作者 | 柳密 阿里巴巴阿里云智能
本文整理自《Serverless 技術公開課》
hadoop適合部署在docker嗎?導讀:本節課主要介紹如何在 Serverless Kubernetes 集群中低成本運行 Spark 數據計算。首先簡單介紹下阿里云 Serverless Kubernetes 和 彈性容器實例 ECI 這兩款產品;然后介紹 Spark on Kubernetes;最后進行實際演示。
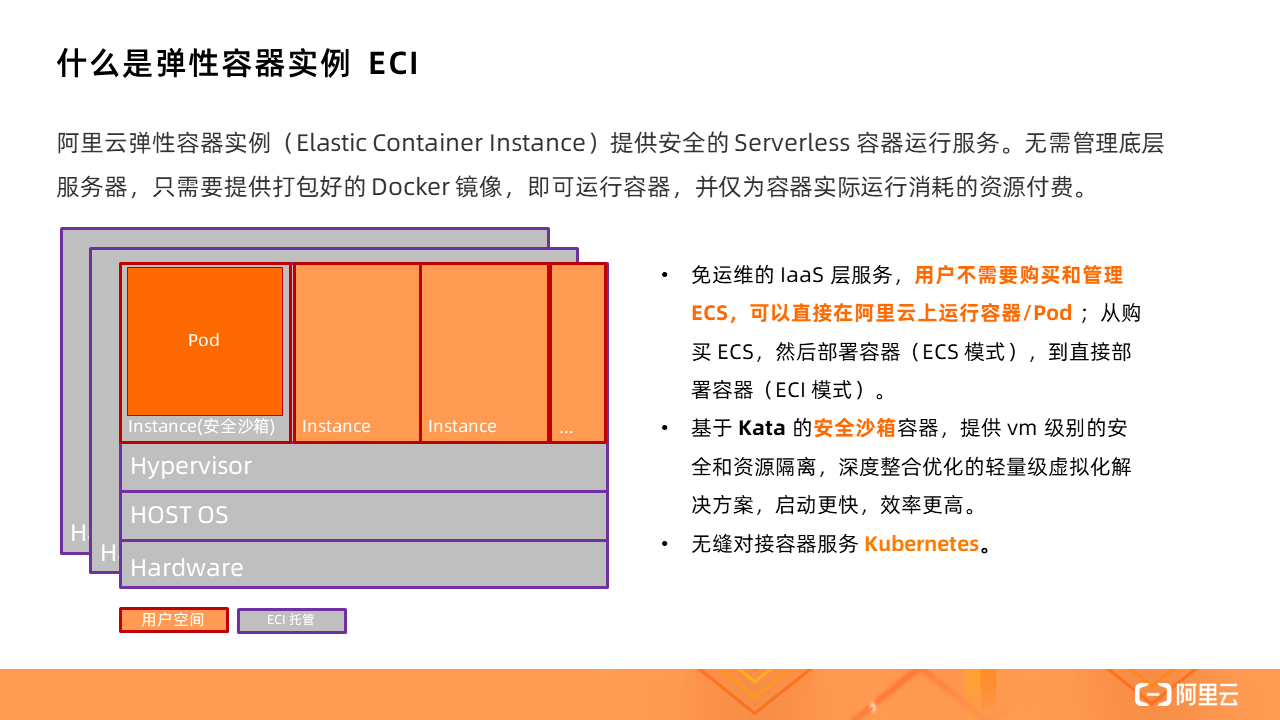
