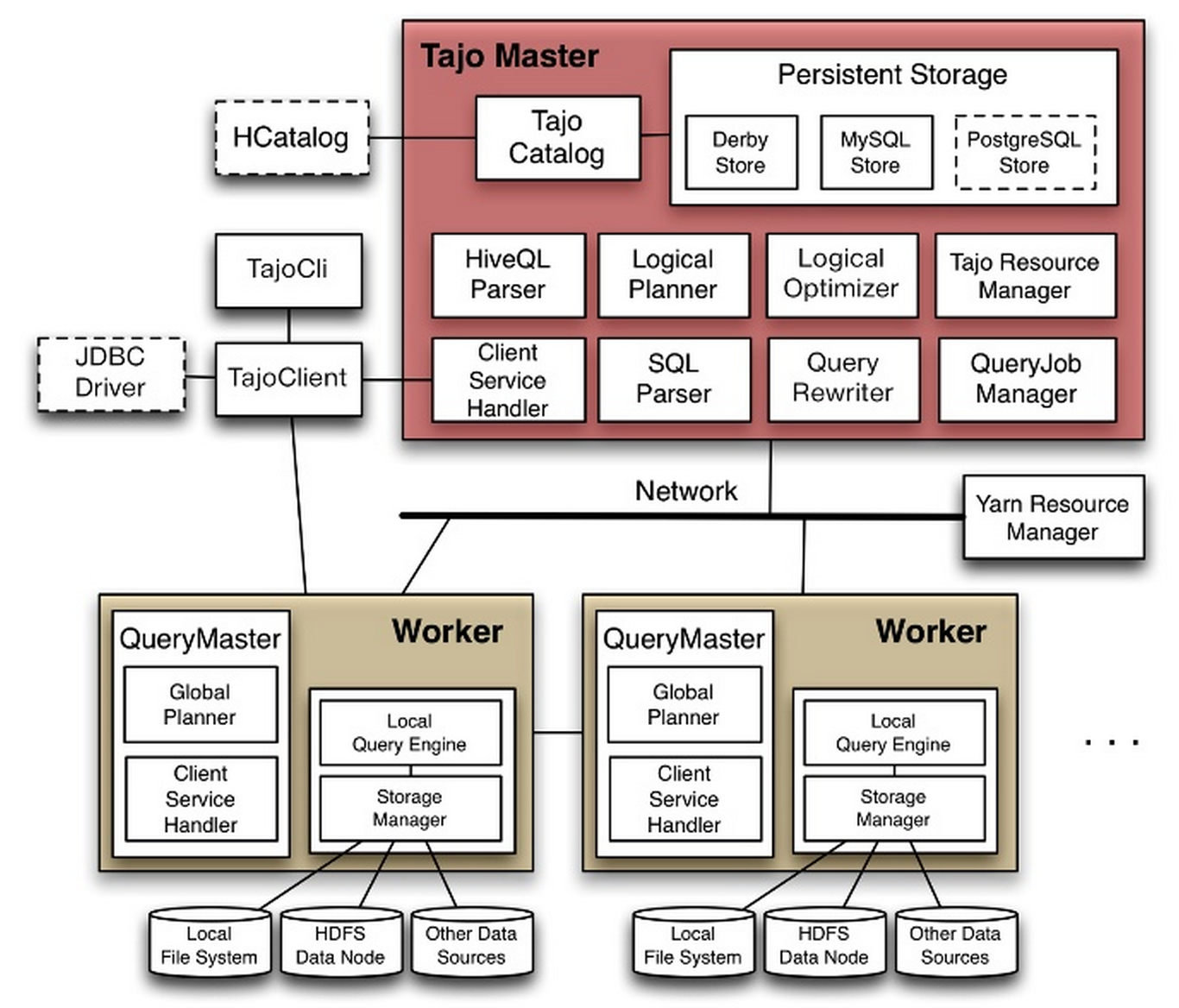
最近為了獲取網頁數據,積累了一些經驗,這里記錄 一下。網頁內容獲取用python真的是很好用,編寫代碼也快,偶爾有一些Bug需要調一下。這里記錄一下常用的包
bs4-----網頁內容解析,還有一個好用的:xpath
requests----請求下載網頁內容,一般和bs4配合使用
webbroswer---打開一個網頁,可以選擇指定瀏覽器,不可以下載網頁內容。python從網頁中提取數據、
selenium---模擬網頁操作,點擊,滾動網頁等,基本和人為操作差不多。還可以截圖。
有了這些工具,就可以自動化實現網頁內容獲取。pkgj無法獲取列表、但是有些網頁做得比較扎實,很難獲取里面的內容,比如有些僅支持網頁顯示,不支持獲取下載,怎么辦。
思路:使用網頁截圖工具,將接下來的圖保存起來,然后從圖片中提取文字,提取文字。
pytesseract----從圖片提取文字
好了,今天就記錄到這里,謝謝您的瀏覽關注!!!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态