1.Mycat的簡介
1.1 數據庫集群產生的背景
如今隨著互聯網的發展,數據的量級也是成指數的增長,從GB到TB到PB。對數據的各種操作也是愈加的困難,傳統的關系性數據庫已經無法滿足快速查詢與插入數據的需求。這個時候NoSQL的出現暫時解決了這一危機。它通過降低數據的安全性,減少對事務的支持,減少對復雜查詢的支持,來獲取性能上的提升。
但是,在有些場合NoSQL一些折衷是無法滿足使用場景的,就比如有些使用場景是絕對要有事務與安全指標的。這個時候NoSQL肯定是無法滿足的,所以還是需要使用關系性數據庫。如果使用關系型數據庫解決海量存儲的問題呢?此時就,為了提高查詢性能將一個數據庫的數據分散到不同的數據庫中存儲。
- 1、解決單機mysql存儲容量有限的問題
- 2、解決單機查詢性能不高的問題
- 3、解決mysql服務的高可用問題
1.2 MyCat簡介
Mycat 背后是阿里曾經開源的知名產品——Cobar。Cobar 的核心功能和優勢是 MySQL 數據庫分片,此產品曾經廣為流傳。Cobar 的思路和實現路徑的確不錯。基于 Java 開發的,實現了 MySQL 公開的二進制傳輸協議,巧妙地將自己偽裝成一個 MySQL Server,目前市面上絕大多數 MySQL 客戶端工具和應用都能兼容。比自己實現一個新的數據庫協議要明智的多,因為生態環境在哪里擺著。
mycat單庫分表后查詢、 Mycat 是基于 cobar 演變而來,對 cobar 的代碼進行了徹底的重構,使用 NIO 重構了網絡模塊,并且優化了 Buffer 內核,增強了聚合,Join 等基本特性,同時兼容絕大多數數據庫成為通用的數據庫中間件。
簡單的說,MyCAT就是:一個新穎的數據庫中間件產品支持mysql集群,或者mariadb?cluster,提供高可用性數據分片集群。你可以像使用mysql一樣使用mycat。對于開發人員來說根本感覺不到mycat的存在。
?
MyCat支持的數據庫:
MySQL多表查詢。?mysql,oracle,sqlserver等。
?
1.2MyCat下載及安裝
1.2.1 MySQL安裝與啟動
JDK:要求jdk必須是1.7及以上版本
MySQL:推薦mysql是5.5以上版本
分庫分表組件、MySQL安裝與啟動
?
1.2.2 MyCat安裝及啟動
MyCat的官方網站:
http://www.mycat.org.cn/
MySQL水平分庫、下載地址:
https://github.com/MyCATApache/Mycat-download
第一步:將Mycat-server-1.4-release-20151019230038-linux.tar.gz上傳至服務器
第二步:將壓縮包解壓縮。建議將mycat放到/usr/local/mycat目錄下。
tar -xzvf Mycat-server-1.4-release-20151019230038-linux.tar.gzmv mycat /usr/local 分庫分表cobar、?
第三步:進入mycat目錄的bin目錄,啟動mycat
啟動
./mycat start停止
./mycat stop mycat 支持的命令{ console | start | stop | restart | status | dump }
Mycat的默認端口號為:8066
1.2.3通過MySQL客戶端連接mycat(test/test)
分庫分表 infoq。?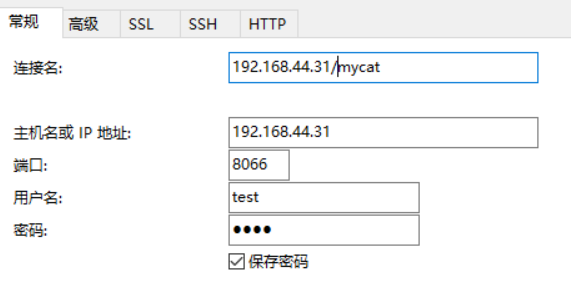
Mycat的默認端口和默認的用戶名和密碼:在conf目錄下面的server.xml文件中。
?
