原文鏈接:https://blog.csdn.net/litianxiang_kaola/article/details/104138183?utm_source=app推薦語:寫的很好,kafka也是做實時流必備的技術。?解耦?異步?削峰
(1) 解耦
現有系統A, B, C, 系統B和C需要系統A的數據, 然后我們就修改系統A的代碼, 給系統B, C發送數據. 這時系統D也需要系統A的數據, 我們又要修改系統A的代碼, 給系統D發送數據. 如果這時系統B不需要系統A的數據了呢? 簡直崩潰了, 新增或減少一個系統, 我們都要去修改系統A的代碼, 而且我們還需要考慮調用的系統掛掉了怎么辦, 是否要將數據存起來, 是否要重發等等, 這是非常不合理的一種設計, 我們需要引入消息隊列.
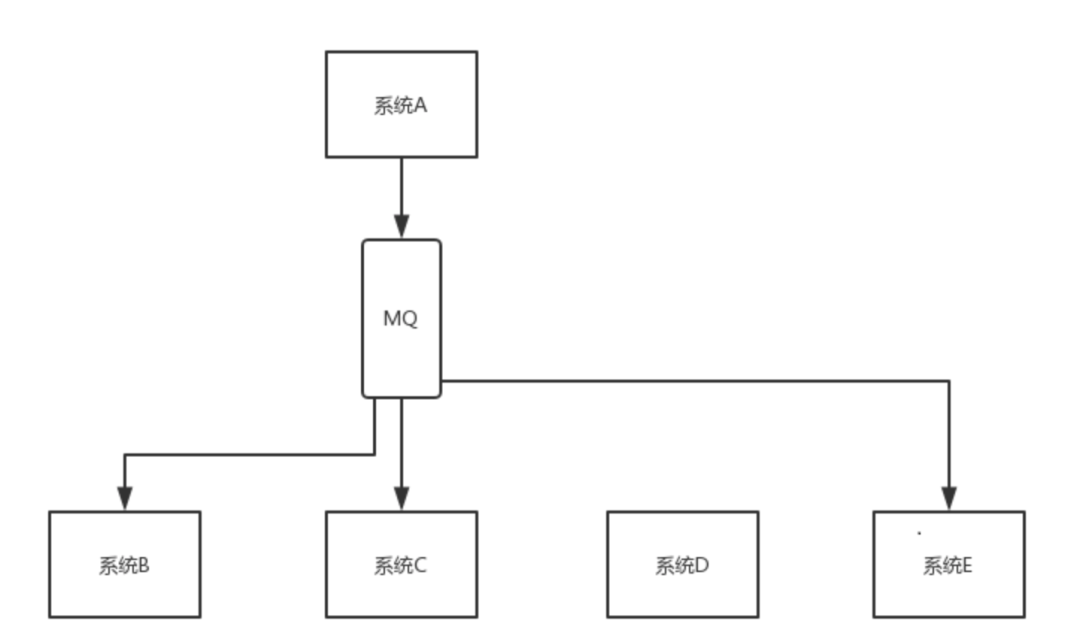
引入消息隊列后, 系統A產生的數據直接發送到消息隊列中, 哪個系統需要系統A的數據就直接去消息隊列中消費, 這樣系統A就和其他系統徹底解耦了.
實時數據倉庫架構。(2) 異步
客戶端調用A系統的一個接口處理某個功能, 該功能需要調用B, C, D系統進行處理, 如果A系統自身耗時為20ms, B, C, D系統耗時分別是300ms, 450ms, 200ms, 最終接口返回時總共耗時970ms, 這肯定是不可接受的, 我們需要引入消息隊列.
