160.說說數據類型之間的轉換:
JAVA 面試題?1 ) 如何將字符串轉換為基本數據類型?
2 ) 如何將基本數據類型轉換為字符串?
答:1 ) 調用基本數據類型對應的包裝類中的方法parseXXX(String)或valueOf(String)即可返回相應基本類型;
java面試老是面試不上?2 ) 一種方法是將基本數據類型與空字符串(””)連接(+)即可獲得其所對應的字符串;另一種方法是調用String 類中的valueOf(…)方法返回相應字符串
161.如何實現字符串的反轉及替換?
答:方法很多,可以自己寫實現也可以使用String或StringBuffer / StringBuilder中的方法。有一道很常見的面試題是用遞歸實現字符串反轉,代碼如下所示:
前端 java、162.怎樣將GB2312編碼的字符串轉換為ISO-8859-1編碼的字符串?
答:代碼如下所示:
String s1 = "你好";
java 面試。String s2 = newString(s1.getBytes("GB2312"), "ISO-8859-1");
163.Java中的日期和時間:
1 ) 如何取得年月日、小時分鐘秒?
java.lang。2 ) 如何取得從1970年1月1日0時0分0秒到現在的毫秒數?
3 ) 如何取得某月的最后一天?
4 ) 如何格式化日期?
java面試問題、答:操作方法如下所示:
1 ) 創建java.util.Calendar 實例,調用其get()方法傳入不同的參數即可獲得參數所對應的值
2 ) 以下方法均可獲得該毫秒數:
java,Calendar.getInstance().getTimeInMillis();
time.getActualMaximum(Calendar.DAY_OF_MONTH);
4 ) 利用java.text.DataFormat 的子類(如SimpleDateFormat類)中的format(Date)方法可將日期格式化。
164.打印昨天的當前時刻。

165.Java反射技術主要實現類有哪些,作用分別是什么?
在JDK中,主要由以下類來實現Java反射機制,這些類都位于java.lang.reflect包中
1)Class類:代表一個類
2)Field 類:代表類的成員變量(屬性)
3)Method類:代表類的成員方法
4)Constructor 類:代表類的構造方法
5)Array類:提供了動態創建數組,以及訪問數組的元素的靜態方法
166.Class類的作用?生成Class對象的方法有哪些?
Class類是Java 反射機制的起源和入口,用于獲取與類相關的各種信息,提供了獲取類信息的相關方法。Class類繼承自Object類
Class類是所有類的共同的圖紙。每個類有自己的對象,好比圖紙和實物的關系;每個類也可看做是一個對象,有共同的圖紙Class,存放類的 結構信息,能夠通過相應方法取出相應信息:類的名字、屬性、方法、構造方法、父類和接口
示 例
對象名
.getClass()
String str="bdqn";
Class clazz = str.getClass();
對象名
.getSuperClass()
Student stu = new Student();
Class c1 = stu.getClass();
Class c2 = stu.getSuperClass();
Class.forName()
Class clazz = Class.forName("java.lang.Object");
Class.forName("oracle.jdbc.driver.OracleDriver");
類名.class
類名.class
Class c2 = Student.class;
Class c2 = int.class
包裝類.TYPE
包裝類.TYPE
Class c2 = Boolean.TYPE;
167.反射的使用場合和作用、及其優缺點
1)使用場合
在編譯時根本無法知道該對象或類可能屬于哪些類,程序只依靠運行時信息來發現該對象和類的真實信息。
2)主要作用
通過反射可以使程序代碼訪問裝載到JVM 中的類的內部信息,獲取已裝載類的屬性信息,獲取已裝載類的方法,獲取已裝載類的構造方法信息
3)反射的優點
