編輯距離
r語言中文文本相似性計算?編輯距離(Edit Distance),又稱Levenshtein距離,是指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數。編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符。一般來說,編輯距離越小,兩個串的相似度越大。
例如將kitten一字轉成sitting:('kitten' 和 ‘sitting' 的編輯距離為3)
相似文本生成?sitten (k→s)
sittin (e→i)
短文本?sitting (→g)
Python中的Levenshtein包可以方便的計算編輯距離
包的安裝: pip install python-Levenshtein
我們來使用下:
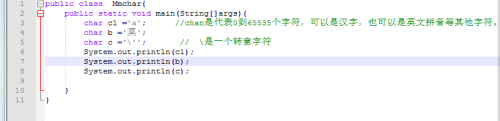
# -*- coding:utf-8 -*-
import Levenshtein
texta = '艾倫 圖靈傳'
textb = '艾倫?圖靈傳'
print Levenshtein.distance(texta,textb)
上面的程序執行結果為3,但是只改了一個字符,為什么會發生這樣的情況?
原因是Python將這兩個字符串看成string類型,而在 string 類型中,默認的 utf-8 編碼下,一個中文字符是用三個字節來表示的。
解決辦法是將字符串轉換成unicode格式,即可返回正確的結果1。
# -*- coding:utf-8 -*-
import Levenshtein
texta = u'艾倫 圖靈傳'
textb = u'艾倫?圖靈傳'
print Levenshtein.distance(texta,textb)
接下來重點介紹下保重幾個方法的作用:
Levenshtein.distance(str1, str2)
計算編輯距離(也稱Levenshtein距離)。是描述由一個字串轉化成另一個字串最少的操作次數,在其中的操作包括插入、刪除、替換。算法實現:動態規劃。
Levenshtein.hamming(str1, str2)
計算漢明距離。要求str1和str2必須長度一致。是描述兩個等長字串之間對應位置上不同字符的個數。
Levenshtein.ratio(str1, str2)
計算萊文斯坦比。計算公式 r = (sum – ldist) / sum, 其中sum是指str1 和 str2 字串的長度總和,ldist是類編輯距離。注意這里是類編輯距離,在類編輯距離中刪除、插入依然+1,但是替換+2。
Levenshtein.jaro(s1, s2)
計算jaro距離,Jaro Distance據說是用來判定健康記錄上兩個名字是否相同,也有說是是用于人口普查,我們先來看一下Jaro Distance的定義。
兩個給定字符串S1和S2的Jaro Distance為:
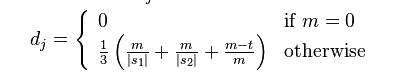
其中的m為s1, s2匹配的字符數,t是換位的數目。
兩個分別來自S1和S2的字符如果相距不超過
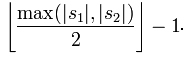
時,我們就認為這兩個字符串是匹配的;而這些相互匹配的字符則決定了換位的數目t,簡單來說就是不同順序的匹配字符的數目的一半即為換位的數目t。舉例來說,MARTHA與MARHTA的字符都是匹配的,但是這些匹配的字符中,T和H要換位才能把MARTHA變為MARHTA,那么T和H就是不同的順序的匹配字符,t=2/2=1。
兩個字符串的Jaro Distance即為:
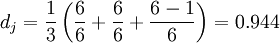
Levenshtein.jaro_winkler(s1, s2)
計算Jaro–Winkler距離,而Jaro-Winkler則給予了起始部分就相同的字符串更高的分數,他定義了一個前綴p,給予兩個字符串,如果前綴部分有長度為ι的部分相同,則Jaro-Winkler Distance為:
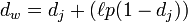
dj是兩個字符串的Jaro Distance
ι是前綴的相同的長度,但是規定最大為4
p則是調整分數的常數,規定不能超過25,不然可能出現dw大于1的情況,Winkler將這個常數定義為0.1
這樣,上面提及的MARTHA和MARHTA的Jaro-Winkler Distance為:
dw = 0.944 + (3 * 0.1(1 ? 0.944)) = 0.961
個人覺得算法可以完善的點:
去除停用詞(主要是標點符號的影響)
針對中文進行分析,按照詞比較是不是要比按照字比較效果更好?
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家學習或者使用python能有所幫助,如果有疑問大家可以留言交流。
本條技術文章來源于互聯網,如果無意侵犯您的權益請點擊此處反饋版權投訴
本文系統來源:php中文網
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态