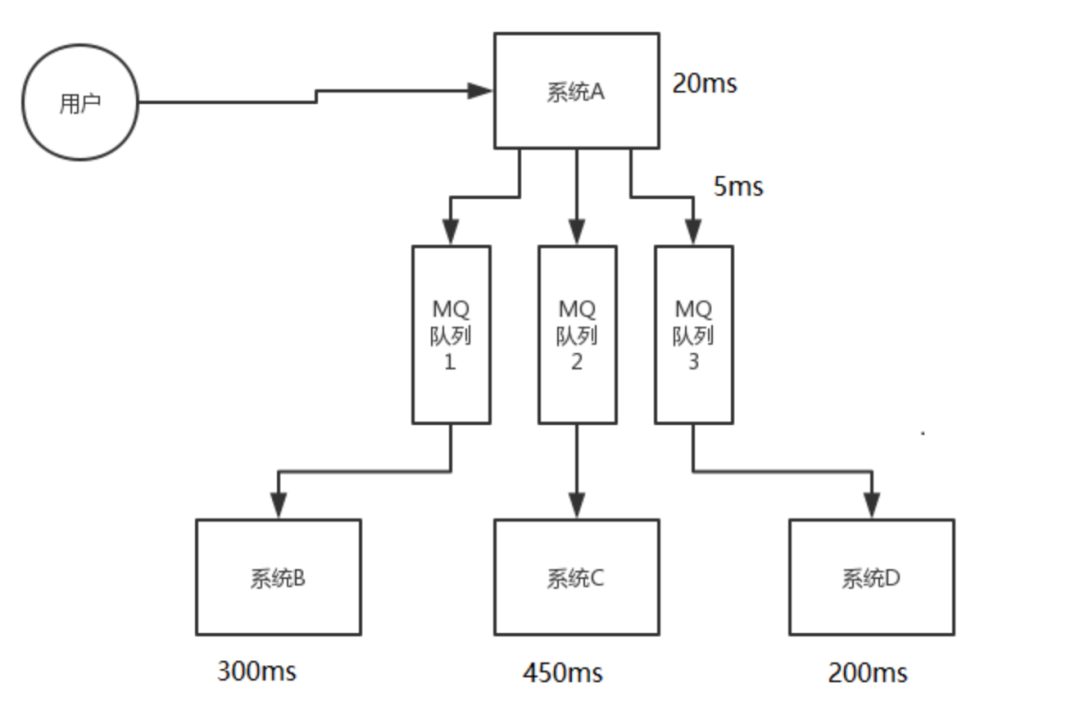
引入消息隊列后, 系統A將消息發送到消息隊列中就可以直接返回, 接口總共耗時很短, 用戶體驗非常棒.
(3) 削峰
在高并發場景下(比如秒殺活動)某一刻的并發量會非常高, 如果這些請求全部到達MySQL, 會導致MySQL崩潰, 這時我們需要引入消息隊列, 先將請求積壓到消息隊列中, 讓MySQL正常處理.
oracle到kafka的同步?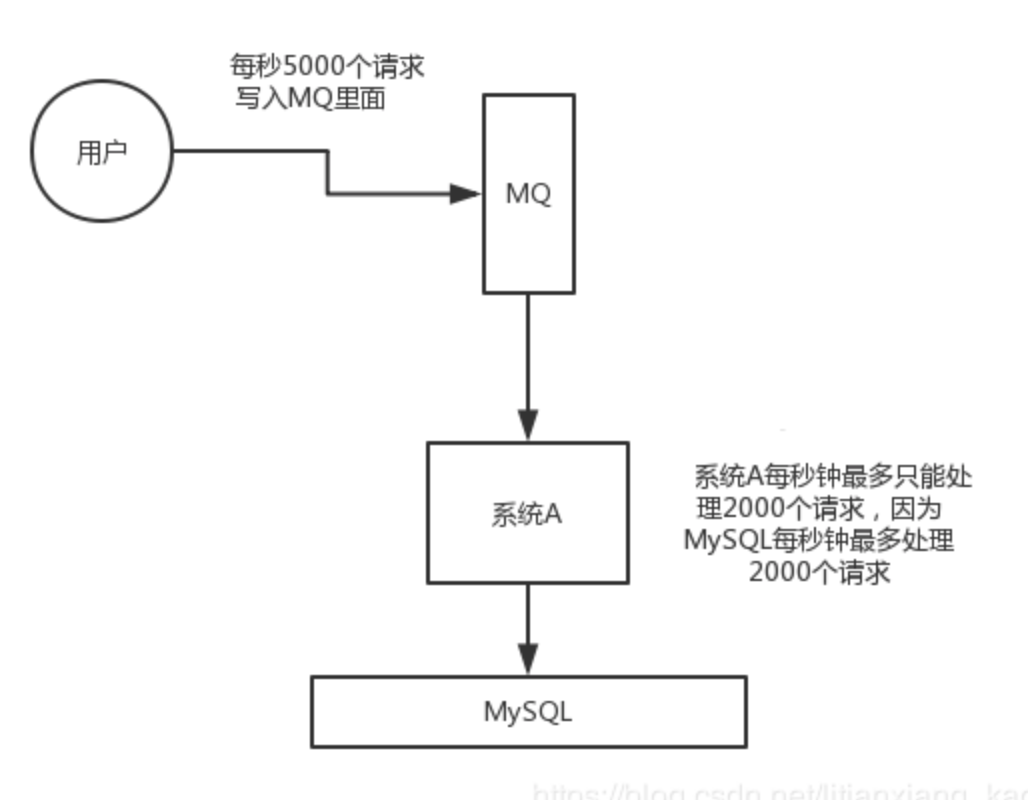
(1) 優點
?解耦?異步?削峰
(2) 缺點
?系統可用性降低,MQ一旦掛掉, 整個系統就崩潰了.?系統復雜度提高,引入MQ后需要考慮一系列問題, 比如消息丟失, 重復消費, 消息消費的順序等等.?一致性問題,沒有引入MQ之前有事務來保證一致性, 引入MQ后如果某一步執行失敗, 這就導致數據不一致了.