1.3MyCat分片-海量數據存儲解決方案
1.3.1 什么是分片
簡單來說,就是指通過某種特定的條件,將我們存放在同一個數據庫中的數據分散存放到多個數據庫(主機)上面,以達到分散單臺設備負載的效果。
MySQL concat。MyCat分片策略:
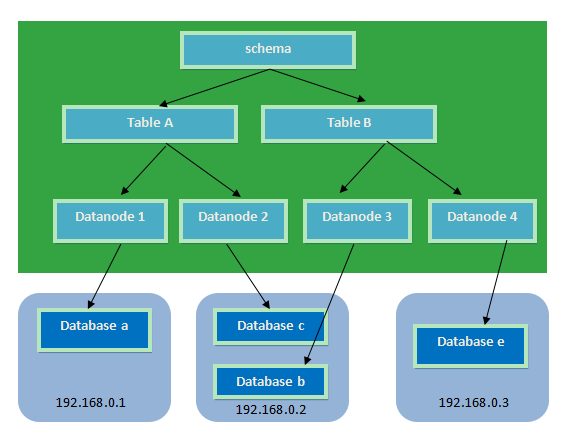
1.3.2 分片相關的概念
邏輯庫(schema) :
前面一節講了數據庫中間件,通常對實際應用來說,并不需要知道中間件的存在,業務開發人員只需要知道數據庫的概念,所以數據庫中間件可以被看做是一個或多個數據庫集群構成的邏輯庫。
mycat分表規則?邏輯表(table):
既然有邏輯庫,那么就會有邏輯表,分布式數據庫中,對應用來說,讀寫數據的表就是邏輯表。邏輯表,可以是數據切分后,分布在一個或多個分片庫中,也可以不做數據切分,不分片,只有一個表構成。
分片表:是指那些原有的很大數據的表,需要切分到多個數據庫的表,這樣,每個分片都有一部分數據,所有分片構成了完整的數據。 總而言之就是需要進行分片的表。
非分片表:一個數據庫中并不是所有的表都很大,某些表是可以不用進行切分的,非分片是相對分片表來說的,就是那些不需要進行數據切分的表。
mycat分庫分表的原理。分片節點(dataNode)
數據切分后,一個大表被分到不同的分片數據庫上面,每個表分片所在的數據庫就是分片節點(dataNode)。
節點主機(dataHost)
數據切分后,每個分片節點(dataNode)不一定都會獨占一臺機器,同一機器上面可以有多個分片數據庫,這樣一個或多個分片節點(dataNode)所在的機器就是節點主機(dataHost),為了規避單節點主機并發數限制,盡量將讀寫壓力高的分片節點(dataNode)均衡的放在不同的節點主機(dataHost)。
分片規則(rule)
前面講了數據切分,一個大表被分成若干個分片表,就需要一定的規則,這樣按照某種業務規則把數據分到某個分片的規則就是分片規則,數據切分選擇合適的分片規則非常重要,將極大的避免后續數據處理的難度。
?
1.3.3 MyCat分片配置
(1)配置schema.xml
schema.xml作為MyCat中重要的配置文件之一,管理著MyCat的邏輯庫、邏輯表以及對應的分片規則、DataNode以及DataSource。弄懂這些配置,是正確使用MyCat的前提。這里就一層層對該文件進行解析。
table 標簽定義了MyCat中的邏輯表? rule用于指定分片規則,auto-sharding-long的分片規則是按ID值的范圍進行分片 1-5000000 為第1片? 5000001-10000000 為第2片....
dataNode 標簽定義了MyCat中的數據節點,也就是我們通常所說的數據分片。
dataHost標簽在mycat邏輯庫中也是作為最底層的標簽存在,直接定義了具體的數據庫實例、讀寫分離配置和心跳語句。
?
