('\n'))prbm_sub.append(list_pre[3].strip('\n'))def data_Process():for it in range(0, len(prbm_ac)):# print(prbm_sub[it])root = "F://爬取的資源//詞語統計.txt"num1 = int(prbm_ac[it])# num2 = int(prbm_ac[it])*1.0/int(prbm_sub[it])if 5000 <= num1 <= 10000: # 分類with open(root, 'a', encoding='utf-8') as f: # 寫入txt文件,用于wordcloud詞云生成for i in range(0, int(num1/100)): # num1/100,這里可根據num1,除數變化f.write(prbm_id[it] + ' ')def main():read()data_Process()text = open(r"F://爬取的資源//詞語統計.txt", "r", encoding='utf-8').read()# 生成一個詞云圖像back_color = imread('F://爬取的資源//acm.jpg') # 解析該圖片w = wordcloud.WordCloud(background_color='white', # 背景顏色mask=back_color, # 以該參數值作圖繪制詞云,這個參數不為空時,width和height會被忽略width=300,height =100,collocations=False # 去掉重復元素)w.generate(text)plt.imshow(w)plt.axis("off")plt.show()os.remove("F://爬取的資源//詞語統計.txt")w.to_file("F://爬取的資源//hdu熱度詞云5.png")if __name__ == '__main__':main()
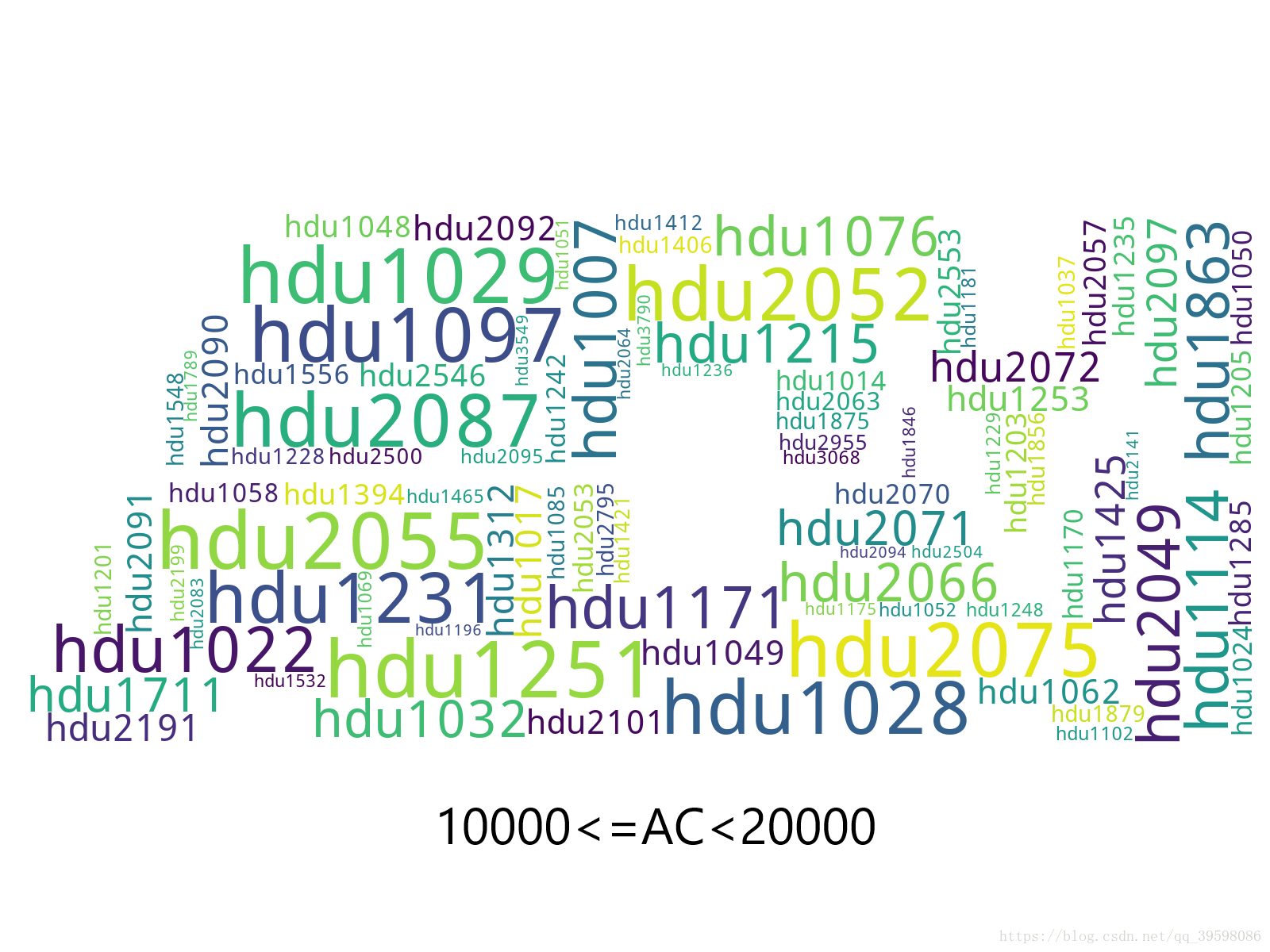
生成的圖片效果展示如下:

? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?

? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?

?

詞云是根據每個分類里面,ac的數量生成的。
僅以此,向廣大在杭電上刷題的苦逼acmer們,表達此刻心中的敬意。愿每位acmer都能勇往直前,披荊斬棘。
?