目錄
1. 進程簡介
1.1 程序和進程
1.2 進程的定義
1.2.1 正文段
1.2.2 用戶數據段
1.2.3 系統數據段
1.3 進程的層次結構
1.3.1 進程的親緣關系
1.3.2 進程樹
1.3.3 祖先進程
1.4 進程狀態
1.4.1 基本進程狀態
1.4.2 進程狀態的轉換
1.5 從進程到容器
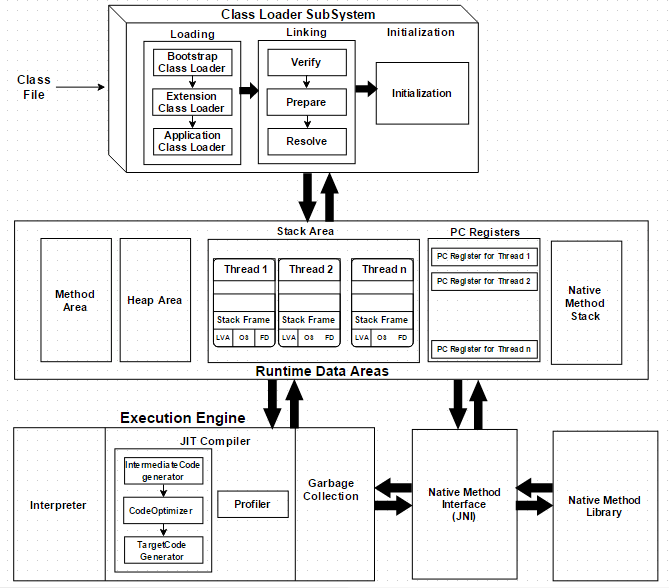
2. Linux中的進程控制塊
2.1 進程控制塊記錄的信息
2.2 進程狀態
2.2.1 PCB相關字段
2.2.2 進程狀態說明
2.3 進程標識符
2.3.1 pid
2.3.2 tgid
2.3.3 用戶標識與組標識
2.4 進程間親屬關系
2.5 進程控制塊的存儲
2.5.1 Linux 2.4實現
2.5.2 Linux 2.6實現
2.6 當前進程
3. Linux中的進程組織方式
3.1 進程鏈表
3.2 哈希表
3.3 就緒隊列
3.3.1 概述
3.3.2 Linux 2.4實現
3.3.3 Linux 2.6實現
3.4 等待隊列
3.4.1 概述
3.4.2 等待隊列頭數據結構
3.4.3 等待隊列數據結構
3.4.4 等待隊列操作
4. 進程調度
4.1 概述
4.1.1 進程調度的目標
4.1.2 基本調度模型
4.2 進程調度基本算法
4.2.1 時間片輪轉調度算法
4.2.2 優先權調度算法
4.2.3 多級反饋隊列調度
4.2.4 實時調度
4.3 時間片
4.3.1 時間片長度的設置
4.3.2 Linux時間片設置策略
4.4 Linux進程調度時機
4.5 進程調度的依據
4.5.1 need_resched
4.5.2 counter
4.5.3 nice
4.5.4 policy
4.5.5 rt_priority
4.5.6 goodness函數實現分析
4.6 調度函數schedule的實現
4.7 Linux 2.6調度程序的改進
4.7.1 單就緒隊列問題
4.7.2 多處理器問題
4.7.3 內核態不可搶占問題
4.8 O(1)調度簡介
4.8.1 O(1)調度器中的就緒隊列
4.8.2 O(1)進程調度
4.9 機制與策略分離的調度模型
4.9.1 機制:核心調度層(core scheduler)
4.9.2 策略:調度類(specific scheduler)
4.10 完全公平調度CFS簡介
5. 進程的創建
5.1 內核中的特殊進程
5.1.1 0號進程
5.1.2 1號進程
5.1.3 2號進程
5.2 進程和線程的關系
5.2.1 概述
5.2.2 Linux對進程和線程的統一描述
5.2.3 Linux對進程和線程的統一創建
5.3 do_fork函數流程簡介
6. 實例:系統負載檢測模塊
6.1 正確理解系統負載
6.1.1 查看系統負載
6.1.2平均負載定義
6.1.3 單核系統負載圖示
6.2 平均負載與CPU核心數的關系
6.3 負載檢測模塊實現分析
6.3.1 獲取系統負載值
6.3.2 定時檢測系統負載
6.3.3 打印所有線程調用棧
① 程序是一個普通文件,是機器指令和數據的集合,這些指令和數據存儲在磁盤上的一個可執行鏡像(Executable Image)中
② 進程是運行中的程序,除了包含程序中的所有內容,還包含一些額外數據,比如寄存器的值、用來保存臨時數據的棧、被打開的文件及輸入輸出設備的狀態等
③ Linux是多任務操作系統,也就是說可以有多個程序同時裝入內存并運行,操作系統為每個程序建議一個運行環境,即創建進程
④ 從邏輯上說,每個進程都有自己的虛擬CPU,或者說每個進程都人為自己獨占CPU,這里盜一張RTOS筆記中的圖用于說明

⑤ 實際物理上的CPU是在各個進程之間來回切換運行,進程切換(Process Switching)又稱作環境切換或上下文切換(Context Switching),這里的"進程的上下文"就是指進程的執行環境
進程是由正文段(Text)、用戶數據段(User Segment)和系統數據段(System Segment)共同組成的一個執行環境

③ 允許系統中正在運行的多個進程之間共享正文段(e.g. 動態庫)
② 該段存放進程的控制信息,Linux為每個進程建立task_struct結構來容納這些控制信息
說明:作為動態事物,進程是正文段、用戶數據段和系統數據段信息的交叉綜合體
① 進程是一個動態的實體,具有生命周期,系統中進程的生死隨時發生

說明1:pstree命令顯示的進程中只有用戶態進程,不包含內核態進程
說明2:init進程還負責收養系統中的孤兒進程,以保持進程樹的完整性


① 進程1(init)和進程2(kthreadd)都是由進程0產生

② 就緒態:進程已經具備運行條件,但是由于CPU忙而暫時不能運行
③ 阻塞態:進程因等待某種事件的發生而暫時不能運行(即使CPU空閑,進程也不可運行)
說明:這是操作系統理論中的3種基本狀態,不同的操作系統在實現時會有所不同
② 容器技術的核心功能,就是通過約束和修改進程的動態表現,從而為其創造出一個邊界
③ 對于Docker等大多數Linux容器而言,cgroups技術是用來制造約束的主要手段;而namespace技術則是用來修改進程視圖的主要方法
Linux中使用task_struct結構描述進程生命周期中涉及的所有信息,這樣的數據結構一般被稱作PCB(Process Control Block)
② 鏈接信息:描述進程的親屬關系,如父進程、養父進程、兄弟進程、子進程等
③ 各種標識符:用簡單數字對進程進行標識,如進程標識符、用戶標識符等
④ 進程間通信信息:描述多個進程在同一任務上的協作,如管道、消息隊列、共享內存、套接字等
⑤ 時間和定時器信息:描述進程在生存周期內使用CPU時間的統計等信息
⑥ 調度信息:描述進程優先級、調度策略等信息,如靜態優先級、動態優先級、時間片輪轉等
⑦ 文件系統信息:對進程使用文件情況進行記錄,如文件描述符、系統打開文件表、用戶打開文件表等
⑨ 處理器環境信息:描述進程的執行環境,即處理器的各種寄存器和棧等,這是體現進程動態變化最主要的場景
在進程的整個生命周期中,內核通過PCB感知進程的存在,并對進程進行控制。比如,
② 進程切換時,需要從PCB中取出處理器環境信息用于恢復運行現場
④ 當進程因某種原因需要暫停執行時,需要姜斷點的處理機環境保存到PCB中
![]()