1、分別在MySQL服務器? 192.168.44.31:3306 上創建3個數據庫:分別是db1?? db2?? db3,另外在 192.168.44.31:3306 上創建數據庫db4
2、修改schema.xml如下:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"><!-- 邏輯庫 --><schema name="ZYTEMPDB" checkSQLschema="false" sqlMaxLimit="100"><!-- 自動取模分片 --><table name="tb_test" dataNode="dn1,dn2,dn3,dn4" rule="auto-sharding-long" /><!-- 一致性hash分片 --><!-- <table name="tb_order" dataNode="dn1,dn2,dn3,dn4" rule="sharding-by-murmur-order" /> --></schema><!-- 分片 --><dataNode name="dn1" dataHost="localhost1" database="db1" /><dataNode name="dn2" dataHost="localhost1" database="db2" /><dataNode name="dn3" dataHost="localhost1" database="db3" /><dataNode name="dn4" dataHost="localhost2" database="db4" /><!-- 物理節點主機 --><dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="192.168.44.31:3306" user="root"password="root"></writeHost></dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="192.168.44.34:3306" user="root"password="root"></writeHost></dataHost> </mycat:schema>
?
(2)配置 server.xml
server.xml幾乎保存了所有mycat需要的系統配置信息。最常用的是在此配置用戶名、密碼及權限。在system中添加UTF-8字符集設置,否則存儲中文會出現問號
<property name="charset">utf8</property>
修改user的設置 ,? 我們這里為 PINYOUGOUDB設置了兩個用戶
<user name="test"><property name="password">test</property><property name="schemas">ZYTEMPDB</property></user><user name="root"><property name="password">root</property><property name="schemas">ZYTEMPDB</property></user>

1.3.4 MyCat分片測試
連接mycat服務器 ,執行下列語句創建一個表:
CREATE TABLE tb_test (id BIGINT(20) NOT NULL,title VARCHAR(100) NOT NULL ,PRIMARY KEY (id) ) ENGINE=INNODB DEFAULT CHARSET=utf8
插入數據
INSERT INTO TB_TEST(ID,TITLE) VALUES(1,'log1'); INSERT INTO TB_TEST(ID,TITLE) VALUES(2,'log2'); INSERT INTO TB_TEST(ID,TITLE) VALUES(3,'log3');INSERT INTO TB_TEST(ID,TITLE) VALUES(5000001,'log5000001');INSERT INTO TB_TEST(ID,TITLE) VALUES(10000001,'log10000001');
?此時會發現db1,db2,db3的存儲情況如下:
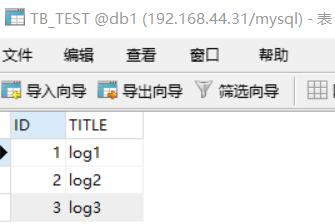 ?
?  ?
?
 ?
?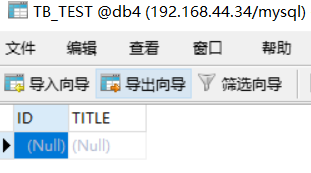
那么為什么會這樣存儲呢?這就引出了分片規則,因為我們上面的配置文件用的分片規則是 rule="auto-sharding-long"
這種分片規則很顯然不是我們常用的,下面就說一下如何配置我們常用的一種分片規則murmur
1.3.5 MyCat分片規則murmur(一致性hash)
(1)rule.xml中的配置
cd /usr/local/mycat/mycat/conf/
vim rule.xml 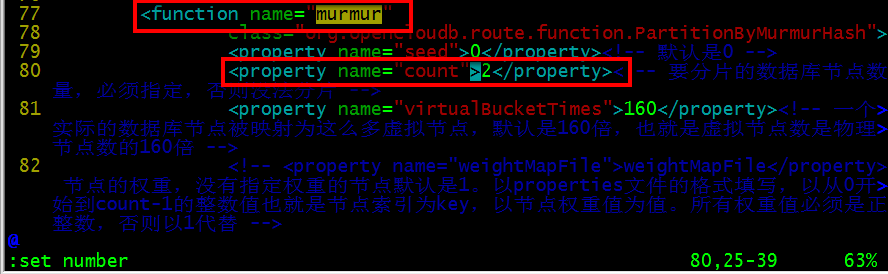
將上圖的2改為4,因為我們有四個db:db1,db2,db3,db4。
?
