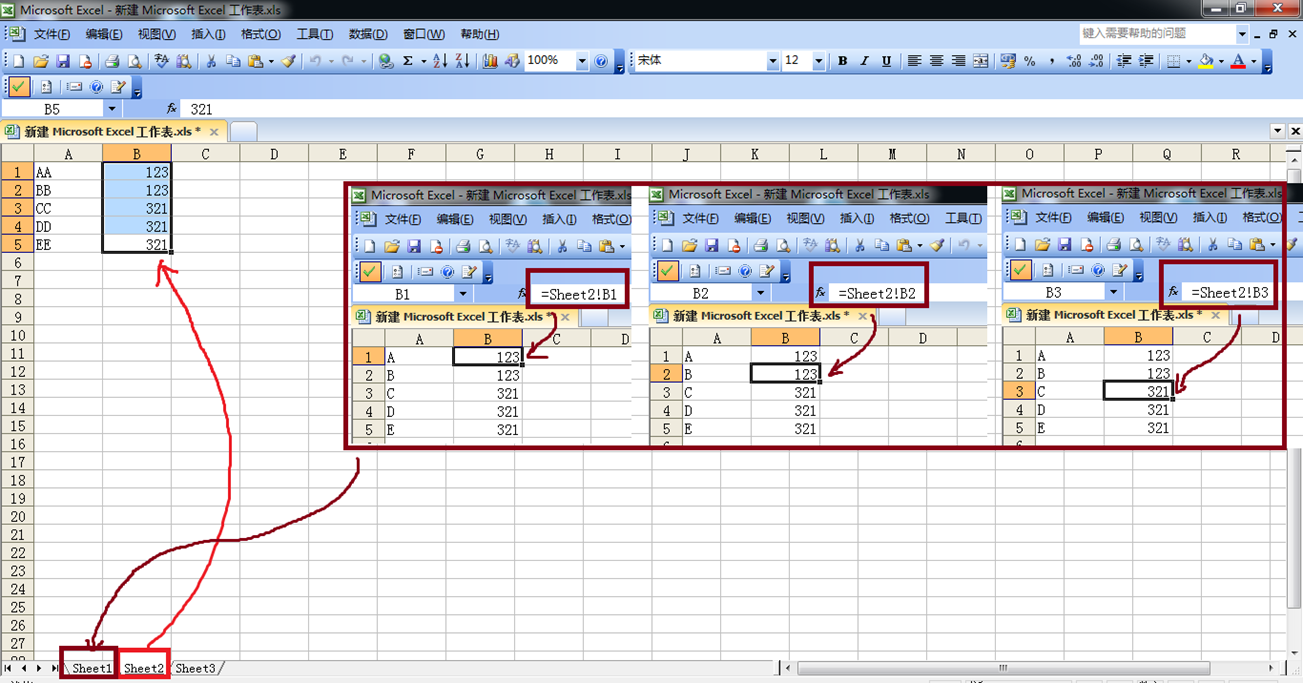
目標抓取盜墓筆記小說網站上《盜墓筆記》這本書的書名、章節名、章節url,并存放到MongoDB中
1.Scrapy中settings.py的設置(先scrapy startproject novelspider)
在settings.py中配置MongoDB的IP地址、端口號、數據記錄名稱,并通過settings.py使pipelines.py生效:
2.Scrapy中item.py設置
3.Scarpy中pipelines.py的設置
mongodb怎么使用?在pipelines中可以像普通的python文件操作MongoDB一樣編寫代碼出來需要保持到MongoDB中的數據,然而不同的是這里的數據來自items,這樣做的好處是將數據抓取和處理分開。
在通過settings導入MONGODB字典時竟然報錯了~~~~(瑪德),所示格式錯誤,不明所以,故mongodb的設置直接寫到pipelines中。把spider抓取到的數據存放到item實例中,再通過dict字典化insert到mongodb中。
4.spider文件下新建novspider.py
5.運行爬蟲
有兩種方法運行,一種是直接在cmd下輸入 scrapy crawl xxxspider,當然你得先cd到xxxspider文件夾下;
另一種是在xxxspider文件夾下(和scrapy.cfg同一個目錄下)建立一個mian.py腳本,其內容為:
scrapy的爬蟲怎調用,6.運行結果
刷新mongodb,我存放到mydb3中:
8.源碼
我分享到了百度云盤:鏈接:http://pan.baidu.com/s/1dFjxViD 密碼:a8m7
可能會失效,有需要的M我~~~~ 謝謝大家支持,荊軻刺秦王!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态








Redis——基础](/upload/rand_pic/2-238.jpg)