(1) ActiveMQ和RabbitMQ單擊吞吐量是萬級, Kafka和RocketMQ的單機吞吐量是10萬級.
kafka連oracle、(2) 四種MQ的時效性, 可用性, 消息可靠性都很高.
(3) ActiveMQ的社區不太活躍, 其他三種MQ的社區比較活躍.
(4) RabbitMQ是基于Erlang語言開發, 對Java開發者不太友好.
(5) Kafka當topic數量達到1000時吞吐量會大幅度下降, 而RocketMQ影響不太(這是RocketMQ相對于Kafka的一大優勢)
(6) Kafka的功能簡單, 吞吐量高, 天然適合大數據實時計算以及日志采集.
?回答自己熟悉的消息隊列, 如Kafka.
kafka同步數據,Kafka是一個分布式的消息隊列, 一個topic有多個partition, 每個partition分布在不同的節點上. 此外, Kafka還可以為partition配置副本機制, 一個主副本對外提供服務, 多個從副本提供冷備功能(即只起備份作用, 不提供讀寫).
(1) 從副本為什么不提供讀寫服務, 只做備份?
因為如果follower副本也提供寫服務的話, 那么就需要在所有的副本之間相互同步. n個副本就需要 n x n 條通路來同步數據, 如果采用異步同步的話, 數據的一致性和有序性是很難保證的, 而采用同步方式進行數據同步的話, 那么寫入延遲其實是放大n倍的, 反而適得其反.
(2) 從服務為什么不提供讀服務呢?
這個除了因為同步延遲帶來的數據不一致之外, 不同于其他的存儲服務(如ES,MySQL), Kafka的讀取本質上是一個有序的消息消費, 消費進度是依賴于一個叫做offset的偏移量, 這個偏移量是要保存起來的. 如果多個副本進行讀負載均衡, 那么這個偏移量就不好確定了.
總結一下, 從副本不提供讀寫服務的原因就是很難保證數據的一致性與有序性, 而且也沒必要提供讀寫服務, Kafka是一個消息隊列, 副本的作用是保證消息不丟失.
kafka使用教程。?partition主從副本數據同步
生產者發布消息到某個分區時, 先通過ZooKeeper找到該分區的leader副本, 然后將消息只發送給leader副本, leader副本收到消息后將其寫入本地磁盤. 接著每個follower副本都從leader副本上pull消息, follower副本收到消息后會向leader副本發送ACK(acknowledge). 一旦leader副本收到了 ISR (in-sync replicas) 中的所有副本的ACK, 該消息就被認為已經commit了, 然后leader副本向生產者發送ACK. 消費者讀消息只會從leader副本中讀取, 只有被commit過的消息才會暴露給消費者.
ISR(in-sync replicas)是與leader副本保持同步狀態的follower副本列表, 如果一段時間內(replica.lag.time.max.ms) leader副本沒有收到follower副本的拉取請求, 就會被leader副本從ISR中移除. ISR中的副本數必須大于等于 min.insync.replicas, 否則producer會認為寫入失敗, 進行消息重發.
?主副本選舉
當leader副本掛掉后, 集群控制器(即Master節點)會從ISR中選出一個新的主副本(ISR中的第一個, 不行就依次類推 ).
?集群控制器選舉
kafka實際應用?集群中的第一個broker通過在Zookeeper的 /controller 路徑下創建一個臨時節點來成為控制器, 當其他broker啟動時, 也會試圖創建一個臨時節點, 但是會收到“節點已存在”的異常, 這樣便知道集群控制器已存在. 這些broker會監聽Zookeeper的這個控制器臨時節點, 當控制器發生故障時, 該臨時節點會消失, 這些broker便會收到通知, 然后嘗試去創建臨時節點成為新的控制器.
(1) 導致消息重復消費的原因?
分區重平衡
消費者重啟或宕機
這兩個原因都會導致消費者在消費消息后沒有提交offset.
(2) 解決辦法
數據倉庫 實現。這個問題只能通過業務手段來解決, 比如我們在消費前先查詢數據庫, 判斷是否已消費(status = 1), 或消費后在Redis中做個記錄, 下次消費前先從Redis中判斷是否已消費.
