hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言‘查询、汇总和分析数据。而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的1:具进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defnes AggregateFunction)和UDTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。
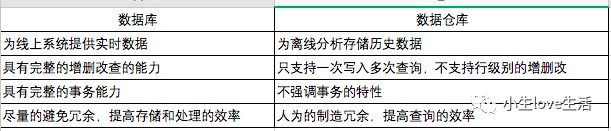
hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。hive的特点包括:可伸缩(在Hadoop的集群上动态添加设备)、可扩展、容错、输入格式的松散耦合。
简单的讲就是一句话:就是基于hadoop的一个数据仓库,用sql的方式实现MapReduce代码的效果。
hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,hive 并不适合那些需要高实性的应用,例如,联机事务处理(OLTP)。hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,hive 将用户的hiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。hive 并非为联机事务处理而设计,hive 并不提供实时的查询和基于行级的数据更新操作。hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析、日报、周报、业务数据统计分析。
HIVE OS、主要分为以下几个部分:
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 Cli,Cli 启动的时候,会同时启动一个 hive 副本。Client 是 hive 的客户端,用户连接至 hive Server。在启动 Client 模式的时候,需要指出 hive Server 所在节点,并且在该节点启动 hive Server。WUI 是通过浏览器访问 hive。
元数据存储
hive 将元数据存储在数据库中,如 mysql、derby。hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
Hive和Hadoop关系?解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tabName 不会生成 MapReduce 任务)。
hive中包含以下四类数据模型:表(Table)、外部表(External Tablc)、分区(Partition)、桶(Bucket)。
(1) hive中的Table和数据库中的Table在概念上是类似的。在hive中每一个Table都有一个相应的目录存储数据。
(2)外部表是一个已经存储在HDFS中,并具有一定格式的数据。使用外部表意味着hive表内的数据不在hive的数据仓库内,它会到仓库目录以外的位置访问数据。外部表和普通表的操作不同,创建普通表的操作分为两个步骤,即表的创建步骤和数据装入步骤(可以分开也可以同时完成)。在数据的装入过程中,实际数据会移动到数据表所在的hive数据仓库文件目录中,其后对该数据表的访问将直接访问装入所对应文件目录中的数据。删除表时,该表的元数据和在数据仓库目录下的实际数据将同时删除。外部表的创建只有一个步骤,创建表和装人数据同时完成。外部表的实际数据存储在创建语句I。OCATION参数指定的外部HDFS文件路径中,但这个数据并不会移动到hive数据仓库的文件目录中。删除外部表时,仅删除其元数据,保存在外部HDFS文件目录中的数据不会被删除。
Hive核心是什么。(3)分区对应于数据库中的分区列的密集索引,但是hive中分区的组织方式和数据库中的很不相同。在hive中,表中的一个分区对应于表下的一个目录,所有的分区的数据都存储在对应的目录中。
(4)桶对指定列进行哈希(hash)计算,会根据哈希值切分数据,目的是为了并行,每一个桶对应一个文件。
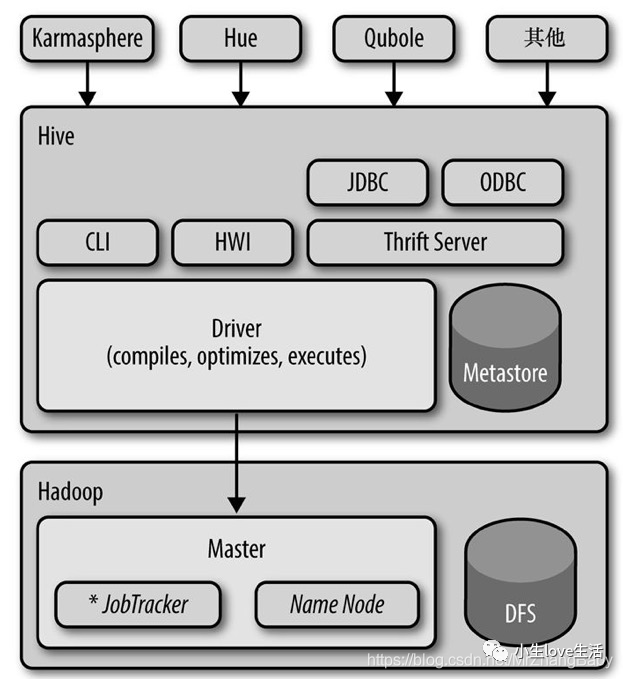
Hive发行版中附带的模块有CLI,一个称为Hive网页界面(HWI)的简单网页界面,以及可通过JDBC、ODBC和一个Thrift服务器进行编程访问的几个模块。
所有的命令和查询都会进入到Driver(驱动模块),通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤执行(通常是启动多个MapReduce任务(job)来执行)。当需要启动MapReduce任务(job)时,Hive本身是不会生成JavaMapReduce算法程序的。相反,Hive通过一个表示“job执行计划”的XML文件驱动执行内置的、原生的Mapper和Reducer模块。换句话说,这些通用的模块函数类似于微型的语言翻译程序,而这个驱动计算的“语言”是以XML形式编码的。
