本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
加企鹅群695185429即可免费获取,资料全在群文件里。资料可以领取包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等
在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片。
1、根据给定的网址获取网页源代码。
2、利用正则表达式把源代码中的图片地址过滤出来。
python函数调用。3、过滤出来的图片地址下载素材图片。
1、网址如下:
https://www.51miz.com/2、涉及的库:requests、lxml
首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示:
https://www.51miz.com/so-sucai/1789243.htmlhttps://www.51miz.com/so-sucai/1789243/p_2/https://www.51miz.com/so-sucai/1789243/p_3/我们可以发现图片页数是1789243/p{},p{}花括号数字表示图片哪一页。
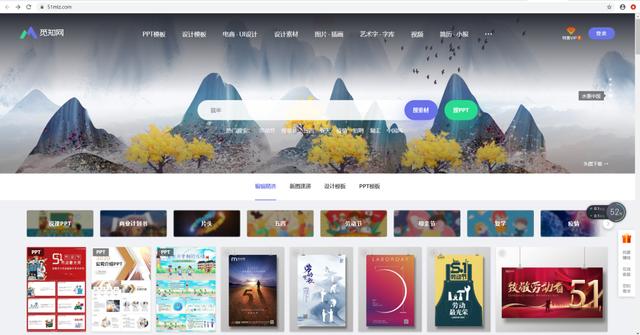
1、打开觅知网,在搜索中输入你想要的图片素材(以鼠年素材图片为例)。
一张图学会python?2、根据上一步对网址的分析,首先我们定义一个类叫做ImageSpider,类里面定义初始化函数、发送请求获取响应数据函数、解析函数、主函数。首先初始化函数,准备url地址和headers,代码如下图所示。

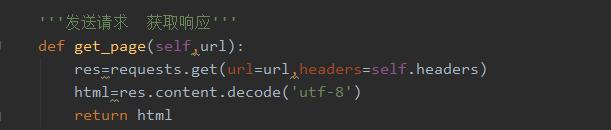
3、发送请求获取相应数据函数。
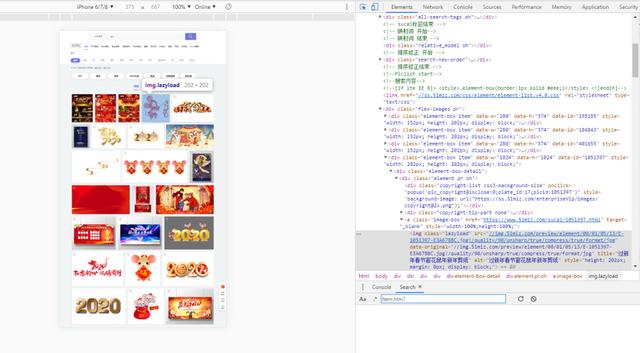
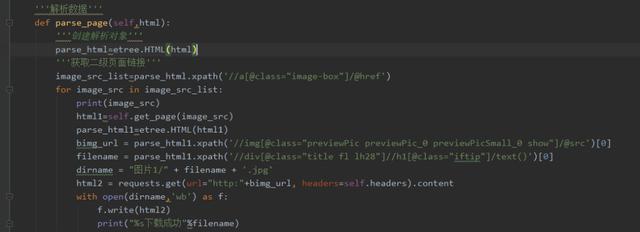
4、解析数据,使用xpath获取二级页面链接,最后把图片存储在文件夹中。使用谷歌浏览器选择开发者工具或直接按F12,发现我们需要的图片src是在img标签下的,于是用Python的requests提取该组件。
5、主函数,代码如下图所示。
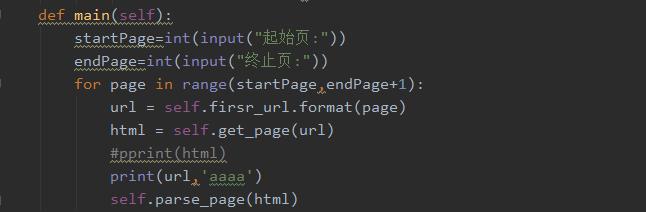
1、运行程序,在控制台输入你要爬取的页数,如下图所示。
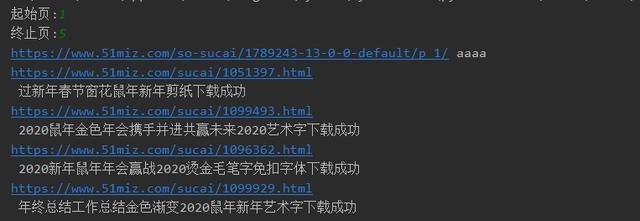
2、在本地可以看到效果图,如下图所示。

爬虫技术python、如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。获取方式,私信小编 “ 01 ”,即可免费获取哦!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