(1) 導致消息丟失的原因?
kafka沒有保存消息.
消費者還沒消費就提交了offset, 然后消費者重啟或宕機, 分區重平衡.
(2) 解決辦法
配置partition副本機制.
實時消費kafka寫入redis、?default.replication.factor 每個分區的副本數必須大于1.?min.insync.replicas 與主副本保存同步狀態的從副本數必須大于等于1.?Producer端的配置acks=all, 指數據寫入min.insync.replicas個從副本后才算寫入成功.?Producer端的配置retries=MAX(一個很大的值, 表示無線重試的意思), 指數據一旦寫入失敗, 就無限重試.
關閉自動提交offset, 改為手動提交.
先消費, 消費成功后再手動提交offset.
kafka只保證單個分區內的消息有序, 所以要想保證消息的順序性, 只能一個topic, 一個partition, 一個consumer.
如果在consumer端開多個線程來進行消費, 如何保證消息的順序性?
一個topic, 一個partition, 一個consumer, consumer內部單線程消費, 寫N個內存queue, 然后開N個線程分別消費一個內存queue中的消息.
大數據kafka?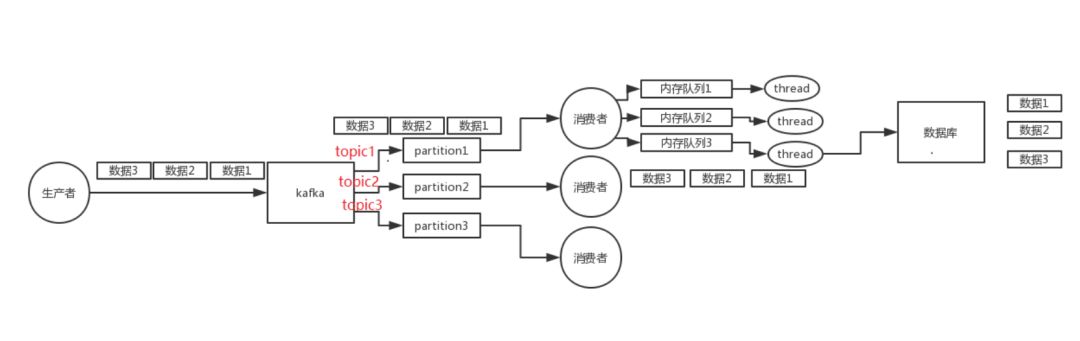
一般出現這種問題的原因就是消費端出了故障, 導致無法消費或消費極慢, 這時有兩種解決辦法, 根據不同的場景選擇不同的解決辦法.
(1) 緊急擴容
臨時征用10倍的機器來部署consumer, 新建一個topic, partition是原來的10倍. 寫一個臨時分發數據的consumer程序, 將積壓的數據不做處理, 直接分發給臨時建好的topic. 以10倍的速度消費積壓的消息, 消費完之后再恢復原來的部署.
(2) 批量重導
寫一個臨時分發數據的consumer程序, 將積壓的數據直接丟棄. 等高峰期過后, 寫個臨時程序, 將丟失的那批數據重新導入消息隊列中.
kafka實時程序、我們可以用Kafka的架構設計來回答這個問題.
(1) 分布式
這個消息隊列必須分布式的, 這樣通過水平擴展集群就可以增加消息隊列的吞吐量與容量. 分布式的消息隊列必須要有一個master節點來管理整個集群, 可以通過Zookeeper來實現master節點選舉算法.
(2) 可用性
一個topic必須支持多個partition, 且partition數量可以增加, 每個partition分布在不同的節點上. partition內通過offset來保證消息的順序. 同時為了保證可用性, 每個分區必須設置副本, 主副本提供讀寫服務, 從副本只作備份即可. 當主副本所在的節點宕機后, master節點會在從副本中選出一個作為主副本, 然后當宕機的節點修復后, master節點會將缺失的副本分配過去, 同步數據后, 集群恢復正常.
(3) 高性能
kafka批量數據寫入。為了保證高吞吐量, 我們可以使用批量壓縮, 順序寫, 零拷貝技術.
(4) 解決消息丟失方案
消息必須寫入所有副本中才算寫入成功.
我們都知道Kafka的核心特性之一就是高吞吐率, 但Kafka的數據是存儲在磁盤上的, 一般認為在磁盤上讀寫數據性能很低, 那Kafka是如何做到高吞吐率的呢?
?批量壓縮?順序寫?零拷貝 Kafka高吞吐率的秘訣在于, 它把所有的消息都進行批量壓縮, 提升網絡IO, 通過順序寫和零拷貝技術提升磁盤IO
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态