反射提高了Java程序的靈活性和擴展性,降低耦合性,提高自適應能力。它允許程序創建和控制任何類的對象,無需提前硬編碼目標類;反射是其它一些常用語言,如C、C++、Fortran 或者Pascal等都不具備的
4) Java反射技術應用領域很廣,如軟件測試等;許多流行的開源框架例如Struts、Hibernate、Spring在實現過程中都采用了該技術
5)反射的缺點
性能問題:使用反射基本上是一種解釋操作,用于字段和方法接入時要遠慢于直接代碼。因此Java反射機制主要應用在對靈活性和擴展性要求很高的系統框架上,普通程序不建議使用。
使用反射會模糊程序內部邏輯:程序人員希望在源代碼中看到程序的邏輯,反射等繞過了源代碼的技術,因而會帶來維護問題。反射代碼比相應的直接代碼更復雜。
168.面向對象設計原則有哪些
面向對象設計原則是面向對象設計的基石,面向對象設計質量的依據和保障,設計模式是面向對象設計原則的經典應用
1)單一職責原則SRP
2)開閉原則OCP
3)里氏替代原則LSP
4)依賴注入原則DIP
5)接口分離原則ISP
6)迪米特原則LOD
7)組合/聚合復用原則CARP
8)開閉原則具有理想主義的色彩,它是面向對象設計的終極目標。其他設計原則都可以看作是開閉原則的實現手段或方法

169.下面程序的運行結果是()(選擇一項)

A.true
B.false
C.hello
D.he
答案:B
分析:str1沒有使用new關鍵字,在堆中沒有開辟空間,其值”hello”在常量池中,str2使用new關鍵字創建了一個對象,在堆中開辟了空間,”==”比較的是對象的引用,即內存地址,所以str1與str2兩個對象的內存地址是不相同的
170.Java語言中,String類中的indexOf()方法返回值的類型是()
A.int16
B.int32
http://C.int
D.long
答案:C
171.給定以下代碼,程序的運行結果是 ()(選擇一項)
A.goodandabcB.goodandgbcC.test okandabcD.test okandgbc
答案:B
分析:在方法調用時,在change方法中對str的值進行修改,是將str指向了常量江池中的”test ok”,而主方法中的ex.str仍然指向的是常量池中的”good”。字符型數組在方法調用時,將主方法中ex.ch的引用傳遞給change方法中的ch,指向是堆中的同一堆空間,所以修改ch[0]的時候,ex.ch可以看到相同的修改后的結果。
172.執行下列代碼后,哪個結論是正確的()(選擇兩項)

A.s[10]為””
B.s[9]為null
C.s[0]為未定義
D.s.length為10
答案:BD
分析: 引用數據類型的默認值均為null
s.length數組的長度
173.實現String類的replaceAll方法
思路說明:replaceAll方法的本質是使用正則表達式進行匹配,最終調用的其實是Matcher對象的replaceAll方法。

174.在“=”后填寫適當的內容:
String []a=new String[10];
則:a[0]~a[9]=null;
a.length=10;
如果是int[]a=new int[10];
則:a[0]~a[9]= (0)
a.length= (10)
175.是否可以繼承String類?
答:不可以,因為String類有final修飾符,而final修飾的類是不能被繼承的,實現細節不允許改變。
public final class String implements java.io.Serializable,
Comparable< String>, CharSequence
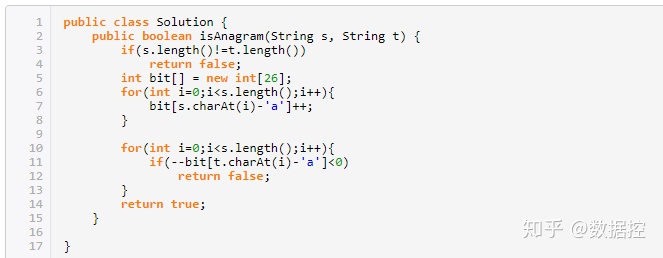
176.給定兩個字符串s和t, 寫一個函數來決定是否t是s的重組詞。你可以假設字符串只包含小寫字母。
177.String s=new String(“abc”);創建了幾個String對象。
兩個或一個,”abc”對應一個對象,這個對象放在字符串常量緩沖區,常量”abc”不管出現多少遍,都是緩沖區中的那一個。New String每寫一遍,就創建一個新的對象,它一句那個常量”abc”對象的內容來創建出一個新String對象。如果以前就用過’abc’,這句代表就不會創建”abc”自己了,直接從緩沖區拿。
178.輸出結果?

179.下列程序的輸出結果是什么?
