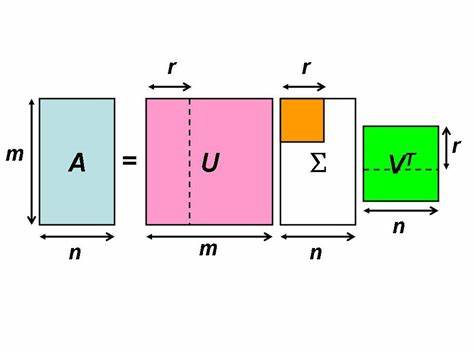
SVD奇异值分解里具体说了SVD的基本原理解读,本次实战分析SVD的应用
数据说明:
本次数据使用的是用户听音乐的数据,具体数据有需要的可以关注公众号:不懂乱问(Andy_shenzl)后台留言。
回复:music。自主获取
python 解压。当然可以自己在网上下载。
import 本次使用的数据量还是比较大的,倒入大概需要1分钟的时间
数据解读:
triplet_dataset.shape=(48373586, 3)
数据有近5000W行数据,3列
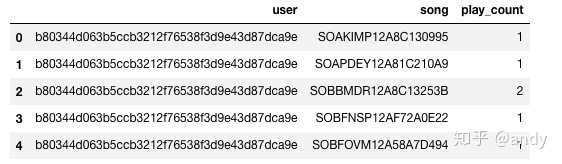
数据变量分别为用户名、歌曲名称、听歌次数
Python 音乐?还有一个歌曲的详细信息表,存储在数据库格式文件里
conn 表的名称为:[('songs',)]
track_metadata_df shape=(999056, 14)
查看下数据格式,去掉一些无用字段,只保留有用信息
del将两份数据合并在一起
tt 过程比较慢,大概需要1分半钟
triplet_dataset_merged.shape=(48373586, 8)
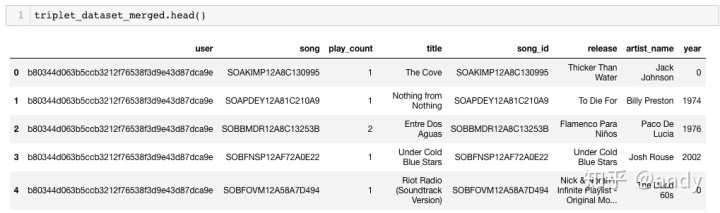
推荐系统需要有用户对物品的打分,这里数据没有打分字段
php和python?所以我们需要处理一下,把听歌的次数作为评分,听的次数越多认为越喜欢
当然如果根据绝对的听歌次数会有失数据的平衡,所以我们用每个用户听每首歌的次数比上该用户听歌总次数的比值作为用户对当前歌曲的评分
#计算每个用户听歌的总次数
这样我们对数据的基本处理完成了
SVD需要矩阵进行求解,所以我们需要对处理好的数据转换成矩阵格式
#重新定义
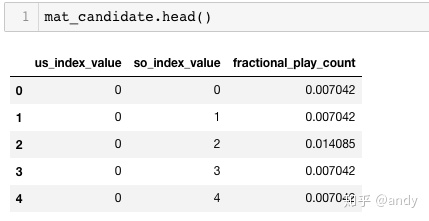
构造矩阵
data_sparse:
<1019318x384546 sparse matrix of type '<class 'numpy.float64'>'
with 48373586 stored elements in COOrdinate format>
#导入相关包
定义两个函数来进行下面的操作
#SVD求解,之前讲过了
python django。定义参数:
K=10
urm = data_sparse
MAX_PID = urm.shape[1]
MAX_UID = urm.shape[0]
UuTest是随机选取的几个用户数据进行推荐
def 可能运算比较慢,我们调用concurrent.futures加速
from 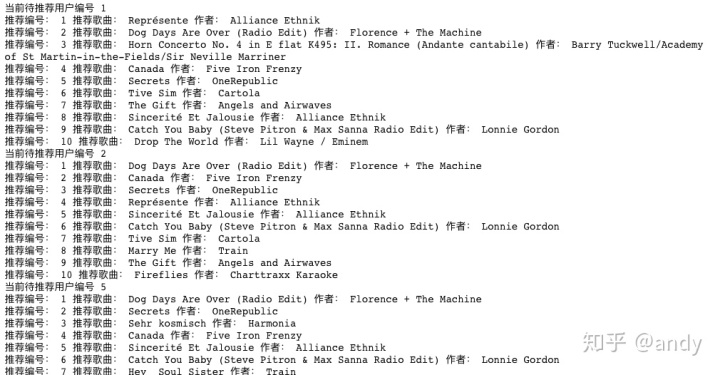

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态









![[Ahoi2013]连通图](http://www.lydsy.com/JudgeOnline/upload/201306/1%283%29.jpg)