在数据分析工作中,Pandas 的使用频率是很高的,一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 json 的契合度很高,转换起来就很方便。另一方面,如果我们日常的数据清理工作不是很复杂的话,你通常用几句 Pandas 代码就可以对数据进行规整。
Pandas 可以说是基于 NumPy 构建的含有更高级数据结构和分析能力的工具包。在 NumPy 中数据结构是围绕 ndarray 展开的,那么在 Pandas 中的核心数据结构是什么呢?
下面主要给你讲下 Series 和 DataFrame 这两个核心数据结构,他们分别代表着一维的序列和二维的表结构。基于这两种数据结构,Pandas 可以对数据进行导入、清洗、处理、统计和输出。
数据分析网站。
如图,我们采集到的数据,很可能有许多缺失值,异常值等,这就需要我们对这些数据进行整理,也就是数据清洗。
由于数据很多而且很杂,所以我们精确的统一规则是比较难的,所以可以将规则总结为以下 4 个关键点
Series 是个定长的字典序列。说是定长是因为在存储的时候,相当于两个 ndarray,这也是和字典结构最大的不同。因为在字典的结构里,元素的个数是不固定的。
Series 有两个基本属性:index 和 values。在 Series 结构中,index 默认是 0,1,2,……递增的整数序列,当然我们也可以自己来指定索引,比如index=[‘a’, ‘b’, ‘c’, ‘d’]
数据清洗不包括什么。
这个例子中,x1 中的 index 采用的是默认值,x2 中 index 进行了指定。我们也可以采用字典的方式来创建 Series,比如:

它包括了行索引和列索引,我们可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
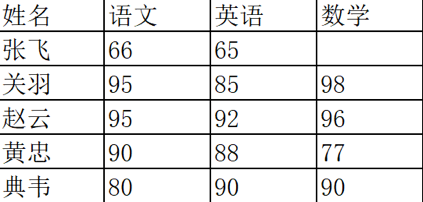
我们虚构一个王者荣耀考试的场景,想要输出几位英雄的考试成绩:


在后面的案例中,我一般会用 df, df1, df2 这些作为 DataFrame 数据类型的变量名,我们以例子中的 df2 为例,列索引是[‘English’, ‘Math’, ‘Chinese’],行索引是[‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’]
数据清洗的方法有哪些?Pandas 允许直接从 xlsx,csv 等文件中导入数据,也可以输出到 xlsx, csv 等文件,非常方便。

需要说明的是,在运行的过程可能会存在缺少 xlrd 和 openpyxl 包的情况,到时候如果缺少了,可以在命令行模式下使用“pip install”命令来进行安装。
数据清洗是数据准备过程中必不可少的环节,Pandas 也为我们提供了数据清洗的工具,在后面数据清洗的章节中会给你做详细的介绍,这里简单介绍下 Pandas 在数据清洗中的使用方法。
还是以上面这个王者荣耀的数据为例。
excel数据分析在哪里、
Pandas 提供了一个便捷的方法 drop() 函数来删除我们不想要的列或行。比如我们想把“语文”这列删掉。


如果你想对 DataFrame 中的 columns 进行重命名,可以直接使用 rename(columns=new_names, inplace=True) 函数,比如我把列名 Chinese 改成 YuWen,English 改成 YingYu。

数据采集可能存在重复的行,这时只要使用 drop_duplicates() 就会自动把重复的行去掉

数据清洗的目的。这是个比较常用的操作,因为很多时候数据格式不规范,我们可以使用 astype 函数来规范数据格式,比如我们把 Chinese 字段的值改成 str 类型,或者 int64 可以这么写:

想要删除数据间的空格,可以使用 strip 函数:
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。

pandas数据分析实例、大小写是个比较常见的操作,比如人名、城市名等的统一都可能用到大小写的转换,在 Python 里直接使用 upper(), lower(), title() 函数,方法如下:

数据量大的情况下,有些字段存在空值 NaN 的可能,这时就需要使用 Pandas 中的 isnull 函数进行查找。比如,我们输入一个数据表如下:
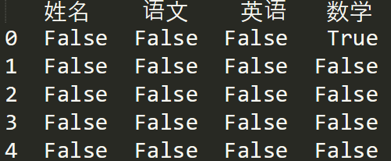
如果我们想看下哪个地方存在空值 NaN,可以针对数据表 df 进行 df.isnull(),结果如下:
如果我想知道哪列存在空值,可以使用 df.isnull().any(),结果如下
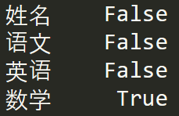
apply 函数是 Pandas 中自由度非常高的函数,使用频率也非常高。
比如我们想对 name 列的数值都进行大写转化可以用:
df['name'] = df['name'].apply(str.upper)
我们也可以定义个函数,在 apply 中进行使用。比如定义 double_df 函数是将原来的数值 *2 进行返回。然后对 df1 中的“语文”列的数值进行 *2 处理,可以写成:
def double_df(x):return 2*x
df1[u'语文'] = df1[u'语文'].apply(double_df)
如何数据分析,我们也可以定义更复杂的函数,比如对于 DataFrame,我们新增两列,其中’new1’列是“语文”和“英语”成绩之和的 m 倍,'new2’列是“语文”和“英语”成绩之和的 n 倍,我们可以这样写:
def plus(df,n,m):df['new1'] = (df[u'语文']+df[u'英语']) * mdf['new2'] = (df[u'语文']+df[u'英语']) * nreturn df
df1 = df1.apply(plus,axis=1,args=(2,3,))
其中 axis=1 代表按照列为轴进行操作,axis=0 代表按照行为轴进行操作,args 是传递的两个参数,即 n=2, m=3,在 plus 函数中使用到了 n 和 m,从而生成新的 df。
Pandas 和 NumPy 一样,都有常用的统计函数,如果遇到空值 NaN,会自动排除
常用的统计函数包括:

表格中有一个 describe() 函数,统计函数千千万,describe() 函数最简便。它是个统计大礼包,可以快速让我们对数据有个全面的了解。下面我直接使用 df1.descirbe() 输出结果为:

有时候我们需要将多个渠道源的多个数据表进行合并,一个 DataFrame 相当于一个数据库的数据表,那么多个 DataFrame 数据表的合并就相当于多个数据库的表合并。
大数据分析、比如我要创建两个 DataFrame并将其合并,有五种方式:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = DataFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
比如我们可以基于 name 这列进行连接。

inner 内链接是 merge 合并的默认情况,inner 内连接其实也就是键的交集,在这里 df1, df2 相同的键是 name,所以是基于 name 字段做的连接:

如何清洗数据?左连接是以第一个 DataFrame 为主进行的连接,第二个 DataFrame 作为补充。

右连接是以第二个 DataFrame 为主进行的连接,第一个 DataFrame 作为补充。
外连接相当于求两个 DataFrame 的并集。

和 NumPy 一样,Pandas 有两个非常重要的数据结构:Series 和 DataFrame。
什么是数据。使用 Pandas 可以直接从 csv 或 xlsx 等文件中导入数据,以及最终输出到 excel 表中。
我重点介绍了数据清洗中的操作,当然 Pandas 中同样提供了多种数据统计的函数。最后我们介绍了如何将数据表进行合并,以及在 Pandas 中使用 SQL 对数据表更方便地进行操作。
Pandas 包与 NumPy 工具库配合使用可以发挥巨大的威力,正是有了 Pandas 工具,Python 做数据挖掘才具有优势。

以上知识pandas的很小一部分语法,还有更多的我总结如下:
pandas练习题(简单题)
原创pandas练习题(中等题)
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

下面的StudentService.java实现了 通过JDBC对表STUDENTS的SELECT 和INSERT操作:

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态