Linux中使用PCB的state字段標識當前進程狀態,并使用一組宏(include/linux/sched.h)來進行標識
volatile用于避免編譯器優化,每次從內存而不是寄存器讀取數據,以確保狀態的變化能及時反映出來
說明2:內核中的進程狀態均被定義為2的n次方,目的是便于位或運算,形成組合的進程狀態
比如上圖中的TASK_NORMAL狀態就是TASK_INTERRUPTIBLE與TASK_UNINTERRUPTIBLE狀態的位或
EXIT_DEAD:最終狀態,進程將被徹底刪除,但需要父進程回收
TASK_DEAD:與EXIT_DEAD類似,但不需要父進程回收
TASK_WAKEKILL:接收到致命信號時喚醒進程,即使深度睡眠
docker進程。
進程正在睡眠(被阻塞),等待資源有效時被喚醒,期間可以被其他進程通過信號或時鐘中斷喚醒
② 此時進程已經結束并釋放大部分資源,但尚未釋放其PCB,可以使用wait系統調用回收該進程狀態并釋放PCB
① pid作為每個進程唯一的標識符,內核通過該標識符來識別不同進程
② pid也是內核提供給應用程序的接口,e.g. waitpid & kill系統調用
③ pid是32位無符號整型,按順序編號,新創建進程的pid通常是前一個進程的pid加1

可以在編譯內核時配置CONFIG_BASE_SMALL的值,進而確定系統中默認的最大pid,當內核在系統中創建進程的pid超過這個值時,就必須重新開始使用已閑置的pid號
可以查看/proc/sys/kernel/pid_max結點的值來確定當前Linux中允許的最大pid,也可以通過該結點直接修改上限
![]()
① tgid即thread group id,該字段主要與Linux的線程實現模式相關
② 在Linux中,線程是輕量級的進程,有自己的pid,只是共享進程的一些數據。在一個進程的多個線程之間,每個線程有自己的pid,但是tgid是相同的。關系如下圖所示,

需要注意的是,從用戶態視角,進程的不同線程調用getpid返回的pid是相同的,實際上返回的是task_struct的tgid
從內核態視角,每個線程有自己的pid,但是同一進程的不同線程有相同的tgid
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/syscall.h>// gettid系統調用沒有封裝例程
#define gettid() syscall(__NR_gettid)void *thread_1(void *arg)
{printf("thread_1:\n");printf("getpid() = %d\n", getpid());printf("gettid() = %ld\n", gettid());printf("pthread_self() = %ld\n", pthread_self());printf("\n");pause();return (void *)0;
}void *thread_2(void *arg)
{printf("thread_2:\n");printf("getpid() = %d\n", getpid());printf("gettid() = %ld\n", gettid());printf("pthread_self() = %ld\n", pthread_self());printf("\n");pause();return (void *)0;
}int main(void)
{pthread_t pthread_1;pthread_t pthread_2;printf("main thread:\n");printf("getpid() = %d\n", getpid());printf("gettid() = %ld\n", gettid());printf("pthread_self() = %ld\n", pthread_self());printf("\n");pthread_create(&pthread_1, NULL, thread_1, NULL);sleep(1);pthread_create(&pthread_2, NULL, thread_2, NULL);pthread_cancel(pthread_1);pthread_cancel(pthread_2);pthread_join(pthread_1, NULL);pthread_join(pthread_2, NULL);return 0;
}
① 主線程與2個子線程中,getpid的返回值相同,實際上返回的是task_struct中的tgid字段
② 主線程與2個子線程中,gettid的返回值均不同,實際上返回的是task_struct中的pid字段
③ POSIX thread庫維護的tid(pthread_t類型)與內核態維護的pid & tgid完全不同,是用戶態庫的行為


看了內核態的實現,是不是一目了然,也能理解對多線程程序中用戶視圖 & 內核視圖下"進程"的含義
task_struct中定義有用戶標識符UID和組標識符GID,這兩種標識符用于系統的安全控制,系統通過這兩種標識符控制進程對文件和設備的訪問
在Linux 2.4中,直接在task_struct中定義了uid、gid等字段

在Linux 2.6中,將相關內容打包為struct cred結構


task_struct中的如下字段用于維護進程間的親屬關系,


② 但是父進程可能在子進程之前結束,此時init會收養該子進程,即成為該子進程的養父進程
說明2:因為一個進程可以創建多個子進程,所以有子進程鏈表,同時子進程之間是兄弟關系
在不同的Linux內核版本中,PCB都是和進程的內核棧一并存儲的,這樣可以達到2個目的,
① 節省內存空間,不再單獨分配(當然,你也可以任務可用的棧空間減少了)
② 使用方便,進程一進入內核態,CPU就自動設置該進程的內核棧,而通過進程內核棧就很容易找到該進程的PCB
線程。
![]()
PCB的分配與釋放通過alloc_task_struct & free_task_struct函數實現,內存通過buddy系統分配
do_fork--> alloc_task_structsys_wait4--> release_task--> free_task_struct② 調用wait系統調用回收進程時才釋放PCB,所以僵尸進程(Zombie)會占用PCB資源


② 存儲在進程內核棧中的不再是PCB,而是thread_info結構,該結構更小且包含指向PCB的指針

可見thread_info結構更貼近底層,且調用__switch_to進行進程上下文切換時就是使用該結構

在thread_info結構中包含了cpu_context_save結構,該結構根據體系結構不同,用于保存寄存器的值(下圖示例中為ARM32體系結構)

進程?
② PCB通過slab系統分配(slab高速緩存讀寫速度更快)

隨著Linux版本的變化,進程控制塊的內容越來越多,所需空間越來越大,這樣就使得留給內核棧的空間變小。因此把部分進程控制塊的內容移出這個空間,只保留訪問頻繁的thread_info
那么task_struct & thread_info的究竟多大呢 ? 我們在Ubuntu 16.04(Linux 4.15.0)上驗證一下
![]()
可見task_struct的大小已經查過進程內核棧的大小了,所以必須移出該空間
在115-Ubuntu(Linux 3.2.0)上也驗證一下,可見不移走真的沒天理啊~
![]()
do_fork--> copy_process--> dup_task_struct--> alloc_task_struct // 分配PCB--> alloc_thead_info // 分配進程內核棧do_wait--> do_wait_thread--> wait_consider_task--> wait_task_continued--> put_task_struct--> __put_task_struct--> free_task--> free_thread_info--> free_task_info② 當前進程使用current宏獲得,通過上述分析就很容易理解內核的實現方式了,本質上就是在進程內核棧中找到PCB


通過屏蔽sp的低13位,就可以獲得進程內核棧的棧底(低端地址),也就獲得了thread_info的地址,據此就可以獲得當前進程的PCB
static int __init current_init(void)
{printk("Hello world, from the kernel space\n");printk("current task: %d --> %s\n", current->pid, current->comm);
}static void __exit current_exit(void)
{printk("Goodbye world, from the kernel space\n");printk("current task: %d --> %s\n", current->pid, current->comm);
}module_init(current_init);
module_exit(current_exit);
② task_struct中的tasks字段用于維護進程鏈表
![]()
③ 進程鏈表為雙向循環鏈表,頭節點為init_task,即0號進程的PCB