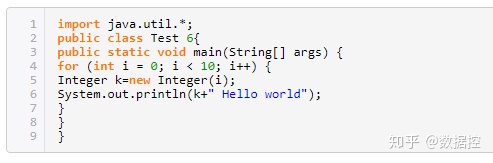
0 Hello world
1 Hello world
2 Hello world
3 Hello world
4 Hello world
5 Hello world
6 Hello world
7 Hello world
8 Hello world
9 Hello world
180.關于java.lang.String類,以下描述正確的一項是()
A.String類是final類故不可繼承
B.String類final類故可以繼承
C.String類不是final類故不可繼承
D.String;類不是final類故可以繼承
答案:A
181.下面哪個是正確的()
A.String temp[ ] = new String{“a”,”b”,”c”};
B.String temp[ ] = {“a”,”b”,”c”};
C.String temp= {“a”,”b”,”c”};
D.String[ ] temp = {“a”,”b”,”c”};
答案:BD
182.已知如下代碼:執行結果是什么()
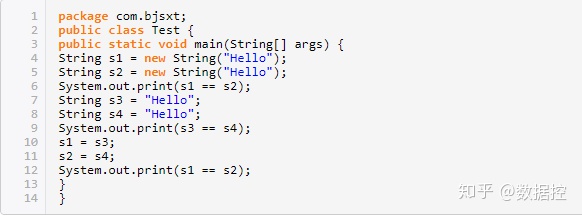
A.false true true
B.true false true
C.true true false
D.true true false
答案:A
183.字符串如何轉換為int類型

184.寫一個方法,實現字符串的反轉,如:輸入abc,輸出cba

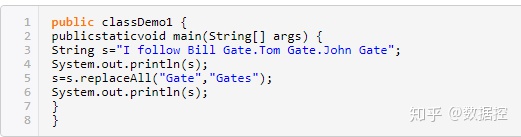
185.編寫java,將“I follow Bill Gate.Tom Gate.John Gate”中的“Gate”全部替換為“Gates”
186.String 是最基本的數據類型嗎?
答: 不是 。Java中的基本數據類型只有8個:byte、short、int、long、float、double、char、boolean;除了基本類型(primitive type)和枚舉類型(enumeration type),剩下的都是引用類型(reference type)。
187.String 和StringBuilder、StringBuffer 的區別?
答: Java 平臺提供了兩種類型的字符串:String和StringBuffer / StringBuilder
相同點:
它們都可以儲存和操作字符串,同時三者都使用final修飾,都屬于終結類不能派生子類,操作的相關方法也類似例如獲取字符串長度等;
不同點:
其中String是只讀字符串,也就意味著String引用的字符串內容是不能被改變的,而StringBuffer和StringBuilder類表示的字符串對象可以直接進行修改,在修改的同時地址值不會發生改變。StringBuilder是JDK 1.5中引入的,它和StringBuffer的方法完全相同,區別在于它是在單線程環境下使用的,因為它的所有方面都沒有被synchronized修飾,因此它的效率也比StringBuffer略高。在此重點說明一下,String、StringBuffer、StringBuilder三者類型不一樣,無法使用equals()方法比較其字符串內容是否一樣!
補充1:有一個面試題問:有沒有哪種情況用+做字符串連接比調用StringBuffer / StringBuilder對象的append方法性能更好?如果連接后得到的字符串在靜態存儲區中是早已存在的,那么用+做字符串連接是優于StringBuffer / StringBuilder的append方法的。
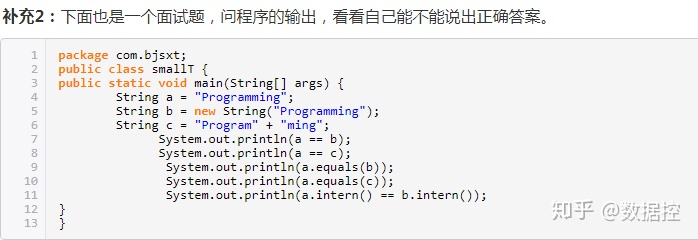
解析:
String類存在intern()方法,含義如下:返回字符串對象的規范化表示形式。它遵循以下規則:對于任意兩個字符串 s 和 t,當且僅當 s.equals(t) 為 true 時,s.intern() == t.intern() 才為 true。
字符串比較分為兩種形式,一種使用比較運算符”==”比較,他們比較的是各自的字符串在內存當中的地址值是否相同;一種是使用equals()方法進行比較,比較的是兩個字符串的內容是否相同!