Hive通过和JobTracker通信来初始化MapReduce任务(job),而不必部署在JobTracker所在的管理节点上执行。在大型集群中,通常会有网关机专门用于部署像Hive这样的工具。在这些网关机上可远程和管理节点上的JobTracker通信来执行任务(job)。通常,要处理的数据文件是存储在HDFS中的,而HDFS是由NameNode进行管理的。
Metastore(元数据存储)是一个独立的关系型数据库(通常是一个MySQL实例),Hive会在其中保存表模式和其他系统元数据。
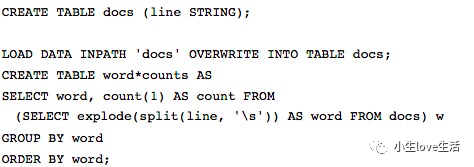
共同实现一个最经典的案例:单词计数
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
//暂存每个传过来的词频计数,均为1,省掉重复申请空间
private final static IntWritable one = new IntWritable(1);
//暂存每个传过来的词的值,省掉重复申请空间
private Text word = new Text();
//核心map方法的具体实现,逐个对去处理
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//用每行的字符串值初始化StringTokenizer
StringTokenizer itr = new StringTokenizer(value.toString());
//循环取得每个空白符分隔出来的每个元素
while (itr.hasMoreTokens()) {
//将取得出的每个元素放到word Text对象中
word.set(itr.nextToken());
//通过context对象,将map的输出逐个输出
context.write(word, one);
//reduce类,实现reduce函数
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
//核心reduce方法的具体实现,逐个去处理
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
//暂存每个key组中计算总和
int sum = 0;
//加强型for,依次获取迭代器中的每个元素值,即为一个一个的词频数值
for (IntWritable val : values) {
//将key组中的每个词频数值sum到一起
sum += val.get();
//将该key组sum完成的值放到result IntWritable中,使可以序列化输出
result.set(sum);
//将计算结果逐条输出
context.write(key, result);
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//设置到本次的job实例中
Job job = Job.getInstance(conf, "WordCount");
//指定本次执行的主类是WordCount
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
//指定combiner类,要么不指定,如果指定,一般与reducer类相同
job.setCombinerClass(IntSumReducer.class);
//指定reducer类
job.setReducerClass(IntSumReducer.class);
//指定job输出的key和value的类型,如果map和reduce输出类型不完全相同,需要重新设置map的output的key和value的class类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
//指定输出路径,并要求该输出路径一定是不存在的
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定job执行模式,等待任务执行完成后,提交任务的客户端才会退出!
System.exit(job.waitForCompletion(true) ? 0 : 1);
学习成本低,开发效率高
可扩展性强,
有良好的容错性
Hive不支持行级别的增删操作(只能通过分区、表直接覆盖)
不支持事务(没有进行增删改,虽然后面版本有支持,但是一般不会启用哦~)
执行的效率较低(本质上任然是MapReduce的执行)
简单的小结下,其实很简单,MapReduce开发成本比较大,需要开发者具备编程语言,以及熟悉API,虽然是八股文,但是撸代码成本、灵活性不是很够,开发时间比较久,而用hive的话,则可以通过简单的SQL来实现相关问题。Hive相当于做了一层SQL解析器,内部自动转换成了MapReduce,节省了成本和操作复杂性。

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态