ECI 提供安全的 Serverless 容器運行服務。無需管理底層服務器,只需要提供打包好的 Docker 鏡像,即可運行容器,并僅為容器實際運行消耗的資源付費。
hadoop 不適合docker、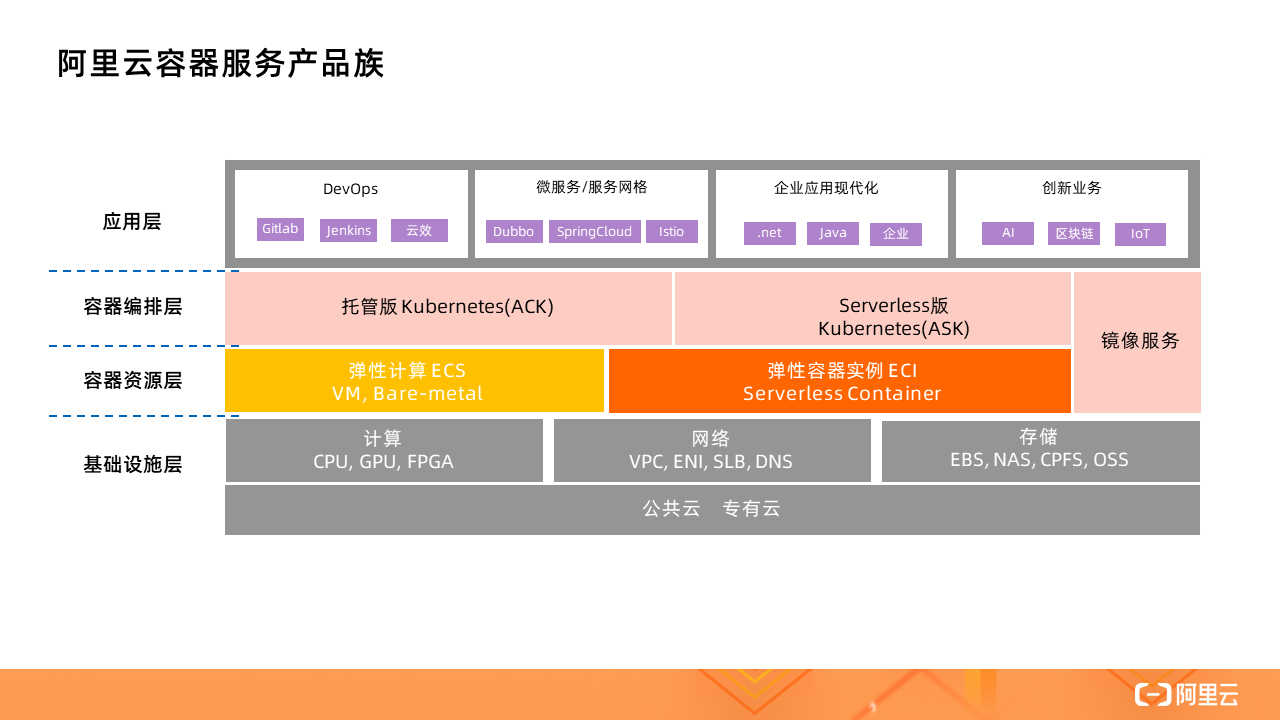
不論是托管版的 Kubernetes(ACK)還是 Serverless 版 Kubernetes(ASK),都可以使用 ECI 作為容器資源層,其背后的實現就是借助虛擬節點技術,通過一個叫做 Virtual Node 的虛擬節點對接 ECI。
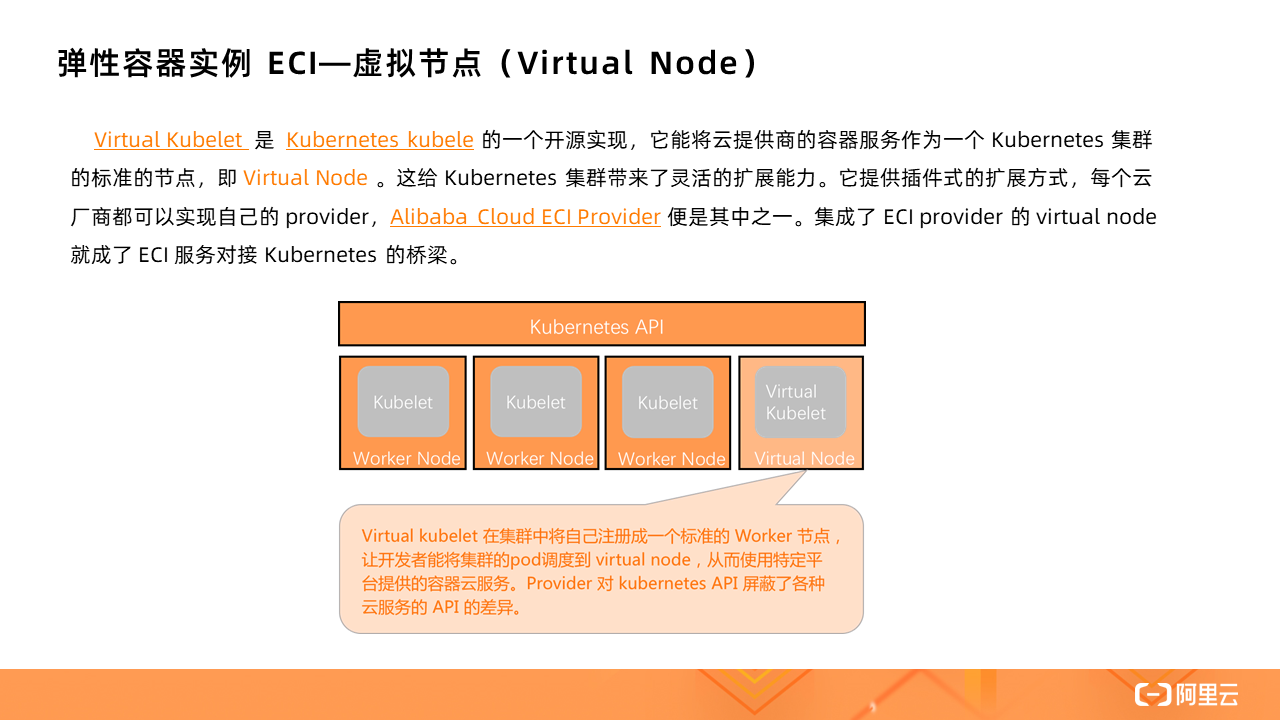