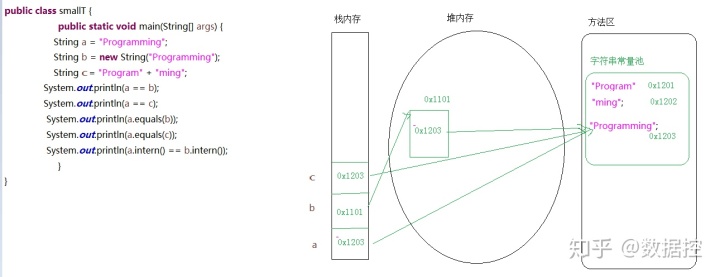
結果如下:
a == b-->false
a == c-->true
a.equals(b)-->true
a.equals(c)-->true
a.intern() == b.intern()-->true
188.String類為什么是final的
答:1) 為了效率。若允許被繼承,則其高度的被使用率可能會降低程序的性能。
2)為了安全。JDK中提供的好多核心類比如String,這類的類的內部好多方法的實現都不是java編程語言本身編寫的,好多方法都是調用的操作系統本地的API,這就是著名的“本地方法調用”,也只有這樣才能做事,這種類是非常底層的,和操作系統交流頻繁的,那么如果這種類可以被繼承的話,如果我們再把它的方法重寫了,往操作系統內部寫入一段具有惡意攻擊性質的代碼什么的,這不就成了核心病毒了么?不希望別人改,這個類就像一個工具一樣,類的提供者給我們提供了, 就希望我們直接用就完了,不想讓我們隨便能改,其實說白了還是安全性,如果隨便能改了,那么java編寫的程序肯定就很不穩定,你可以保證自己不亂改, 但是將來一個項目好多人來做,管不了別人,再說有時候萬一疏忽了呢?他也不是估計的, 所以這個安全性是很重要的,java和C++相比,優點之一就包括這一點。
189.String類型是基本數據類型嗎?基本數據類型有哪些
1) 基本數據類型包括byte、short/char、int、long、float、double、boolean
2 ) java.lang.String類是引用數據類型,并且是final類型的,因此不可以繼承這個類、不能修改這個類。為了提高效率節省空間,我們應該用StringBuffer類
190.String s="Hello";s=s+"world!";執行后,是否是對前面s指向空間內容的修改?
答:不是對前面s指向空間內容的直接修改。
因為String被設計成不可變(immutable)類,所以它的所有對象都是不可變對象。在這段代碼中,s原先指向一個String對象,內容是 "Hello",然后我們對s進行了+操作,那么s所指向的那個對象是否發生了改變呢?答案是沒有。這時,s不指向原來那個對象了,而指向了另一個 String對象,內容為"Hello world!",原來那個對象還存在于內存之中,只是s這個引用變量不再指向它了。
通過上面的說明,我們很容易導出另一個結論,如果經常對字符串進行各種各樣的修改,或者說,不可預見的修改,那么使用String來代表字符串的話會引起很大的內存開銷。因為 String對象建立之后不能再改變,所以對于每一個不同的字符串,都需要一個String對象來表示。這時,應該考慮使用StringBuffer類,它允許修改,而不是每個不同的字符串都要生成一個新的對象。并且,這兩種類的對象轉換十分容易。
同時,我們還可以知道,如果要使用內容相同的字符串,不必每次都new一個String。例如我們要在構造器中對一個名叫s的String引用變量進行初始化,把它設置為初始值,應當這樣做:
而非
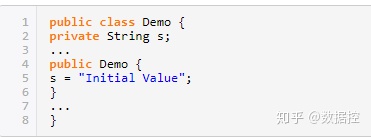
s = new String("Initial Value");
后者每次都會調用構造器,生成新對象,性能低下且內存開銷大,并且沒有意義,因為String對象不可改變,所以對于內容相同的字符串,只要一個String對象來表示就可以了。也就說,多次調用上面的構造器創建多個對象,他們的String類型屬性s都指向同一個對象。
上面的結論還基于這樣一個事實:對于字符串常量,如果內容相同,Java認為它們代表同一個String對象。而用關鍵字new調用構造器,總是會創建一個新的對象,無論內容是否相同。
至于為什么要把String類設計成不可變類,是它的用途決定的。其實不只String,很多Java標準類庫中的類都是不可變的。在開發一個系統的時候,我們有時候也需要設計不可變類,來傳遞一組相關的值,這也是面向對象思想的體現。不可變類有一些優點,比如因為它的對象是只讀的,所以多線程并發訪問也不會有任何問題。當然也有一些缺點,比如每個不同的狀態都要一個對象來代表,可能會造成性能上的問題。所以Java標準類庫還提供了一個可變版本,即 StringBuffer。
191.String s = new String("xyz");創建幾個String Object?
