針對CubeSLAM本博客內容如下,主要是閱讀論文和代碼的一些結果總結,還有一部分總結未完成,同樣使用或者對語義slam感興趣有經驗的歡迎交流,該博客后面也會不段更新cubeslam在自己的數據集上的使用結果和一些避坑指南:
?1. cubeSLAM主要貢獻
?2. 2D->3D的cube轉換
?3. 使用自己的數據集
?
1. 主要貢獻:
這篇文章在語義SLAM中好評較多,主要是與常見的ORBSLAM實現來物體級別的結合;
主要分為兩部分,第一部分為2d部分,主要是可以通過平面的bbox生成出立體的cube,生成出得box帶有9個參數,分別是三維的位置信息(tx,ty,tz),三維的角度信息,以及三維的尺寸信息(dx,dy,dz); 第二個貢獻就是將3維cube與ORBSLAM的結合,將cube的位姿信息也添加到了相機位姿的優化中,因此,最終的BA方程將包括三個優化項,分別是:相機和物體之間,相機位姿和地圖點,以及物體位姿與地圖點之間的誤差,而原ORBSLAM中只包含有第二項,及地圖點在相機位姿下的重投影誤差;
2. 2D->3D的cube轉換
個人覺得這一部分很重要的原因是因為目前3d的物體檢測相對于2d的物體檢測來講,準確度還是有待提高,尤其在SLAM中使用3d點云進行物體檢測 與 單純地使用2d圖像進行檢測所需要的軟件和硬件都有差別,這次測試即為使用2d的boundingbox,傳入到orb_object_slam中進行;
首先說一下檢測大致的思路:輸入為2維的bbox,文件使用格式為(left_up_point_x, left_up_point_y,width,height)的格式, 輸出為3d的cube,也就是上面所說的9個參數,cubeobject的位姿+cube的維度;
具體過程:
a.?cube的坐標系建立為每一個cube的中心,坐標的各個方向為向右為x,向前為y,向上為z,符合右手坐標系,但是與IMU坐標系相對來講有一個90度的旋轉;這點很重要,因為如果需要運行自己的數據機,就要知道最開始相機位姿與地面之間的關系,也就是后面會提到的Init_to_Ground: 有興趣的可以直接參考我在git上提出的問題,有作者本人的回答:https://github.com/shichaoy/cube_slam/issues/32
b.?這篇文章使用來vanishing point來恢復cube的三維及信息;
第一步,vanishing point的定義:
我個人的理解,這些點通俗來講就是物體投影到平面圖像之后的各個邊的交叉點;(按理說,一個空間中存在的立方體的兩個長,兩個寬邊和兩個高邊都是彼此平行的,但是投影到平面之后,發生仿射變換,不再保平行,所以,這些邊的延長線將會相交到一起);
關于VP的定義具體可以參考《多視圖幾何》中的定義,而論文中直接采用來VP的計算為 VPi = KRcol(i); 也就是第i個VP的計算是其相對于相機的旋轉矩陣的第i列以及相機的內參K決定的;
第二步,確定VPs后即可通過VPs來計算二維的角點,也就是立方體的各個角點的二維坐標,通過VPs和bbox的交點計算;
第三步,計算3Dbox,也就是當前cube的pose,這里有一個很重要的投影公式,即
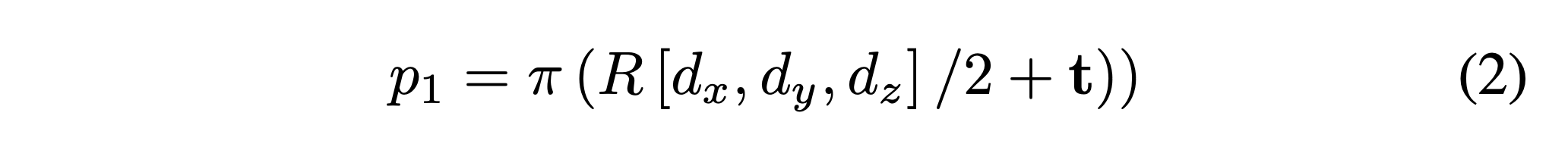
該公式即為立方體的各個角點從object坐標系到camera坐標系的再到圖像坐標系的一個投影,最終的重投影誤差也是由這個公式計算;
這里舉個例子,如果按照右側為x正方向,前側為y正方向,上方為z正方向,則object坐標系的原點位于該cube的中心,那么右前方上面的角點坐標即為(dx,dy,dz),其他點同理,這是在object coordinate下的坐標,經過旋轉矩陣R和平移t即可轉移到相機坐標系下,再經過投影公式pai即轉換至這些角點再圖像中的二維坐標;