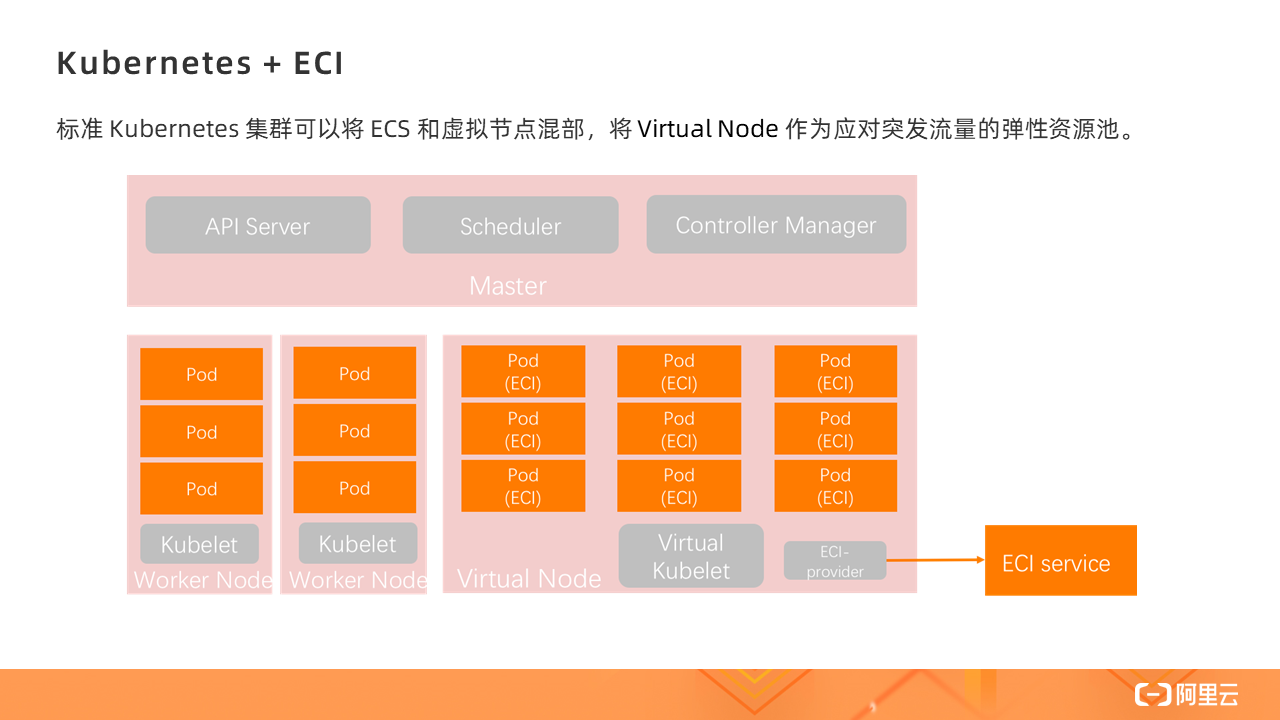
docker部署hadoop集群、有了 Virtual Kubelet,標準的 Kubernetes 集群就可以將 ECS 和虛擬節點混部,將 Virtual Node 作為應對突發流量的彈性資源池。
Serverless 集群中沒有任何 ECS worker 節點,也無需預留、規劃資源,只有一個 Virtual Node,所有的 Pod 的創建都是在 Virtual Node 上,即基于 ECI 實例。