可見init_task的PCB和進程內核棧都是靜態分配的,是一個全局變量,由于未再設置他的pid,所以init_task的pid為0,也就是整個Linux中的始祖進程
static int print_pid(void)
{struct task_struct *task = NULL;struct task_struct *p = NULL;struct list_head *pos = NULL;int count = 0;// 打印0號進程信息printk("init_task:%d --> %s\n", init_task.pid, init_task.comm);task = &init_task;list_for_each(pos, &task->tasks){p = list_entry(pos, struct task_struct, tasks);++count;printk("%d ---> %s\n", p->pid, p->comm);}printk("number of process is: %d\n", count);return 0;
}在內核中調用print_pid函數可以打印當前系統中的所有進程,注意,此處不包含0號進程,可以單獨打印

① 為了能夠通過pid快速找到對應的PCB,Linux中的所有進程也被組織在哈希表中
![]()
③ 內核中的pid_hash是一個全局變量,通過鏈地址法處理沖突,同一鏈表中pid由小到大排列


④ 通過find_task_by_vpid函數可以通過pid找到PCB

需要注意的是,此處為Linux 2.6中的實現,該版本已引入pid_namespace的概念
① 當內核需要尋址一個進程在CPU上運行時,只需要考慮處于就緒態(TASK_RUNNING)的進程
③ 當進程不可運行時,需要被移出就緒隊列,該操作在schedule函數中完成
task_struct中的run_list字段用于維護就緒隊列
![]()
就緒隊列runqueue_head為一個全局變量(kernel/sched.c),實現上就是一個內核鏈表頭節點

說明:runqueue_head本身不具備互斥機制,對他的操作需要通過自旋鎖runqueue_lock進行保護,下圖為wake_up_process函數中的示例


add_to_runqueue被wake_up_process & wake_up_process_synchronous調用,也就是當進程被喚醒時(準確說是可被調度時,比如do_fork中創建新的進程)將該進程加入就緒隊列
② del_from_runqueue函數將PCB移出就緒隊列

del_from_runqueue主要被schedule函數調用,當prev進程的狀態不能再參與調度時,需要將該進程移出就緒隊列,典型場景就是進程調用sleep_on等函數進入睡眠狀態(在sleep_on函數中會調用schedule進行進程切換)

在Linux 2.6版本中,run_list字段被替換為2個調度實體結構,其中分別封裝了cfs_rq和rt_rq結構


![]()
說明1:struct rq結構封裝了就緒隊列與調度相關信息,與task_struct中的字段是匹配的,整個進程調度的實現也更加復雜
在Linux 2.4中,多處理器共享一個就緒隊列,即多處理器上的進程放在一個就緒隊列中,使得這個就緒隊列成為臨界資源,從而降低了系統效率
Linux 2.6中引入了調度類(sched class)的概念,task_struct中也包含了指向進程調度類的結構指針,當進程進出就緒隊列時,會調用注冊的hook函數

在調用enqueue_task函數入隊時,會根據PCB的不同調度類加入不同的就緒隊列,而加入就緒隊列的時機仍然是調用wake_up_process函數

注:Linux 2.6的進程調度更為復雜,此處不做更多的分析
① 當進程需要進入睡眠狀態時(TASK_INTERRUPTIBLE & TASK_UNINTERRUPTIBLE),需要有可以實現睡眠和喚醒的機制,即有地方進入等待狀態,有地方喚醒進程
② 等待隊列就是用于實現在事件上的條件等待,即希望等待特定事件的進程把自己放入放進合適的等待隊列,并放棄控制權
③ 除了等待隊列,內核中的mutex、semaphore等機制也可以實現等待,實現的思路也是類似的(劇透一下,mutex & semaphore結構起到了等待隊列頭的作用)

等待隊列頭就是由等待隊列鏈表(task_list)和相關的保護機制(自旋鎖)構成
可以使用DECLARE_WAIT_QUEUE_HEAD宏直接定義一個初始化好的等待隊列頭

如果單獨定義了wait_queue_head_t類型的變量,也可以調用init_waitqueue_head宏函數進行初始化,該函數的內部實現也就是初始化等待隊列頭結構中的自旋鎖和鏈表



取值為0或1(即WQ_FLAG_EXCLUSIVE),標識睡眠進程是否互斥,后文將會看到,如果是互斥進程,喚醒時只會喚醒第1個;如果是非互斥進程,則會喚醒所有進程參與調度

DECLARE_WAITQUEUE宏可用于定義一個初始化好的等待隊列

① 定義等待隊列時指定的task一般就是current,也就是當前進程,因為要睡眠的就是當前進程
② 此處提供的默認喚醒函數為default_wake_function,該函數就是去喚醒等待隊列private字段指向的進程

如果單獨定義了wait_queue_t類型的變量,也可以調用init_waitqueue_entry函數進程初始化,效果與上面的宏一致

補充:內核中還提供了init_waitqueue_func_entry函數,可用于指定等待隊列的喚醒函數

但是要注意,該函數會將等待隊列的private字段清空,可根據需要再次設置,以下為do_wait函數的示例

稍微多說一丟丟,這里的操作就是讓wait系統調用阻塞等待回收子進程

add_wait_queue & add_wait_queue_exclusive函數用于實現直接將等待隊列插入等待隊列頭,差別在于2點,
① add_wait_queue_exclusive將等待隊列的flags字段置為WQ_FLAG_EXCLUSIVE
以sleep_on函數族為例,最終都是調用sleep_on_common函數實現,差別在于是否可喚醒以及是否設置超時時間

當不需要超時時,將timeout值設置為MAX_SCHEDULE_TIMEOUT,實現中一般為long類型可表示的最大值,此時不會實際建立定時器,只是用于標識無需超時

將等待隊列移出等待隊列頭的操作需要在當前進程被再次調度運行時才進行,而此時有2種情況,
此時就要分析一下schedule_timeout函數的實現,

process_timeout為timer到期時調用的函數,該函數的作用就是喚醒指定的進程(此處指定的就是current進程)

說明2:sleep_on函數族無法識別被中斷喚醒還是等待的事件就緒,只要帶有timeout,返回的就是定時器剩余jiffies值
所以在使用中,當sleep_on函數族返回時(帶timeout或interruptible的版本),可以調用signal_pending,判斷進程是否是被中斷喚醒

① 通過上文對sleep_on函數族的分析可知,進入睡眠的主要步驟就是將當前進程(current)設置為睡眠態 + 調用schedule函數觸發進程切換
但是在處理中斷時(更準確地說,是在處理中斷頂半部時),中斷上下文卻不是一個進程,他不存在task_struct,所以是不可調度的。如果在中斷頂半部中調用類似sleep_on的函數,依然是將current睡眠,而這個睡眠完全是不符合預期的,被睡眠的是從當前棧中計算出的task_struct標識的進程
② 為什么中斷上下文不存在對應的task_struct結構 ?
中斷的產生是很頻繁的(比如Linux 2.6之后的timer中斷每毫秒產生一個),并且中斷處理過程很快。如果為中斷上下文維護一個對應的task_struct結構,這個結構會被頻繁地分配和回收(尤其是task_struct結構已經非常巨大),會影響調度器的管理,進而影響整個系統的吞吐量
③ 但是在某些實時性的嵌入式Linux中,中斷也被賦予task_struct結構。這是為了避免大量中斷不斷的嵌套,導致一段時間內CPU總是運行在中斷上下文,使得某些優先級非常高的進程得不到運行
④ Linux 2.6之后的內核版本中還存在一些不可搶占的區間,如中斷上下文、軟中斷上下文和自旋鎖鎖住的區間
如果給Linux內核打上RT-Preempt補丁,則中斷和軟中斷都被線程化了,自旋鎖也被互斥體替換,此時的Linux內核就可以支持硬實時
喚醒等待隊列可以使用wake_up函數族,這些函數最終都會調用到__wake_up_common函數


