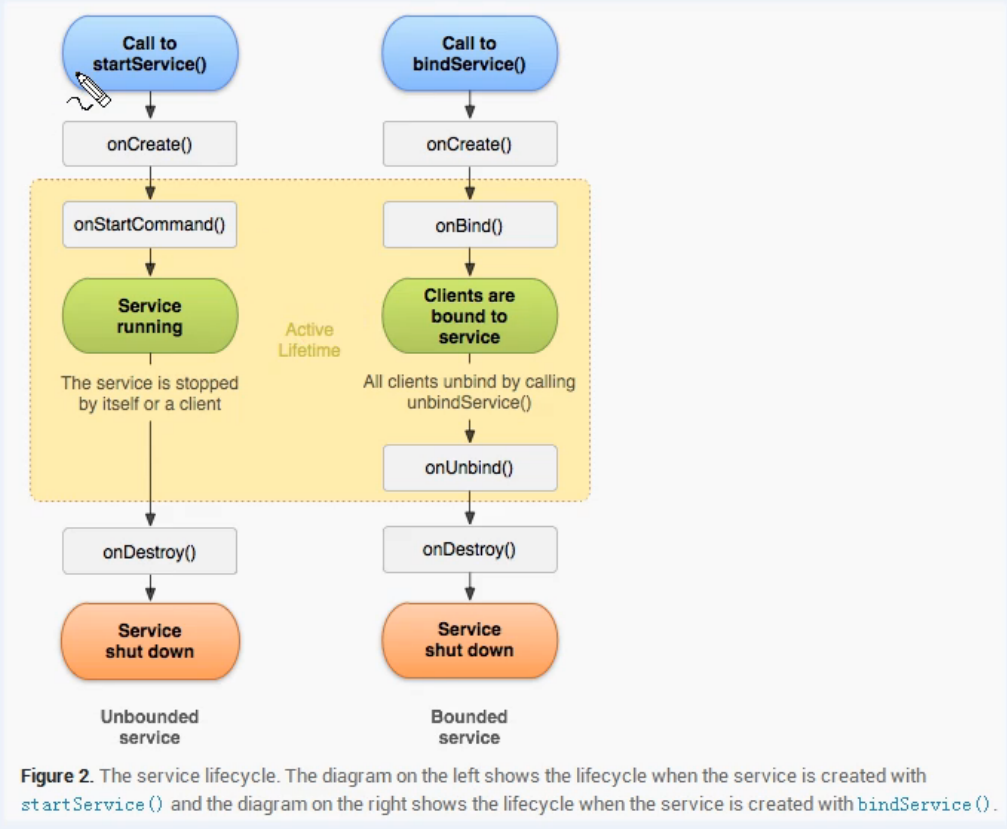
除了Map結尾的類之外,其他都實現了Collection接口,而以Map結尾的類實現了Map接口。
鏈表
在Java程序設計語言中,所有鏈表實際上都是雙向鏈表的(double linked)——即每個節點還存放著指向前去節點的引用。
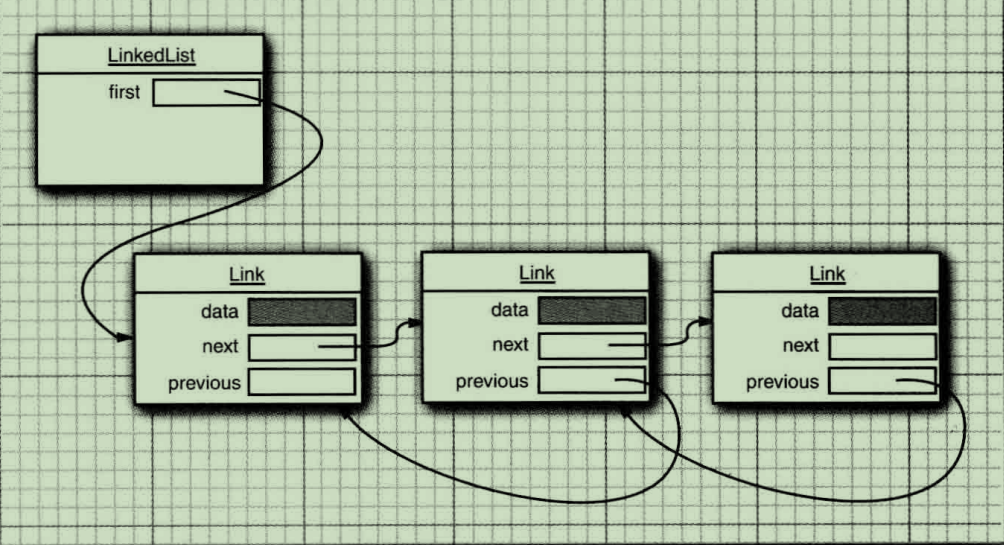
java技術有哪些,從鏈表中間刪除一個元素是一個很輕松的操作, 即需要更新被刪除元素附近的鏈接。
在鏈表中添加或刪除元素時,繞來繞去的指針可能已經給人們留下了極壞的印象。如果真是如此的話,就會為Java集合類庫提供一個LinkedList而感到拍手稱快。
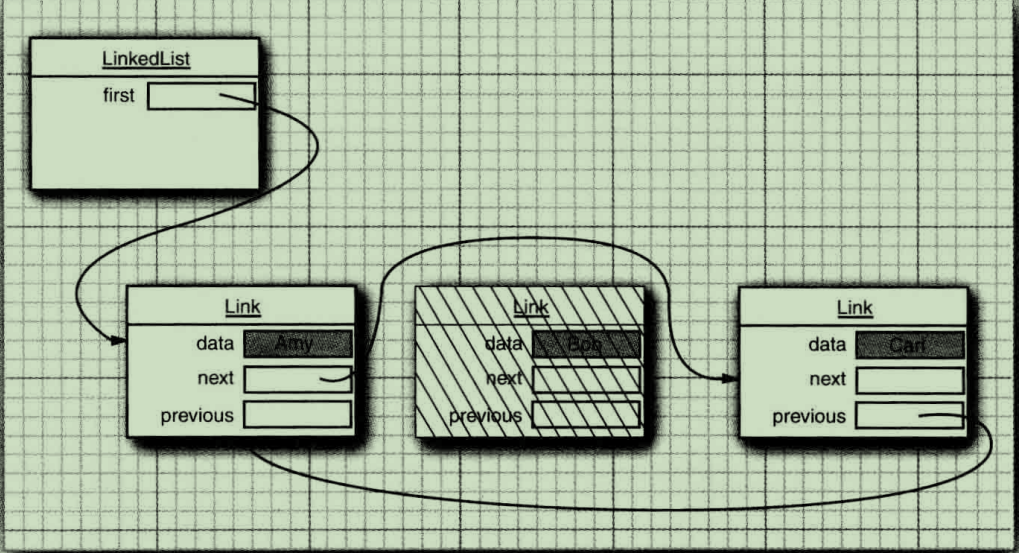
在下面的代碼示例中,先添加3個元素,然后再將第2個元素刪除;
List<String> staff = new LinkedList<>();// LinkedList implements List
staff.add("Amy");
staff.add("Bob");
staff.add("Carl");
Interator iter = staff.iterator();
String first = iter.next();//visit first element
String second = iter.next();//visit second element
iter.remove();//remove last visited element鏈表是一個有序集合(ordered collection),每個對象的位置十分重要。LinkedList.add方法將對象添加到鏈表的尾部。由于迭代器時描述集合中位置的,所以這種依賴于位置的add方法將由迭代器負責。只有對自然有序的集合使用迭代器添加元素才有實際意義。Add方法在迭代器之前添加一個新對象。
Java?當用一個剛剛由Iterator方法返回,并且指向鏈表表頭的迭代器調用add操作時,新添加的元素將變成列表的新表頭。當迭代器越過鏈表的最后一個元素時(即hasNext返回false),添加的元素將變成列表的新表尾。如果鏈表由n個元素,由n+1個位置可以添加新元素。這些位置與迭代器的n+1個可能的位置相對應。例如,如果鏈表包含3個元素,A、B、C,就有四個位置(標有|)可以插入新元素:
|ABC
A|BC
AB|C
ABC|
