笔者在读研刚开始的时候,偶尔看面经,有这样一个问题:只用2GB内存在20亿个整数中找到出现次数最多的数,当时的我一脸懵逼,怎么去思考,20亿个数?What The Fuck! 但是,看完今天的文章,你或许就会觉得原来也不过如此啊!其核心就是哈希函数和哈希表的应用!
java整除。哈希函数又称为散列函数,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。假设输出值域为S,哈希函数的性质如下:
最后一个性质对于一个优秀的哈希函数是非常重要的,并且这种均匀与数据的输入规律无关。比如“aa1”、"aa2"经过hash后可能结果会相差很多,当一个哈希函数的输出在S中是均匀的,那么我们将输出值对m取余(%m),就会将不定长输入映射到0~m-1空间中,并且在这个空间也保持均匀分布!哈希表就是这么做的,一会再说!哈希函数还有以下特点:
余数的公式,常见的哈希函数有:SHA1、MD5、SHA2等
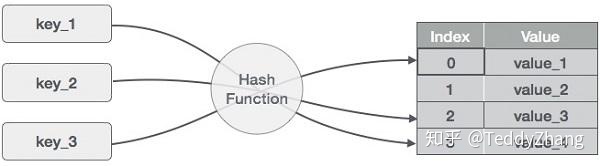
哈希表就是利用哈希函数,可以根据关键码而直接进行访问的数据结构,也就是将关键码(Key value)通过哈希函数映射到表中的一个位置来进行访问。由于是直接访问,所以对于哈希表的元素理论上的增删改查时间复杂度都是O(1)。
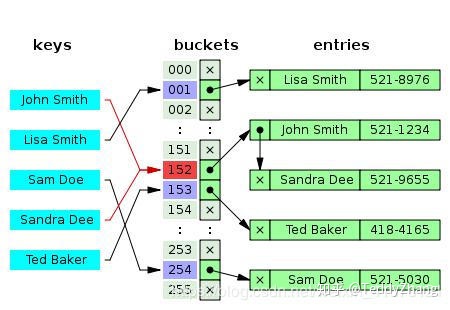
而计算散列地址的方法有很多种,通常我们使用的是除留余数法,也就是说使用哈希函数对关键字得到的输出值对散列表长度取余得到的余数即为散列地址。
由于我们的输入长度和范围是任意的,但是经过哈希函数后的输出值域是固定的,所以必然会产生冲突。如上图的buckets152(红色区域)就相当于发生冲突!处理冲突的方法有:
c++的hash_map和map的用法很类似,但一定要区别,map和hash_map虽然都是key-value形式,但是map的底层是红黑树,而hash_map的底层是hash表!如果在Linux下使用hash_map,一定要加上一个__gnu_cxx的命名空间声明!
#include首先我们确定value的范围,如果一个数出现了20亿次,那么value就为20亿次。因此我们使用32位的正整型,也就是4B的空间,同理key也是4B的空间,因此一条记录(Entry)需要8B的空间,当记录为20亿个时,需要至少16GB的内存。
在极端最差的状态,20亿个数都不相同,那么哈希表中可能会有20亿条记录,这样的话显然内存不足,因此一次性统计20个数风险很大。解决方案:将包含有20亿个数的大文件分成16个小文件,利用哈希函数,这样的话,同一个重复的数肯定不会分到不同的文件中去,并且,如果哈希函数足够好,那么这16个文件中不同的数也不会大于2亿(20 / 16)。然后我们在这16个文件中依次统计就可以了,最后进行汇总得到重复数最多的数。当然如果使用分布式系统,那么可以利用哈希函数将这些数据分配到不同的电脑上去!
如果想要看更多精彩内容,请关注我的个人公众号 (算法工程师之路)希望大家多多支持哦~
公众号简介:分享算法工程师必备技能,谈谈那些有深度有意思的算法,主要范围:C++数据结构与算法/深度学习(CV),立志成为Offer收割机!坚持分享算法题目和解题思路(Day By Day)

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态