1.Writable簡單介紹
在前面的博客中,經常出現IntWritable,ByteWritable.....光從字面上,就可以看出,給人的感覺是基本數據類型 和 序列化!在Hadoop中自帶的org.apache.hadoop.io包中有廣泛的Writable類可供選擇。它們的層次結構如下圖所示:
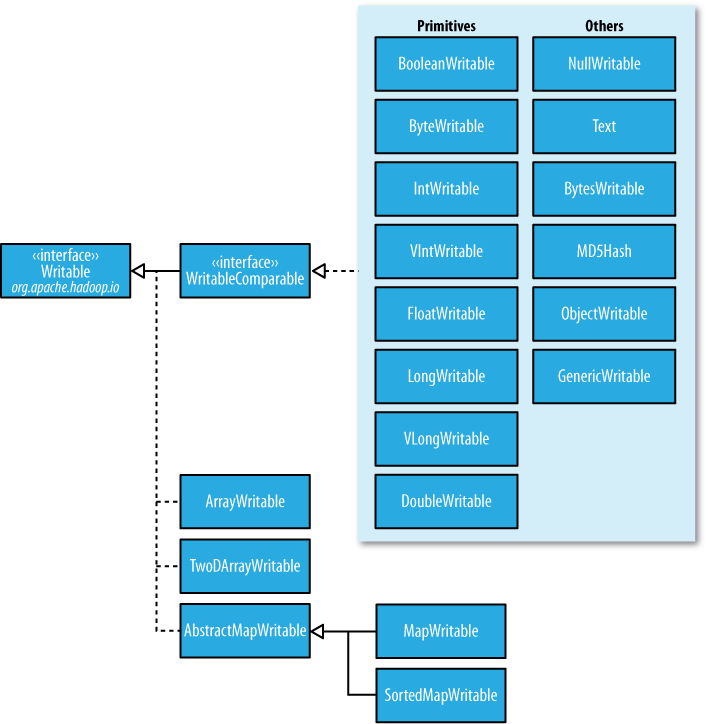
?
Writable類對Java基本類型提供封裝,short 和 char除外(可以存儲在IntWritable中)。所有的封裝包包含get()? 和 set() 方法用于讀取或者設置封裝的值。如下表所示,Java基本類型的Writable類:
?
| Java 基本數據類型 | Writable實現 | 序列化大小(字節) |
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
| int 類中可以定義類嗎。? | IntWritable VIntWritable | hadoop wordcount,4 1~5 |
| float | FloatWritable | 4 |
| long hadoop getmerge、? | LongWritable VLongWritable | hadoop put。8 1~9 |
| double | DoubleWritable | 8 |
?
2.IntWritable 和 VIntWritable
如上表所示,這兩個的區別,很明顯,序列化的大小,IntWriable是固定的4個字節,而VintWritable是1~5個字節,是可以變化的!這兩個分別在什么場合用?如果需要編碼的數值在-127~127之間,變長格式就只用一個字節進行編碼;否則,使用一個字節來表示數值的正負和后跟多少個字節。
相比與定長格式,變長格式有什么優點:
(1).定長格式適合對整個值域空間中分布均勻的數值進行編碼,大多數數值變量的分布都不均勻,而且變長格式 一般更節省空間。
(2).還有,就是變長格式的VIntWritable和VLlongWritable可以轉換,因為他們的編碼實際上一致!選擇變長格式,更有增長空間。
通過上面,可以知道,變長格式的范圍是1~5個字節,那么什么時候是5個字節,什么時候又是3個字節呢?
| 整數的范圍 | 序列化字節的大小(字節) |
| -127~127?? (-2^7? - 1? ~?? 2^7? -1 ) | 1 |
| -256(2的8次方)~ -128? 或者? 128~255?? | 2 |
| -65536(2的16次方)~ -257? 或者 256~65535 | 3 |
| -16777216(2的24次方) ~? -65537 ? 或者? 65536 ~ 16777215 | 4 |
| -2147483648(2的31次方) ~ -16777217 或者 16777216 ~ 2147483647 | 5 |
?