Java核心技術。注釋:在用“光標”類比時要格外小心。remove操作與BACKSPACE鍵的工作方式不太一樣。在調用next之后,remove方法確實與BACKSPACE鍵一樣刪除了迭代器左側的元素。但是如果調用previous就會將右側的元素刪除掉,并且不能連續調用兩次remove。
add方法只依賴于迭代器的位置,而remove方法依賴于迭代器的狀態。
例如,一個迭代器指向另一個迭代器剛剛刪除的元素前面,現在這個迭代器就是無效的,并且不應該在使用。鏈表迭代器的設計使它能夠檢測到這種修改。如果迭代器發現它的集合被另一個迭代器修改了,或是被該集合自身的方法修改了,就會拋出一個ConcurrentModificationException異常。
為了避免發生并發修改的異常,請遵循下述簡單規則:可以根據需要給容器附加許多的迭代器,但是這些迭代器只能讀取列表。另外,再單獨附加一個既能讀又能寫的迭代器。
有一個簡單的方法可以檢測到并發修改的問題。集合可以跟蹤改寫操作(諸如添加或刪除元素)的次數。每個迭代器都維護一個獨立的計數值。在每個迭代器方法的開始處檢查自己改寫操作的計數值是否與集合的改寫操作計數值一致。如果不一致,拋出一個ConcurrentModificationException異常。
Java核心技術卷。注釋:對于并發修改列表的檢測有一個奇怪的例外。鏈表只負責跟蹤對列表的結構性修改,例如,添加元素、刪除元素。set方法不被視為結構性修改。可以將多個迭代器附加給一個鏈表,所有的迭代器都調用set方法對現有節點的內容進行修改。
使用鏈表的唯一理由是盡可能地減少在列表中間插入或刪除元素所付出的代價。如果列表只有少數幾個元素,就完全可以使用ArrayList。
我們建議避免使用以整數索引表示鏈表中位置的所有方法。如果需要對集合進行隨機訪問,就使用數組或ArrayLister,而不要使用鏈表。
數組列表
散列集
有一種眾所周知的數據結構,可以快速地查找所需要的對象,這就是散列表(hash table)。散列表為每個對象計算一個整數,稱為散列碼(hash code)。散列碼是由對象地實例域產生的一個整數。更準確地說,具有不同數據域的對象將產生不同的散列碼。
在Java中,散列表用鏈表數組實現。每個列表被稱為桶(bucket)。
Java核心技術第十版,要想查找表中對象的位置,就要先計算它的散列碼,然后與桶的總數取余,所得到的結果就是保存這個元素的桶的索引。當然,有時候會遇到桶被占滿的情況,這也是不可避免地。這種現象被稱為散列沖突(hash collision)。這時,需要用新對象與桶中的所有對象進行比較,查看這個對象是否已經存在。如果散列碼是合理且隨機分布的,桶的數目也足夠大,需要比較的次數就會很少。