假設我們有一張order表,按照order_id進行分片,我們新添加一個分片規則:
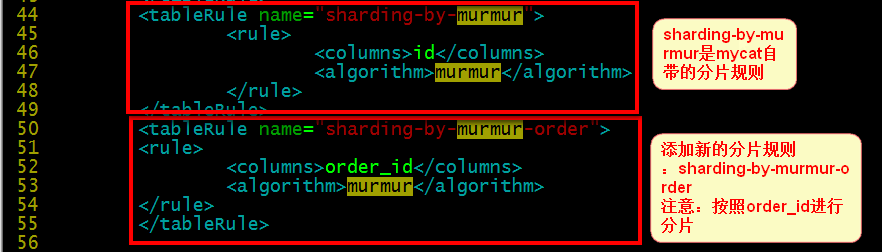
?
(2)schema.xml的配置
vim schema.xml? 編輯schema.xml文件,在tb_test下方添加如下配置:
<table name="tb_order" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur-order" />
(3)重啟mycat
cd /usr/local/mycat/mycat/bin/
./mycat restart (4)連接mycat,創建簡單的order表,并插入數據(注意mycat把我們的表名和字段名都變成大寫的了)
CREATE TABLE tb_order (order_id BIGINT(20) NOT NULL,title VARCHAR(100) NOT NULL ,PRIMARY KEY (order_id) ) ENGINE=INNODB DEFAULT CHARSET=utf8
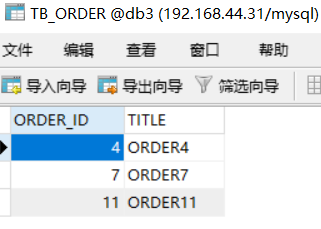
INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(1,'ORDER1'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(2,'ORDER2'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(3,'ORDER3'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(4,'ORDER4'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(5,'ORDER5'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(6,'ORDER6'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(7,'ORDER7'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(8,'ORDER8'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(9,'ORDER9'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(10,'ORDER10'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(11,'ORDER11'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(12,'ORDER12'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(13,'ORDER13'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(14,'ORDER14'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(15,'ORDER15'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(16,'ORDER16'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(17,'ORDER17'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(18,'ORDER18'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(19,'ORDER19'); INSERT INTO TB_ORDER(ORDER_ID,TITLE) VALUES(20,'ORDER20');
此時會發現db1,db2,db3,db4的存儲情況如下:
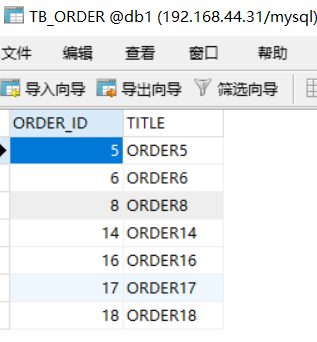 ?
?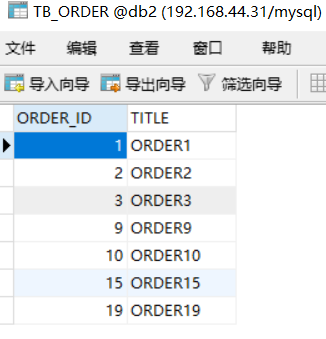 ?
?
 ?
?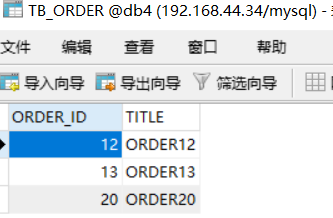
這種分片規則就比較合理了,而且數據越多均分的越勻。另外還有很多分片規則,比如按照時間之類的,有需要的可以自己查一下資料。
?