答:兩個或一個,”xyz”對應一個對象,這個對象放在字符串常量緩沖區,常量”xyz”不管出現多少遍,都是緩沖區中的那一個。New String每寫一遍,就創建一個新的對象,它一句那個常量”xyz”對象的內容來創建出一個新String對象。如果以前就用過’xyz’,這句代表就不會創建”xyz”自己了,直接從緩沖區拿。
192.下面這條語句一共創建了多少個對象:String s="a"+"b"+"c"+"d";
答:對于如下代碼:
String s1 = "a";
String s2 = s1 + "b";
String s3 = "a" + "b";
System.out.println(s2 == "ab");
System.out.println(s3 == "ab");
第一條語句打印的結果為false,第二條語句打印的結果為true,這說明javac編譯可以對字符串常量直接相加的表達式進行優化,不必要等到運行期去進行加法運算處理,而是在編譯時去掉其中的加號,直接將其編譯成一個這些常量相連的結果。
題目中的第一行代碼被編譯器在編譯時優化后,相當于直接定義一個”abcd”的字符串,所以,上面的代碼應該只創建了一個String對象。
寫如下兩行代碼,
String s = "a" + "b" + "c" + "d";
System.out.println(s == "abcd");
最終打印的結果應該為true。
193.Java集合體系結構(List、Set、Collection、Map的區別和聯系)
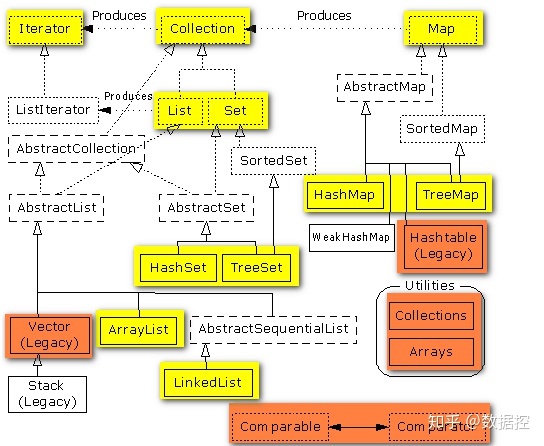
1、Collection 接口存儲一組不唯一,無序的對象
2、List 接口存儲一組不唯一,有序(插入順序)的對象
3、Set 接口存儲一組唯一,無序的對象
4、Map接口存儲一組鍵值對象,提供key到value的映射。Key無序,唯一。value不要求有序,允許重復。(如果只使用key存儲,而不使用value,那就是Set)
194.Vector和ArrayList的區別和聯系
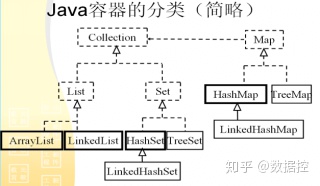
相同點:
1)實現原理相同---底層都使用數組
2)功能相同---實現增刪改查等操作的方法相似
3)都是長度可變的數組結構,很多情況下可以互用
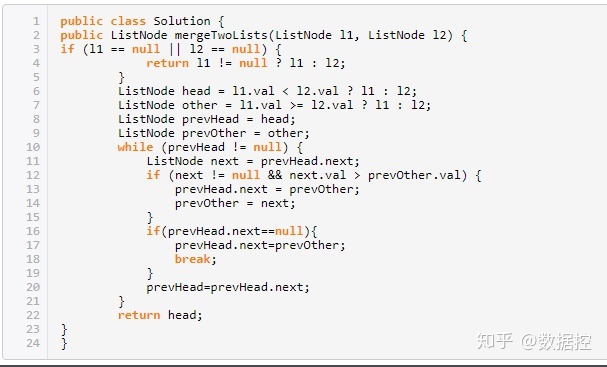
不同點:
1)Vector是早期JDK版本提供,ArrayList是新版本替代Vector的
2)Vector線程安全,ArrayList重速度輕安全,線程非安全長度需增長時,Vector默認增長一倍,ArrayList增長50%
195.ArrayList和LinkedList的區別和聯系
相同點:
兩者都實現了List接口,都具有List中元素有序、不唯一的特點。
不同點:
ArrayList實現了長度可變的數組,在內存中分配連續空間。遍歷元素和隨機訪問元素的效率比較高;
LinkedList采用鏈表存儲方式。插入、刪除元素時效率比較高

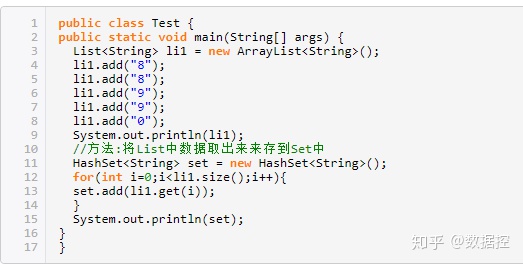
196.HashMap和Hashtable的區別和聯系
相同點:
實現原理相同,功能相同,底層都是哈希表結構,查詢速度快,在很多情況下可以互用
不同點:
1、Hashtable是早期提供的接口,HashMap是新版JDK提供的接口
2、Hashtable繼承Dictionary類,HashMap實現Map接口
3、Hashtable線程安全,HashMap線程非安全
4、Hashtable不允許null值,HashMap允許null值
197.HashSet的使用和原理(hashCode()和equals())