用urL數據集獲取定位信息,第四步:定義cost function:
接下來說到如何去計算該object cube的參數O={R,t,d}; 這里列出cost function如下:

該代價函數主要由三部分組成:距離代價函數,角度代價函數,和形狀約束;其中距離代價函數指的是上圖中藍色實線上的點到bbox對角線(也就是右3的那條黑線)之間的距離;角度代價函數即指上圖left圖像的較長線段與vp角度之間的關系;形狀約束主要是指對長寬比過大的cube的懲罰;
這一部分的代碼主要集中在detect_3d_cuboid部分,感興趣的可以對detect_cuboid()函數進一步研究;
3. OBJECT SLAM
這里主要說一下靜態物體的objectslam,動態的部分我還沒有整理,有整理過的伙伴歡迎交流;SLAM部分主要分為兩塊,一是代價函數的介紹,二是代價函數詳解;
第一部分:代價函數;
原本的ORBSLAM的代價函數為最小化地圖點的重投影誤差;而添加了物體之后的slam,其代價函數也對應地增加;具體如下:

數據挖掘的聚類算法。其中第1和第3個為新增的誤差部分;
第一部分物體在相機中的重投影誤差;
這一部分可以分為兩種情況:一種是使用rgbd相機時,object的位置信息比較精確,這時可以在精確值和測量值之間計算一個誤差;二是只有圖像信息,比如單目SLAM的情況;可以將object cube的各個頂點的坐標,由object frame 到camera frame經R,t 進行轉換,再將相機坐標系下的頂點,經過相機的投影矩陣,即可得到對應的其在圖像上的坐標,該坐標與實際的圖像坐標之間的誤差,即obejct的重投影誤差,因此可以作為一個優化項;
第二部分為傳統是地圖點重投影誤差,不再贅述;
第三部分是地圖點與object cube之間存在的約束;
基于如下的原理:如果一個點在圖像中的坐標位于bbox內部,那么該點也就存在與object cube的內部;一般情況下,orbslam保存的地圖點都是在世界坐標系下,將這些地圖點由世界坐標系轉換至相機坐標系中,再轉換至object坐標系中,那么該點在obejct坐標系中的坐標應該是小于各個方向的dimension;因此,這部分也可以構成一個約束項;
運行之前:
labelme數據集?1. 首先說一下cubeslam代碼分幾個模塊,具體每個模塊的作用我在剛開始的時候也是比較迷茫地,所以理解起整個項目會比較慢,具體如下:

2. 下面列舉一些需要的參數, 可以在對應的launch文件中進行修改,也可以自己在ros_mono.cc中按照自己的需求改動:

數據集怎么用、1. 先單獨運行邊緣檢測的部分,進行edge_detection, 可以運行單張圖片,也可以寫一個跑rosbag的,直接將包中的圖像全部轉換;
?2. filter_2d_obj_txts中存放通過yolo或者其他方法檢測出的boundingbox, 文件名和文件格式如下:
?
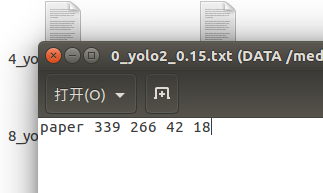
這里面四個數字分別是boundingbox的左上角坐標x,y 以及boundingbox的寬和高;
數據挖掘數據集?當然,這些都可以在代碼中靈活修改,具體對應的代碼是orb_object_slam中的Tracking.cc中(可以通過搜索filter_2d_obj_txts)
3.??raw_imgs 中存放原圖, 這里圖片的名稱需要和代碼中的一致,不太建議修改代碼,因為類似的訪問太多,比較耗費精力
4. 運行orb_object_slam:
? ? ./devel/lib/orb_object_slam/ros_mono path_to_vocabulary/Vocabulary/ORBvoc.bin path_to_camera_matrix/Examples/Monocular/Example.yaml start_id這里的測試中使用的是單目slam,一些參數具體的意義會在后面以表格的形式更新,這里的start_id也是為了方便測試在后期添加的;
在自己的數據集上跑的時候要注意Tracking.cpp中InitToGround的修改,具體參考https://github.com/shichaoy/cube_slam/issues/32;該參數決定來物體的scale,算是間接決定,當參數設置過大時會出現很大的cube,如圖:

python訓練數據集。上圖中圖像的位置基本正確,只是size很大,同時也會導致整個slam的size出現差別;
?
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态