注釋:在Java SE 8中,桶滿時會從鏈表變為平衡二叉樹。如果選擇的散列函數不當,會產生很多沖突,或者如果有惡意代碼視圖在散列表中填充多個有相同散列碼的值,這樣就能提高性能。
如果想更多地控制散列表地運行性能,就要指定一個初始的桶數。桶數是指用于收集具有相同散列值的桶的數目。如果要插入到散列表中的元素太多,就會增加沖突的可能性,降低運行性能。入宮大致知道最終會有多少個元素要插入到散列表中,就可以設置桶數。通常,將桶數設置為預計元素個數的75%~150%。有些研究人員認為:盡管還沒有確鑿的證據,但最好將桶數設置為一個素數,以防鍵的集聚。
如果散列表太滿,就需要再散列(rehashed)。如果對散列表再散列,就需要創建一個桶數更多的表,并將所有元素插入到這個新表中,然后丟棄原來的表。裝填因子(load factor)決定何時對散列表進行再散列。
Java集合類庫提供了一個HashSet類,它實現了基于散列表的集。可以用add方法添加元素。contains方法已經被重新定義,用來快速地查看是否某個元素已經出現在集中。散列表迭代器將依次訪問所有的桶。由于散列將元素分散在表的各個位置上,所以訪問他們的順序幾乎是隨機的。
樹集
java核心技術第幾版好?TreeSet類與散列集十分類似,不過,它比散列集有所改進。樹集是一個有序集合(sorted collection)。可以以任意順序將元素插入到集合中。在對集合進行遍歷時,每個值將自動地按照排序后的順序呈現。
樹地排序必須是全序。也就是說,任意兩個元素必須是可比的,并且只有在兩個元素相等時結果才為0。
隊列與雙端隊列
隊列可以讓人們有效地在尾部添加一個元素,在頭部刪除一個元素。有兩個端頭的隊列,即雙端隊列,可以讓人們有效地在頭部和尾部同時添加或刪除元素。不支持在隊列中間添加元素。在Java SE 6中引入了Deque接口,并由ArrayDeque和LinkedList類實現。這兩個類都提供了雙端隊列,而且在必要時可以增加隊列的長度。
優先級隊列
優先級隊列(priority queue)中的元素可以按照任意的順序插入,卻總是按照排序的順序進行檢索。也就是說,無論何時調用remove方法,總會獲得當前優先級隊列中最小的元素。優先級隊列使用了一個優雅且高效的數據結構,稱為堆(heap)。堆是一個可以自我調整的二叉樹,對樹執行添加(add)和刪除(remove)操作,可以讓最小的元素移動到根,而不必花費時間對元素進行排序。
使用優先級隊列的典型示例是任務調度。每個任務有一個優先級,任務以隨機順序添加到隊列中。每當啟動一個新的任務時,都將優先級最高的任務從隊列中刪除(由于習慣上將1設為“最高”優先級,所以會將最小的元素刪除)。