該函數的主體就是遍歷等待隊列,并調用喚醒函數。需要注意的是對互斥進程的處理,根據上文的分析,加入等待隊列中的進程都是非互斥進程在前,互斥進程在后,所有非互斥進程會先被全部喚醒
對于非互斥進程,需要喚醒nr_exclusive個互斥進程后才會停止,如果nr_exclusive <= 0,由于!--nr_exclusive條件始終為false,將會喚醒所有非互斥進程
說明:當調用wake_up_interruptible函數族時,會指定state參數為TASK_INTERRUPTIBLE,此時只會喚醒淺度睡眠的進程,因為在try_to_wake_up函數中,當試圖喚醒的進程狀態與state不符時,會退出函數

說明:這5個目標不可能同時實現,有些目標之間還是沖突的,所以不同操作系統需要在這些目標之間進行取舍
不同類型的任務側重點不同,對于實時進程,響應時間是最重要的。對于普通進程,需要兼顧其他4點需求

① 進程調度就是從就緒隊列(Runqueue)中選擇一個最值得運行的進程運行
④ 對以時間片調度為主的調度算法,時鐘中斷就是驅動力,確保每個進程都可以在CPU上運行一定的時間
說明:這種遍歷就緒隊列的調度算法的實踐復雜度為O(n),Linux 2.4就使用了這種調度算法
① 時間片(Time Slice)是分配給進程運行的一段CPU時間
③ 當進程的時間片耗盡時,系統發出信號,通知調度程序切換進程運行
① 優先權反映了進程的緊迫性,系統將CPU分配給就緒對了中優先權最高的進程
② 在非搶占式優先權算法(Nonpreemptive Scheduling)中,一旦將CPU分配給當前優先權最高的進程,該進程可一直運行到結束或主動放棄CPU
③ 在搶占式優先權算法(Preemptive Scheduling)中,只要出現更高優先權的進程,便可搶占當前運行的進程,即系統中當前運行的進程一定是可運行進程中優先權最高的
這種算法更能滿足實時性的要求,Linux目前也使用這種調度算法
② 優先權高的進程先運行給定的時間片,相同優先級的進程輪流運行給定的時間片
① 時間片過長會導致系統對交互的響應表現欠佳,讓人覺得系統無法并發執行應用程序
① 提高交互式程序的優先級,設置較長的默認時間片,讓他們運行得更頻繁
Linux中每當調用schedule函數時,即進行進程切換,執行調度程序的時機如下,
當進程調用sleep_on或exit等函數時,這些函數會主動調用調度程序
不管從中斷、異常還是系統調用返回,都要對調度標志進行檢查,如有必要則調用調度程序
這么做是為了提高效率,因為進程調度只能在內核態進行,所以在返回內核態之前檢查一次,避免為例調度程序再從用戶態進入內核態的開銷
注:本節以Linux 2.4版本為例,需要特別注意的是,Linux 2.4版本內核是不支持搶占的
首先介紹一下在task_struct中和進程調度相關的字段,
② 代碼中多是判斷current->need_resched,當值為1時,調用schedule函數
③ 將task_struct的need_resched字段置為1,就是說明該進程不能再運行了,需要被調度走,所以下面理解的重點就是在這些場景中為何要調度走這個進程
下面是將need_resched設置為1的一些場景(其實是Linux 2.4中的所有場景了),
創建子進程后,父子進程平分父進程剩余的時間片,如果平分后父進程時間片為0,則設置調度標志


補充一點,在進入cpu_idle函數之后,會將進程0的優先級設置為最低。由于在進入cpu_idle之前設置了need_resched字段,所以進入cpu_idle后會觸發調度

reschedule_idle函數被wake_up_process調用,該函數的作用是為喚醒的進程選擇一個合適的CPU來執行,如果他選中了某個CPU,就會將該CPU上當前運行進程的need_resched標志置為1,即該CPU上有更值得運行的進程運行了

該函數被系統調用服務例程sys_sched_setparam & sys_sched_setscheduler調用,由于設置了目標進程的調度策略或優先級,可能有更值得運行的進程了,所以將當前進程的need_resched標志置為1
說明:此處對應的系統調用封裝例程為sched_setparam & sched_setscheduler

sys_sched_yield為系統調用服務例程,用于主動讓出CPU

update_process_times被系統時鐘中斷調用,該函數會遞減當前正在運行進程的時間片,如果時間片耗盡,則標記需要調度
這里也順帶說明了task_struct結構中counter字段的作用~
① 進程處于可運行狀態時所剩余的時鐘節拍數,根據上文,當進程在運行時,每次時鐘中斷到來,該值減1
① 進程的基本優先級,也稱作靜態優先級。這個值在-20 ~ 19之間,值越小優先級越高,缺省值0對應普通進程
② nice的值決定counter的初值,該轉換通過NICE_TO_TICKS宏實現,

注:20 - nice的值為[40, 1],可見nice的取值確實是歷史遺留現象,當時的目的就是為了讓優先級高的進程獲得更多的ticks
進程的調度策略,在Linux 2.4內核版本中支持如下3種調度測錄,
說明1:SCHED_FIFO & SCHED_RR都是實時進程,與普通分時進程有本質區別,下文的goodness函數分析中可見,二者的調度優先級有天壤之別
SCHED_NORMAL / SCHED_FIFO / SCHED_RR / SCHED_BATCH / SCHED_IDLE / SCHED_YIELD
② 實時進程優先級有效值為[1, 99],在setscheduler函數中設置(系統調用服務例程)
int prio; // 動態優先級
int static_prio; // 靜態優先級
int normal_prio; // 歸一化優先級
unsigned int rt_priority; // 實時優先級其中,歸一化優先級根據靜態優先級、調度優先級和調度策略計算得到

① goodness函數的作用就是根據上述依據計算一個進程的權重,之后調度程序可依據該權重選擇出最值得運行的進程
② schedule函數中對goodness函數的調用式如下圖所示,

prev->active_mm:為前一進程(prev)的active_mm字段
Linux將進程的虛擬地址空間劃分為用戶態和內核態,每當進程上下文切換時,用戶態虛擬地址空間發生切換,以便與當前運行的進程匹配;而內核態虛擬地址空間是所有進程共享的,不會發生切換
task_struct中包含2個mm_struct類型的指針,即mm和active_mm