1)哈希表的查詢速度特別快,時間復雜度為O(1)。
2)HashMap、Hashtable、HashSet這些集合采用的是哈希表結構,需要用到hashCode哈希碼,hashCode是一個整數值。
3)系統類已經覆蓋了hashCode方法 自定義類如果要放入hash類集合,必須重寫hashcode。如果不重寫,調用的是Object的hashcode,而Object的hashCode實際上是地址。
4)向哈希表中添加數據的原理:當向集合Set中增加對象時,首先集合計算要增加對象的hashCode碼,根據該值來得到一個位置用來存放當前對象,如在該位置沒有一個對象存在的話,那么集合Set認為該對象在集合中不存在,直接增加進去。如果在該位置有一個對象存在的話,接著將準備增加到集合中的對象與該位置上的對象進行equals方法比較,如果該equals方法返回false,那么集合認為集合中不存在該對象,在進行一次散列,將該對象放到散列后計算出的新地址里。如果equals方法返回true,那么集合認為集合中已經存在該對象了,不會再將該對象增加到集合中了。
5)在哈希表中判斷兩個元素是否重復要使用到hashCode()和equals()。hashCode決定數據在表中的存儲位置,而equals判斷是否存在相同數據。
6) Y=K(X) :K是函數,X是哈希碼,Y是地址
198.TreeSet的原理和使用(Comparable和comparator)
1)TreeSet集合,元素不允許重復且有序(自然順序)
2)TreeSet采用樹結構存儲數據,存入元素時需要和樹中元素進行對比,需要指定比較策略。
3)可以通過Comparable(外部比較器)和Comparator(內部比較器)來指定比較策略,實現了Comparable的系統類可以順利存入TreeSet。自定義類可以實現Comparable接口來指定比較策略。
4)可創建Comparator接口實現類來指定比較策略,并通過TreeSet構造方法參數傳入。這種方式尤其對系統類非常適用。
199.集合和數組的比較(為什么引入集合)
數組不是面向對象的,存在明顯的缺陷,集合完全彌補了數組的一些缺點,比數組更靈活更實用,可大大提高軟件的開發效率而且不同的集合框架類可適用于不同場合。具體如下:
1)數組的效率高于集合類.
2)數組能存放基本數據類型和對象,而集合類中只能放對象。
3)數組容量固定且無法動態改變,集合類容量動態改變。
4)數組無法判斷其中實際存有多少元素,length只告訴了array的容量。
5)集合有多種實現方式和不同的適用場合,而不像數組僅采用順序表方式。
6)集合以類的形式存在,具有封裝、繼承、多態等類的特性,通過簡單的方法和屬性調用即可實現各種復雜操作,大大提高軟件的開發效率。
200.Collection和Collections的區別
1)Collection是Java提供的集合接口,存儲一組不唯一,無序的對象。它有兩個子接口List和Set。
2)Java中還有一個Collections類,專門用來操作集合類 ,它提供一系列靜態方法實現對各種集合的搜索、排序、線程安全化等操作。
201.下列說法正確的有()(選擇一項)
A.LinkedList繼承自List
B.AbstractSet繼承自Set
C.HashSet繼承自AbstractSet
D.TreeMap繼承自HashMap
答案: C
分析:A:LinkedList實現List接口
B:AbstractSet實現Set接口
D:TreeMap繼承AbstractMap
202.Java的HashMap和Hashtable有什么區別HashSet和HashMap有什么區別?使用這些結構保存的數需要重載的方法是哪些?