問題:
《Hadoop權威指南》上說,需要編碼的數值如果相當小(在-127和127之間,包括-127和127),變長格式就只用一個字節進行編碼!理論上,我也認為是正確的,但是,我用代碼測試了以下,發現-127~-113之間,占用的是2個字節。如下面的例子以及運行結果:
Example:
1 package cn.roboson.writable; 2 3 import java.io.ByteArrayInputStream; 4 import java.io.ByteArrayOutputStream; 5 import java.io.DataInputStream; 6 import java.io.DataOutputStream; 7 import java.io.IOException; 8 9 import org.apache.hadoop.io.IntWritable; 10 import org.apache.hadoop.io.VIntWritable; 11 import org.apache.hadoop.io.Writable; 12 /** 13 * 這個例子,主要是為了區分定長和變長,還有就是變長的范圍 14 * 1.先定義兩個IntWritable 15 * 2.分別序列化這兩個類 16 * 3.比較序列化后字節大小 17 * @author roboson 18 * 19 */ 20 21 public class IntWritableTest { 22 23 public static void main(String[] args) throws IOException { 24 25 //定義兩個比較小的IntWritable,序列化后1個字節的臨界點,《Hadoop權威指南》中所說的是-127~127,但是,我發現只能是-112~127 26 //超過-112后,就成為2個字節了 27 IntWritable writable = new IntWritable(127); 28 VIntWritable vwritable = new VIntWritable(-112); 29 show(writable,vwritable); 30 31 //驗證不是從-127~127 32 writable.set(-113); 33 vwritable.set(-113); 34 show(writable,vwritable); 35 36 //序列化后兩個字節大小的范圍 -256(2的8次方)~ -128 或者 128~255 37 writable.set(-256); 38 vwritable.set(-256); 39 show(writable,vwritable); 40 41 //序列化后3個字節大小的范圍 -65536(2的16次方)~ -257 或者 256~65535 42 writable.set(-65536); 43 vwritable.set(-65536); 44 show(writable,vwritable); 45 46 //序列化后4個字節大小的范圍 -16777216(2的24次方) ~ -65537 或者 65536 ~ 16777215 47 writable.set(-16777216); 48 vwritable.set(-16777216); 49 show(writable,vwritable); 50 51 //序列化后4個字節大小的范圍 -2147483648(2的31次方) ~ -16777217 或者 16777216 ~ 2147483647 52 writable.set(-2147483648); 53 vwritable.set(-2147483648); 54 show(writable,vwritable); 55 } 56 57 public static byte[] serizlize(Writable writable) throws IOException{ 58 59 //創建一個輸出字節流對象 60 ByteArrayOutputStream out = new ByteArrayOutputStream(); 61 DataOutputStream dataout = new DataOutputStream(out); 62 63 //將結構化數據的對象writable寫入到輸出字節流。 64 writable.write(dataout); 65 return out.toByteArray(); 66 } 67 68 public static byte[] deserizlize(Writable writable,byte[] bytes) throws IOException{ 69 70 //創建一個輸入字節流對象,將字節數組中的數據,寫入到輸入流中 71 ByteArrayInputStream in = new ByteArrayInputStream(bytes); 72 DataInputStream datain = new DataInputStream(in); 73 74 //將輸入流中的字節流數據反序列化 75 writable.readFields(datain); 76 return bytes; 77 78 } 79 80 public static void show(Writable writable,Writable vwritable) throws IOException{ 81 //對上面兩個進行序列化 82 byte[] writablebyte = serizlize(writable); 83 byte[] vwritablebyte = serizlize(vwritable); 84 85 //分別輸出字節大小 86 System.out.println("定長格式"+writable+"序列化后字節長大小:"+writablebyte.length ); 87 System.out.println("變長格式"+vwritable+"序列化后字節長大小:"+vwritablebyte.length ); 88 } 89 }
hadoop shuffle。?
運行結果:

?
先到這,后面的數據類型,下次繼續
?
hadoop hdfs。????






![[置顶]别羡慕别人的舒服,静下心来坚持奋斗!!!](/upload/rand_pic/2-119.jpg)