其中mm指向進程的用戶態虛擬地址空間,所以內核線程的mm為NULL;而active_mm字段指向進程最近一次使用的地址空間,調度程序可依據active_mm字段進行優化
這種情況主要發生在從用戶進程切換到內核進程的場景,此時會將切換出去的用戶進程的active_mm存放在內核進程的active_mm字段,這樣內核空間就知道當前的用戶空間包含了什么
而這里的優化空間就是如果內核線程之后運行的用戶進程與之前是同一個,那么TLB中的信息仍然有效
https://www.cnblogs.com/linhaostudy/archive/2018/11/04/9904846.html
static inline int goodness(struct task_struct * p, int this_cpu,
struct mm_struct *this_mm)
{int weight;/** select the current process after every other* runnable process, but before the idle thread.* Also, dont trigger a counter recalculation.*/// 權重初始值為-1weight = -1;// 如果進程調度策略為SCHED_YIELD,則直接返回-1if (p->policy & SCHED_YIELD)goto out;/** Non-RT process - normal case first.*/// 對于普通分時進程,返回的就是剩余ticks數// 當進程時間片耗盡時,返回0if (p->policy == SCHED_OTHER) {/** Give the process a first-approximation goodness value* according to the number of clock-ticks it has left.** Don't do any other calculations if the time slice is* over..*/weight = p->counter;// 時間片耗盡,返回0if (!weight)goto out;
#ifdef CONFIG_SMP/* Give a largish advantage to the same processor... *//* (this is equivalent to penalizing other processors) */if (p->processor == this_cpu)weight += PROC_CHANGE_PENALTY;
#endif/* .. and a slight advantage to the current MM */// 輕微調整優先級// p->mm == this_mm:該進程的用戶空間就是當前進程,如果讓其繼續// 運行,可減少一次進程切換// !p->mm:該進程沒有用戶空間,是一個內核進程,如果調度其運行,// 無需切換到用戶態if (p->mm == this_mm || !p->mm)weight += 1;// 靜態優先級在權重中的體現weight += 20 - p->nice;goto out;}/** Realtime process, select the first one on the* runqueue (taking priorities within processes* into account).*/// 實時進程直接加1000weight = 1000 + p->rt_priority;
out:return weight;
}說明1:實時進程的權重至少為1000,且與counter和nice無關,所以優先級遠高于普通分時進程

我們寫個小程序,來看下這幾個實時進程的調度策略(這要用到下面一個小節介紹的系統調用),從結果看,系統的實時進程為SCHED_FIFO調度策略,也就是說在沒有優先級更高的進程的情況下,這些實時進程會運行到主動放棄CPU為止

#include <stdio.h>
#include <sched.h>
#include <stdlib.h>int main(int argc, char *argv[])
{pid_t pid = 0;int policy = 0;pid = (pid_t)atoi(argv[1]);policy = sched_getscheduler(pid);if (policy < 0) {perror("get policy error");return -1;}else {switch (policy) {case SCHED_FIFO:printf("SCHED_FIFO\n");break;case SCHED_RR:printf("SCHED_RR\n");break;case SCHED_OTHER:printf("SCHED_OTHER\n");break;default:printf("policy = %d\n", policy);break;}return 0;}
}說明2:普通分時進程的優先級取決于counter和nice,其中,
① counter越小,權重越小。這個就體現了如果進程雖然時間片的消耗,權重會降低,會將優先級讓給剩余時間片較多的進程,這就是為啥counter字段被稱作動態優先級的原因
Linux 2.4內核版本中和調度策略 & 優先級相關的系統調用有如下8個,

我們直接來看這7個系統調用服務例程的實現,理解了內核態的實現,用戶態的調用也就很容易理解了,在需要時可以修改進程的調度策略,使其具有更高的優先級


② sys_sched_setscheduler & sys_sched_setparam

這2個函數都是通過調用setscheduler函數實現的,只是sys_sched_setparam只設置優先級,不設置調度策略,下面看一個setscheduler函數的實現
static int setscheduler(pid_t pid, int policy, struct sched_param *param)
{struct sched_param lp;struct task_struct *p;int retval;retval = -EINVAL;if (!param || pid < 0)goto out_nounlock;retval = -EFAULT;if (copy_from_user(&lp, param, sizeof(struct sched_param)))goto out_nounlock;/** We play safe to avoid deadlocks.*/read_lock_irq(&tasklist_lock); // 保護哈希表spin_lock(&runqueue_lock); // 保護就緒隊列p = find_process_by_pid(pid);retval = -ESRCH;if (!p)goto out_unlock;// 此時就是不設置調度策略,僅設置優先級 if (policy < 0)policy = p->policy;else {retval = -EINVAL;// 檢查要設置的調度策略是否合法if (policy != SCHED_FIFO && policy != SCHED_RR &&policy != SCHED_OTHER)goto out_unlock;}/** Valid priorities for SCHED_FIFO and SCHED_RR are 1..99, valid* priority for SCHED_OTHER is 0.*/retval = -EINVAL;// 實時優先級有效值為[1, 99]// 如果是普通分時進程,動態優先級的值必須為0if (lp.sched_priority < 0 || lp.sched_priority > 99)goto out_unlock;if ((policy == SCHED_OTHER) != (lp.sched_priority == 0))goto out_unlock;// 檢查是否有設置的權限retval = -EPERM;if ((policy == SCHED_FIFO || policy == SCHED_RR) && !capable(CAP_SYS_NICE))goto out_unlock;if ((current->euid != p->euid) && (current->euid != p->uid) &&!capable(CAP_SYS_NICE))goto out_unlock;// 設置調度策略與優先級retval = 0;p->policy = policy;p->rt_priority = lp.sched_priority;// 如果被設置優先級的進程在就緒隊列中,將其移至隊首if (task_on_runqueue(p))move_first_runqueue(p);// 由于設置了目標進程的優先級,可能出現優先級更高的進程可運行// 所以觸發調度current->need_resched = 1;out_unlock:spin_unlock(&runqueue_lock);read_unlock_irq(&tasklist_lock);out_nounlock:return retval;
}




該函數用于返回SCHED_RR類型進程的時間片值,從實現分析需要注意2點,
a. 如果是SCHED_FIFO類型進程,返回0,因為這類進程不是分時進程(其實分時進程都會返回時間值,不一定是SCHED_RR進程)