答:HashMap與Hashtable實現原理相同,功能相同,底層都是哈希表結構,查詢速度快,在很多情況下可以互用
兩者的主要區別如下
1、Hashtable是早期JDK提供的接口,HashMap是新版JDK提供的接口
2、Hashtable繼承Dictionary類,HashMap實現Map接口
3、Hashtable線程安全,HashMap線程非安全
4、Hashtable不允許null值,HashMap允許null值
HashSet與HashMap的區別
1、HashSet底層是采用HashMap實現的。HashSet 的實現比較簡單,HashSet 的絕大部分方法都是通過調用 HashMap 的方法來實現的,因此 HashSet 和 HashMap 兩個集合在實現本質上是相同的。
2、HashMap的key就是放進HashSet中對象,value是Object類型的。
3、當調用HashSet的add方法時,實際上是向HashMap中增加了一行(key-value對),該行的key就是向HashSet增加的那個對象,該行的value就是一個Object類型的常量
203.列出Java中的集合類層次結構?
答:Java中集合主要分為兩種:Collection和Map。Collection是List和Set接口的父接口;ArrayList和LinkedList是List的實現類;HashSet和TreeSet是Set的實現類;LinkedHashSet是HashSet的子類。HashMap和TreeMap是Map的實現類;LinkedHashMap是HashMap的子類。
圖中:虛線框中為接口,實線框中為類。
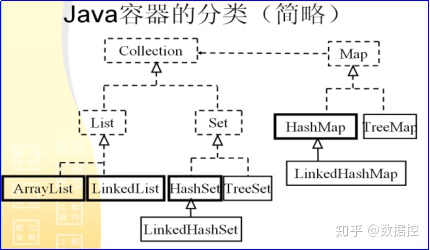
204.List,Set,Map各有什么特點
答:List 接口存儲一組不唯一,有序(插入順序)的對象。
Set 接口存儲一組唯一,無序的對象。
Map接口存儲一組鍵值對象,提供key到value的映射。key無序,唯一。value不要求有序,允許重復。(如果只使用key存儲,而不使用value,那就是Set)。
205.ArrayList list=new ArrayList(20);中的list擴充幾次()
A.0
B.1
C.2
D.3
答案:A
分析:已經指定了長度, 所以不擴容
206.List、Set、Map哪個繼承自Collection接口,一下說法正確的是()
A.List Map
B.Set Map
C.List Set
D.List Map Set
答案:C
分析:Map接口繼承了java.lang.Object類,但沒有實現任何接口.
207.合并兩個有序的鏈表
208.用遞歸方式實現鏈表的轉置。

209.給定一個不包含相同元素的整數集合,nums,返回所有可能的子集集合。解答中集合不能包含重復的子集。

210.以下結構中,哪個具有同步功能()
A.HashMap
B.ConcurrentHashMap
C.WeakHashMap
D.TreeMap
答案:B
分析:
A,C,D都線程不安全,B線程安全,具有同步功能
211.以下結構中,插入性能最高的是()
A.ArrayList
B.Linkedlist
C.tor
D.Collection
答案:B
分析:
數組插入、刪除效率差,排除A
tor不是java里面的數據結構,是一種網絡路由技術;因此排除C
Collection 是集合的接口,不是某種數據結構;因此排除D
212.以下結構中,哪個最適合當作stack使用()
A.LinkedHashMap
B.LinkedHashSet
C.LinkedList
答案:C
分析:
Stack是先進后出的線性結構;所以鏈表比較合適;不需要散列表的數據結構
213.Map的實現類中,哪些是有序的,哪些是無序的,有序的是如何保證其有序性,你覺得哪個有序性性能更高,你有沒有更好或者更高效的實現方式?
答:1. Map的實現類有HashMap,LinkedHashMap,TreeMap
2. HashMap是有無序的,LinkedHashMap和TreeMap都是有序的(LinkedHashMap記錄了添加數據的順序;TreeMap默認是自然升序)
3. LinkedHashMap底層存儲結構是哈希表+鏈表,鏈表記錄了添加數據的順序
4. TreeMap底層存儲結構是二叉樹,二叉樹的中序遍歷保證了數據的有序性
5. LinkedHashMap有序性能比較高,因為底層數據存儲結構采用的哈希表
214.下面的代碼在絕大部分時間內都運行得很正常,請問什么情況下會出現問題?根源在哪里?

