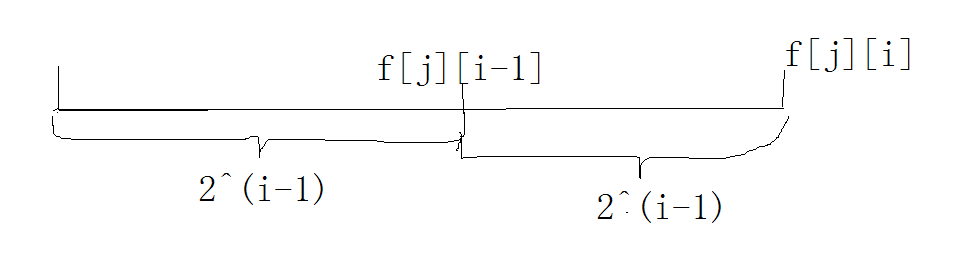
@(工具使用)[工具使用, python]
OCR即圖片上文字識別
github地址
tesseract是一個命令行程序,后面安裝的pytesseract也只是一層包裝,實際還是調用命令行
下載
windows版下載地址
安裝
下載完之后安裝時點下一步慢點,因為安裝的時候可以下載中文語言包

設置環境變量
安裝完之后需要設置兩個環境變量
TESSDATA_PREFIX=D:\Program Files (x86)\Tesseract-OCR\tessdata這時命令行版tesseract就可以使用了
pip install pytesseract
測試程序:
import pytesseract
from PIL import Image# 默認英語
image = Image.open('en.png')
text = pytesseract.image_to_string(image)
print(text)print("====================")# 識別中文, 巨慢
image = Image.open('cn.png')
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)print("====================")# 設置中文和英語,識別巨慢,而且易錯
image = Image.open('en_cn_test.png')
text = pytesseract.image_to_string(image, lang='chi_sim+eng')
print(text)
測試結果:
英文測試

識別后內容

中文測試

識別后內容

中文加英文測試

識別后內容

測試結論:
英文識別能力還行,速度也不錯,很快。中文識別就很吃力了,速度慢而且識別率不高,幾乎不能直接用
參考:
Python--文字識別--Tesseract
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态