b. nice系統調用的參數increment是一個增量,最終的計算結果會歸一化到合法范圍
asmlinkage void schedule(void)
{struct schedule_data * sched_data;// prev:前一進程,即要調度走的進程// next:后一進程,即要調度執行的進程struct task_struct *prev, *next, *p;struct list_head *tmp;int this_cpu, c;// 如果當前進程active_mm為空,出錯if (!current->active_mm) BUG();
need_resched_back:prev = current;this_cpu = prev->processor;// 在進程上下文調度,出錯if (in_interrupt())goto scheduling_in_interrupt;// 釋放全局內核鎖,并開this_cpu的中斷release_kernel_lock(prev, this_cpu);/* Do "administrative" work here while we don't hold any locks */// 如果此時有軟中斷要處理,則先處理軟中斷// 處理完成后返回handler_softirq_back標簽if (softirq_active(this_cpu) & softirq_mask(this_cpu))goto handle_softirq;
handle_softirq_back:/** 'sched_data' is protected by the fact that we can run* only one process per CPU.*/sched_data = & aligned_data[this_cpu].schedule_data;spin_lock_irq(&runqueue_lock); // 保護就緒隊列/* move an exhausted RR process to be last.. */// 如果要調度走的是SCHED_RR進程,如果該進程時間片耗盡,// 將其移至就緒隊列隊尾,然后返回move_rr_back標簽if (prev->policy == SCHED_RR)goto move_rr_last;
move_rr_back:switch (prev->state) {// 如果要被調度走的進程此時被信號打斷,則恢復TASK_RUNNING狀態// 此時可繼續參與調度case TASK_INTERRUPTIBLE:if (signal_pending(prev)) {prev->state = TASK_RUNNING;break;}// 其余情況則移出就緒隊列default:del_from_runqueue(prev);case TASK_RUNNING:}// 清除前一進程的請求調度標志prev->need_resched = 0;/** this is the scheduler proper:*/repeat_schedule:/** Default process to select..*/next = idle_task(this_cpu);c = -1000;// 如果前一進程可以繼續運行,則計算器權重,并默認后一進程就是前一進程// 即不發生進程切換(除非有更高優先級的進程)if (prev->state == TASK_RUNNING)goto still_running;still_running_back:// 遍歷就緒隊列,找到權重最大的進程list_for_each(tmp, &runqueue_head) {p = list_entry(tmp, struct task_struct, run_list);if (can_schedule(p, this_cpu)) {int weight = goodness(p, this_cpu, prev->active_mm);if (weight > c)c = weight, next = p;}}/* Do we need to re-calculate counters? */// 如果返回的c為0,說明,// 1. 就緒隊列中沒有實時進程(實時進程的權重至少為1000)// 2. 所有普通分時進程的時間片均耗盡// 此時需要重新設置所有進程的時間片,然后返回repeat_schedule重新調度if (!c)goto recalculate;/** from this point on nothing can prevent us from* switching to the next task, save this fact in* sched_data.*/sched_data->curr = next;
#ifdef CONFIG_SMPnext->has_cpu = 1;next->processor = this_cpu;
#endifspin_unlock_irq(&runqueue_lock);if (prev == next)goto same_process;#ifdef CONFIG_SMP/** maintain the per-process 'last schedule' value.* (this has to be recalculated even if we reschedule to* the same process) Currently this is only used on SMP,* and it's approximate, so we do not have to maintain* it while holding the runqueue spinlock.*/sched_data->last_schedule = get_cycles();/** We drop the scheduler lock early (it's a global spinlock),* thus we have to lock the previous process from getting* rescheduled during switch_to().*/#endif /* CONFIG_SMP */kstat.context_swtch++;/** there are 3 processes which are affected by a context switch:** prev == .... ==> (last => next)** It's the 'much more previous' 'prev' that is on next's stack,* but prev is set to (the just run) 'last' process by switch_to().* This might sound slightly confusing but makes tons of sense.*/prepare_to_switch();{struct mm_struct *mm = next->mm;struct mm_struct *oldmm = prev->active_mm;// 如果后一進程為內核進程,沒有用戶虛擬空間// 此時借用前一進程的用戶虛擬空間if (!mm) {if (next->active_mm) BUG();next->active_mm = oldmm;atomic_inc(&oldmm->mm_count);enter_lazy_tlb(oldmm, next, this_cpu);// 后一進程為普通進程,需要切換用戶虛擬空間} else {if (next->active_mm != mm) BUG();switch_mm(oldmm, mm, next, this_cpu);}// 如果被切換走的是內核進程,則歸還他借用的用戶虛擬空間// mm_struct的共享計數減1if (!prev->mm) {prev->active_mm = NULL;mmdrop(oldmm);}}/** This just switches the register state and the* stack.*/// 實際進行進程切換,體系結構相關switch_to(prev, next, prev);__schedule_tail(prev);same_process:reacquire_kernel_lock(current);if (current->need_resched)goto need_resched_back;return;recalculate:{struct task_struct *p;spin_unlock_irq(&runqueue_lock);read_lock(&tasklist_lock);for_each_task(p)p->counter = (p->counter >> 1) +NICE_TO_TICKS(p->nice);read_unlock(&tasklist_lock);spin_lock_irq(&runqueue_lock);}goto repeat_schedule;still_running:c = goodness(prev, this_cpu, prev->active_mm);next = prev;goto still_running_back;handle_softirq:do_softirq();goto handle_softirq_back;move_rr_last:if (!prev->counter) {prev->counter = NICE_TO_TICKS(prev->nice);move_last_runqueue(prev);}goto move_rr_back;scheduling_in_interrupt:printk("Scheduling in interrupt\n");BUG();return;
}說明1:switch_to實現真正的切換,且實現是與體系結構相關的

當調用完switch_to之后,就會實際切換到后一進程運行,schedule函數中switch_to調用之后的語句需要調度程序又選擇prev進程執行時由prev進程執行
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;// 如果后一進程為內核線程,由于內核線程沒有進程用戶空間
// 所以在進程切換時借用上一進程的用戶空間
if (!mm) {// 此時要運行的內核線程的active_mm應該為空if (next->active_mm) BUG();// 即借用prev->active_mm,prev可能也是內核線程哦next->active_mm = oldmm;// 可見mm_count是內核線程對用戶進程空間的借用次數atomic_inc(&oldmm->mm_count);// 由于即將進入內核線程,將當前CPU置為lazy tlb模式// 因為內核線程并不訪問用戶空間,所以無需刷新頁表enter_lazy_tlb(oldmm, next, this_cpu);
// 后一進程為普通進程,需要切換用戶空間
} else {// 普通進程的mm和active_mm應該相同if (next->active_mm != mm) BUG();switch_mm(oldmm, mm, next, this_cpu);
}// 如果被切換走的是內核線程,則歸還他借用的進程用戶空間
if (!prev->mm) {prev->active_mm = NULL;mmdrop(oldmm);
}內核線程訪問內存時也是需要頁表進行地址轉換的,只是此時要使用的是內核頁表,而內核頁表是所有進程共享的。所以通過借用前一進程的用戶空間,就可以正確訪問內核空間
而正是這種用戶空間的借用,使得切換到內核線程時無需進行頁表集的切換,代價更小(這也是goodness函數中獎勵這種行為的原因)
上文中提到的內核頁表是所有進程共享的,這種共享在實現上就是進程頁表的內核態部分是內核頁表swapper_pg_dir的拷貝(在創建進程的pgd時進行拷貝)
這里就涉及一個如何將內核頁表的修改同步到進程頁表的問題,在Linux內核中,是將該同步推遲到第一次真正訪問vmalloc分配的內核地址空間時,由內核空間的缺頁異常進行處理
https://blog.csdn.net/l1259863243/article/details/54175300

可見switch_mm函數只做2件事兒,處理lazy tlb + 切換頁表


可將當mm_struct的mm_count字段為0時,將釋放該結構
隨著Linux內核版本的更新,調度程序越來越復雜,此處不再詳細說明新版調度程序的實現方式,只是列出Linux 2.4版本調度程序的不足,以指明改進的方向
① 即使時間片耗盡的進程,依然在就緒隊列中,這就使得這些不可能被調度的進程仍然參與調度,浪費了遍歷就緒隊列的時間
② 調度算法與就緒隊列的長度密切相關,隊列越長,挑選一個進程的時間就越長,不適合用在硬實時系統中
① 多個處理器的進程放在同一個就緒隊列中,使得就緒隊列稱為臨界資源,各個處理器為等待進入就緒隊列而降低了系統效率
① Linux 2.4版本是不支持內核搶占的,Linux 2.6版本才開始支持
② 上文中將task_struct結構的need_resched字段置為1實現的是用戶態搶占,此時如果內核從系統調用或者中斷處理程序返回用戶態,都會檢查need_resched標志,如果被設置,內核會選擇一個最合適的進程投入運行
③ 所有搶占,包括內核態搶占,都是有時機的,比如從中斷處理程序返回等。在支持內核搶占的內核中,只要重新調度是安全的,就可以搶占當前正在運行的任務
https://blog.csdn.net/gatieme/article/details/51872618