答:將if( list.size() <= 0 )改成:while( list.size() <= 0 )
215.TreeMap和TreeSet在排序時如何比較元素?Collections工具類中的sort()方法如何比較元素?
答:TreeSet要求存放的對象所屬的類必須實現Comparable接口,該接口提供了比較元素的compareTo()方法,當插入元素時會 回調該方法比較元素的大小。TreeMap要求存放的鍵值對映射的鍵必須實現Comparable接口從而根據鍵對元素進行排序。Collections 工具類的sort方法有兩種重載的形式,第一種要求傳入的待排序容器中存放的對象比較實現Comparable接口以實現元素的比較;第二種不強制性的要求容器中的元素必須可比較,但是要求傳入第二個參數,參數是Comparator接口的子類型(需要重寫compare方法實現元素的比較),相當于一個臨時定義的排序規則,其實就是是通過接口注入比較元素大小的算法,也是對回調模式的應用。
216.List里面如何剔除相同的對象?請簡單用代碼實現一種方法
217.Java.util.Map的實現類有
分析:Java中的java.util.Map的實現類
1、HashMap
2、Hashtable
3、LinkedHashMap
4、TreeMap
218.下列敘述中正確的是()
A.循環隊列有隊頭和隊尾兩個指針,因此,循環隊列是非線性結構
B.在循環隊列中,只需要隊頭指針就能反映隊列中元素的動態變化情況
C.在循環隊列中,只需要隊尾指針就能反映隊列中元素的動態變化情況
D.在循環隊列中元素的個數是由隊頭指針和隊尾指針共同決定的
答案:D
分析:循環隊列中元素的個數是由隊首指針和隊尾指針共同決定的,元素的動態變化也是通過隊首指針和隊尾指針來反映的,當隊首等于隊尾時,隊列為空。
219.List、Set、Map 是否繼承自Collection 接口?
答:List、Set 的父接口是Collection,Map 不是其子接口,而是與Collection接口是平行關系,互不包含。

Map是鍵值對映射容器,與List和Set有明顯的區別,而Set存儲的零散的元素且不允許有重復元素(數學中的集合也是如此),List是線性結構的容器,適用于按數值索引訪問元素的情形。
220.說出ArrayList、Vector、LinkedList 的存儲性能和特性?
答:ArrayList 和Vector都是使用數組方式存儲數據,此數組元素數大于實際存儲的數據以便增加和插入元素,它們都允許直接按序號索引元素,但是插入元素要涉及數組元素移動等內存操作,所以索引數據快而插入數據慢,Vector由于使用了synchronized 方法(線程安全),通常性能上較ArrayList 差,而LinkedList 使用雙向鏈表實現存儲(將內存中零散的內存單元通過附加的引用關聯起來,形成一個可以按序號索引的線性結構,這種鏈式存儲方式與數組的連續存儲方式相比,其實對內存的利用率更高),按序號索引數據需要進行前向或后向遍歷,但是插入數據時只需要記錄本項的前后項即可,所以插入速度較快。Vector屬于遺留容器(早期的JDK中使用的容器,除此之外Hashtable、Dictionary、BitSet、Stack、Properties都是遺留容器),現在已經不推薦使用,但是由于ArrayList和LinkedListed都是非線程安全的,如果需要多個線程操作同一個容器,那么可以通過工具類Collections中的synchronizedList方法將其轉換成線程安全的容器后再使用(這其實是裝潢模式最好的例子,將已有對象傳入另一個類的構造器中創建新的對象來增加新功能)。
補充:遺留容器中的Properties類和Stack類在設計上有嚴重的問題,Properties是一個鍵和值都是字符串的特殊的鍵值對映射,在設計上應該是關聯一個Hashtable并將其兩個泛型參數設置為String類型,但是Java API中的Properties直接繼承了Hashtable,這很明顯是對繼承的濫用。這里復用代碼的方式應該是HAS-A關系而不是IS-A關系,另一方面容器都屬于工具類,繼承工具類本身就是一個錯誤的做法,使用工具類最好的方式是HAS-A關系(關聯)或USE-A關系(依賴) 。同理,Stack類繼承Vector也是不正確的。
由于字數限制,后續內容更加精彩,歡迎關注,整理不易,可否動動你的小手給小編來點更新的動力,希望對你們會有幫助!~
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态