② O(1)調度器的基本優化思路就是把原先就緒隊列上的單個鏈表根據優先級組織為多個鏈表,每個優先級的進程被加入不同鏈表中
③ O(1)支持140個優先級,因此隊列成員中有140個分別表示各個優先級的鏈表表頭;bitmap表示各個優先級進程鏈表是空還是非空;nr_active表示這個隊列中有多少任務
在這些隊列中,100 ~ 139是普通進程的優先級,其余為實時進程優先級,由于不同類型的進程被區分開,普通進程不會影響實時進程的調度
④ 就緒隊列中有2個優先級隊列,active隊列管理時間片還有剩余的進程;expired隊列管理時間片耗盡的進程
隨著系統運行,active隊列的任務耗盡時間片,被掛入expired隊列,當active隊列為空時,兩個隊列互換,開始新一輪的調度過程

① 系統中所有就緒進程首先經過負載均衡模塊,然后掛入各個CPU上的就緒隊列
② 主調度器(即schedule函數)和周期性調度器驅動CPU上的調度行為,其基本思路是從active隊列的bitmap中尋找第一個非空的進程鏈表(即當前優先級最高的進程鏈表),讓后調度該鏈表的第一個結點進程,因此時間復雜度為O(1)

① 通過負載均衡模塊將各個就緒狀態的任務分配到各個CPU的就緒隊列
② 各個CPU上的主調度器(Main scheduler)和周期性調度器(Tich scheduler)的驅動下進行單個CPU上的調度
調度器處理的任務各不相同,有實時任務(RT task)、普通任務(Normal task)和最后期限任務(Deadline task)等,無論是哪種任務,他們都有共同的邏輯,這部分就構成了核心調度層
各種特定類型的調度器可以定義自己的調度類(sched_class),并以鏈表形式加入到系統中。這樣就實現了機制和策略的分離,用戶可以根據自己的場景定義特定的調度器,而不需要改動核心調度層的邏輯

check_preempt_curr:表示當前CPU上正在運行的進程是否可以被搶占
pick_next_task:從就緒隊列中選擇一個最適合運行的進程,是調度器類的核心操作

在copy_process函數中會調用sched_fork函數,該函數中會設置新創建進程的調度類

② CFS調度器沒有時間片的概念,而是分配CPU使用時間的比例
③ 在實現層面,CFS通過每個進程的虛擬運行時間(vruntime)來衡量哪個進程最值得被調度,而虛擬運行時間是通過進程的實際運行時間和進程的權重(weight)計算出來的
④ CFS中的就緒隊列是一顆以虛擬運行時間為鍵值的紅黑樹,虛擬運行時間越小的進程越靠近整個紅黑樹的最左端,因此調度器每次選擇位于紅黑樹最左端的進程運行

⑤ 在CFS調度器中,弱化了進程優先級的概念,而是強調進程的權重。一個進程權重越大,越說明這個進程需要運行,因此他的虛擬運行時間就越小,這樣被調度的機會就越大
① 由上文可知,0號進程是系統中唯一一個靜態分配的進程,他的PCB被靜態地分配在內核數據段中,永遠不會被撤銷
而其他進程的PCB在運行的過程中由系統根據當前的內存狀況隨機分配,撤銷時再歸還給系統
③ start_kernel函數調用rest_init函數之后,最終會進入cpu_idle函數,至此start_kernel就退化為idle process
④ 0號進程在很多鏈表中起到鏈表頭的作用,當就緒隊列中沒有其他進程時,就會調度0號進程,cpu_idle中會進行pm_idle操作,以達到節電的目的
① 1號進程由rest_init函數調用kernel_thread函數生成
![]()
② kernel_init在完成進一步初始化之后,會運行用戶態的init進程,至此1號進程成為所有用戶態進程的祖先進程
③ 首先會通過do_execve函數嘗試運行/init,之后會按順序嘗試,只要有1個進程能運行成功即可

① 2號進程也由rest_int函數調用kernel_thread函數生成
![]()
② kthreadd進程在kthread_create_list鏈表為空時進入睡眠,當被喚醒時,根據請求建立內核進程,進而成為所有內核進程的祖先進程

③ 喚醒2號進程的方式就是調用kthread_create函數請求創建新的內核進程,該函數在將請求加入kthread_create_list列表后,就會喚醒2號進程


② 進程和線程幾乎共享所有資源,包括代碼段、數據段、進程地址空間和打開的文件等,線程只擁有自己的寄存器和棧
下面就分析一下Linux內核中如何實現這種資源的共享,以及如何將線程作為輕量級的運行單位
LINUX系統,
Linux內核使用唯一的數據結構task_struct來表示進程、線程和內核線程,并使用相同的調度算法對這三者進行調度(這就體現了為什么線程是獨立運行的基本單位)

① 創建進程和創建線程在用戶態使用不同的API,在內核態也對應不同的系統調用
② 但是最終都是調用do_fork函數實現新進程 / 線程的創建,只是調用時傳遞的參數不同

clone_flags:拷貝參數及各種各樣的標志信息,這是不同調用者的主要差別,即從父進程中拷貝不同的資源
stack_start:表示把用戶態棧指針賦值給子進程的esp寄存器(調用進程應該總是為子進程分配新的棧)
regs:指向通用寄存器組的指針,通用寄存器的值在從用戶態切換到內核態時被保存在內核態棧中

① 指定SIGCHLD標志,標識要生成子進程,此時父進程會以寫時拷貝技術和子進程共享資源
進程上下文切換和線程上下文切換,5.2.3.3 sys_vfork創建進程

① 指定SIGCHLD標志的含義與sys_fork相同
② 指定CLONE_VFORK標志,標識父進程要等待子進程先運行,之后再繼續運行

① sys_clone中指定的標志通過寄存器傳遞,實際內容為CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND
② 指定CLONE_FS,標識共享根目錄和當前工作目錄所在的表

無論是創建內核進程還是用戶進程,最終都是由內核態的do_fork函數完成,此處簡介該函數都做了哪些工作


1. 調用alloc_task_struct在slab上分配PCB
2. 調用alloc_thread_info在buddy上分配進程內核棧
3. 把父進程PCB的內容拷貝到剛剛分配的新進程PCB中,此時二者是完全相同的
4. 檢查新創建這個子進程后,當前用戶所擁有的資源數量有沒有超過限制
5. 將子進程狀態設置為TASK_UNINTERRUPTIBLE,以確保他不會被立即調度
7. 更新不能從父進程繼承的PCB其他域,比如進程間的親屬關系等
8. 根據傳遞的clone_flags拷貝或共享打開的文件、文件系統信息、信號處理函數、進程的虛擬地址空間等
11. 把子進程PCB的狀態置為TASK_RUNNING,并調用wake_up_process,把子進程插入到就緒隊列
13. 返回子進程的PID,這個PID最終由用戶態下的父進程讀取
Linux的fork使用寫時拷貝(Copy-on-write)來實現,在do_fork中內核并沒有把父進程的全部資源給子進程復制一份,而是將這些內容設置為只讀狀態,當父進程或子進程試圖修改這些內容是,內核才在修改之前將被修改的部分進行拷貝(具體可見下一章內存管理筆記)
fork之后的父子進程執行的先后順序是由調度程序決定的,但是根據我們對Linux 2.4版本調度程序的分析,調度程序是傾向于讓父進程先運行的,因為運氣好的話可以減少一次進程切換(我進行了一個簡單測試,也確實是父進程先運行)
但是從寫時拷貝的角度分析,先運行子進程可以減少浪費,主要有2點依據,
① 如果父進程隨后修改了共享的內容,就必須為子進程單獨復制一份
② 子進程被創建后,一般都是調用execve函數運行一個新的程序,所以先運行子進程可以避免不必要的拷貝
如果想控制子進程先運行,可以使用vfork系統調用,在do_fork的內核實現中,如果指定了CLONE_VFORK標志,父進程就會等待子進程運行之后再運行

注:由于fork使用寫時拷貝技術,vfork在克隆父進程地址空間上的優勢已不再存在
使用uptime或top命令可以查看當前系統的平均負載,load_average會分別顯示最近1分鐘、5分鐘和15分鐘的CPU平均負載值

單位時間內系統處于可運行狀態(TASK_RUNNING)和不可打斷狀態(TASK_UNINTERRUPTIBLE)的平均進程數
系統進程,
以車道模擬系統負載,當系統負載達到1.0時,說明任務已將CPU占滿;當系統負載達到1.7時,說明等待的任務達到已經超過CPU可執行任務的70%
① 多CPU可分為多處理器和多核處理器,多處理器即計算機系統中有多個物理CPU;多核處理器表示單個物理CPU中有多個單獨的并行工作單元
② 使用nproc(print the number of processing units available)命令可以查看當前系統的計算單元個數

③ 多核心相當于多車道

特別注意:該模塊調用的很多函數在舊版本內核中沒有,實測時使用的系統為Ubuntu 16.04(Linux 4.15.0)
系統負載值存儲在avenrun數組中,分別存儲最近1分鐘、5分鐘和15分鐘的系統負載
![]()
此處說明2點,
① Linux內核不支持浮點數,所以以unsigned long類型存儲系統負載,其中低11位存儲的是小數部分
② 考慮到有些版本可能沒有將avenrun數組export symbol,代碼中使用kallsyms_lookup_name函數獲取其地址
static unsigned long *ptr_avenrun;ptr_avenrun = (void *)kallsyms_lookup_name("avenrun");if (!ptr_avenrun)return -EINVAL;#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
#define LOAD_INT(x) ((x) >> FSHIFT)
#define LOAD_FRAC(x) LOAD_INT(((x) & (FIXED_1-1)) * 100)static void check_load(void)
{static ktime_t last;u64 ms;int load = LOAD_INT(ptr_avenrun[0]); // 最近1分鐘的Load值// 當負載小于3時,直接返回if (load < 3)return;/*** 如果上次打印時間與當前時間相差不到20秒,就直接退出*/ms = ktime_to_ms(ktime_sub(ktime_get(), last));if (ms < 20 * 1000)return;last = ktime_get();print_all_task_stack(); // 打印所有線程的調用棧
}struct hrtimer timer;static enum hrtimer_restart monitor_handler(struct hrtimer *hrtimer)
{enum hrtimer_restart ret = HRTIMER_RESTART; // 重啟定時器check_load(); // 檢查系統負載// 重置定時器到期時間為當前時間 + 10mshrtimer_forward_now(hrtimer, ms_to_ktime(10));return ret;
}static void start_timer(void)
{hrtimer_init(&timer, CLOCK_MONOTONIC, HRTIMER_MODE_PINNED);timer.function = monitor_handler;// 定時器到期時間為當前時間 + 10mshrtimer_start_range_ns(&timer, ms_to_ktime(10), 0,HRTIMER_MODE_REL_PINNED);
}#define BACKTRACE_DEPTH 20static void print_all_task_stack(void)
{struct task_struct *g, *p;unsigned long backtrace[BACKTRACE_DEPTH]; // 最多獲取20層調用棧struct stack_trace trace;memset(&trace, 0, sizeof(trace));memset(backtrace, 0, BACKTRACE_DEPTH * sizeof(unsigned long));trace.max_entries = BACKTRACE_DEPTH;trace.entries = backtrace; // 使用backtrace數組存儲調用棧printk("\tLoad: %lu.%02lu, %lu.%02lu, %lu.%02lu\n",LOAD_INT(ptr_avenrun[0]), LOAD_FRAC(ptr_avenrun[0]),LOAD_INT(ptr_avenrun[1]), LOAD_FRAC(ptr_avenrun[1]),LOAD_INT(ptr_avenrun[2]), LOAD_FRAC(ptr_avenrun[2]));printk("current: %d --> %s\n", current->pid, current->comm);printk("dump all task: \n");// 上RCU讀鎖rcu_read_lock();printk("dump running task.\n");do_each_thread(g, p) {if (p->state == TASK_RUNNING) {printk("running task, comm: %s, pid %d\n",p->comm, p->pid);// 每次打印都要初始化backtrace,否則會打印其他線程的調用棧memset(&trace, 0, sizeof(trace));memset(backtrace, 0, BACKTRACE_DEPTH *sizeof(unsigned long));trace.max_entries = BACKTRACE_DEPTH;trace.entries = backtrace;// 獲取并打印線程調用棧save_stack_trace_tsk(p, &trace);print_stack_trace(&trace, 0);}} while_each_thread(g, p);printk("dump uninterrupted task.\n");do_each_thread(g, p) {if (p->state & TASK_UNINTERRUPTIBLE) {printk("uninterrupted task, comm: %s, pid %d\n",p->comm, p->pid);memset(&trace, 0, sizeof(trace));memset(backtrace, 0, BACKTRACE_DEPTH *sizeof(unsigned long));trace.max_entries = BACKTRACE_DEPTH;trace.entries = backtrace;save_stack_trace_tsk(p, &trace);print_stack_trace(&trace, 0);}} while_each_thread(g, p);rcu_read_unlock();
}說明:do_each_thread & while_each_thread宏
do_each_thread(g, p) {} while_each_thread(g, p);
展開后形式如下,
// 遍歷過程也體現出為何要上rcu讀鎖#define next_task(p) \list_entry_rcu((p)->tasks.next, struct task_struct, tasks)static inline struct task_struct *next_thread(const struct task_struct *p)
{return list_entry_rcu(p->thread_group.next,struct task_struct, thread_group);
}for (g = t = &init_task; (g = t = next_task(g)) != &init_task;) do {} while ((t = next_thread(t)) != g)此處就體現出了Linux內核中多進程和多線程的關系,即一個進程之中的多個線程tgid字段相同但pid字段不同
根據代碼,在Linux內核中,先按進程組織在tasks字段表示的鏈表中;進程的線程又組織在進程的thread_group鏈表中

驗證:Linux中進程與線程的組織方式
上文中提到Linux內核中先按進程組織,然后線程又被組織在進程中,也就是說進程起到了線程組的作用,下面通過實驗加以驗證
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/syscall.h>// gettid系統調用沒有封裝例程
#define gettid() syscall(__NR_gettid)void *th_fn(void *arg)
{printf("th_fn run\n");printf("th_fn getpid() = %d\n", getpid());printf("th_fn gettid() = %ld\n", gettid());sleep(1000);return (void *)0;
}int main(void)
{pthread_t thread;printf("main thread run\n");printf("main getpid() = %d\n", getpid());printf("main gettid() = %ld\n", gettid());pthread_create(&thread, NULL, th_fn, NULL);sleep(1000);return 0;
}從用戶態打印結果分析,主線程和子線程是兩個調度實體,對應內核態中的兩個task_struct結構

之后加載上文中提到的打印進程鏈表的內核模塊,從內核態打印分析,進程鏈表中只有主線程的task_struct,并沒有子線程的task_struct

結論:
① Linux中的進程是資源分配的基本單位,線程是調度的基本單位
② 進程內的所有線程構成線程組,其中主線程是線程組的組長,主線程的pid就是該線程組的tgid
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态