k8s部署hadoop,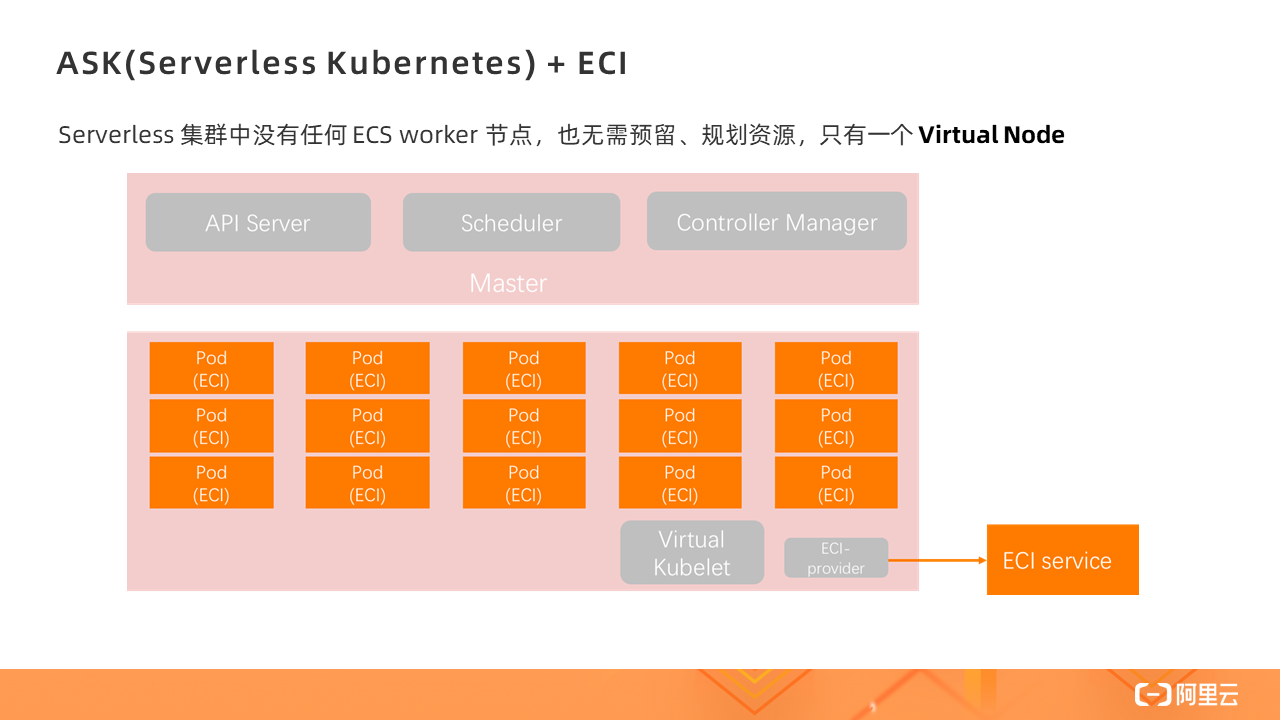
Serverless Kubernetes 是以容器和 Kubernetes 為基礎的 Serverless 服務,它提供了一種簡單易用、極致彈性、最優成本和按需付費的 Kubernetes 容器服務,其中無需節點管理和運維,無需容量規劃,讓用戶更關注應用而非基礎設施的管理。
Spark 自 2.3.0 開始試驗性支持 Standalone、on YARN 以及 on Mesos 之外的新的部署方式:Running Spark on Kubernetes,如今支持已經非常成熟。
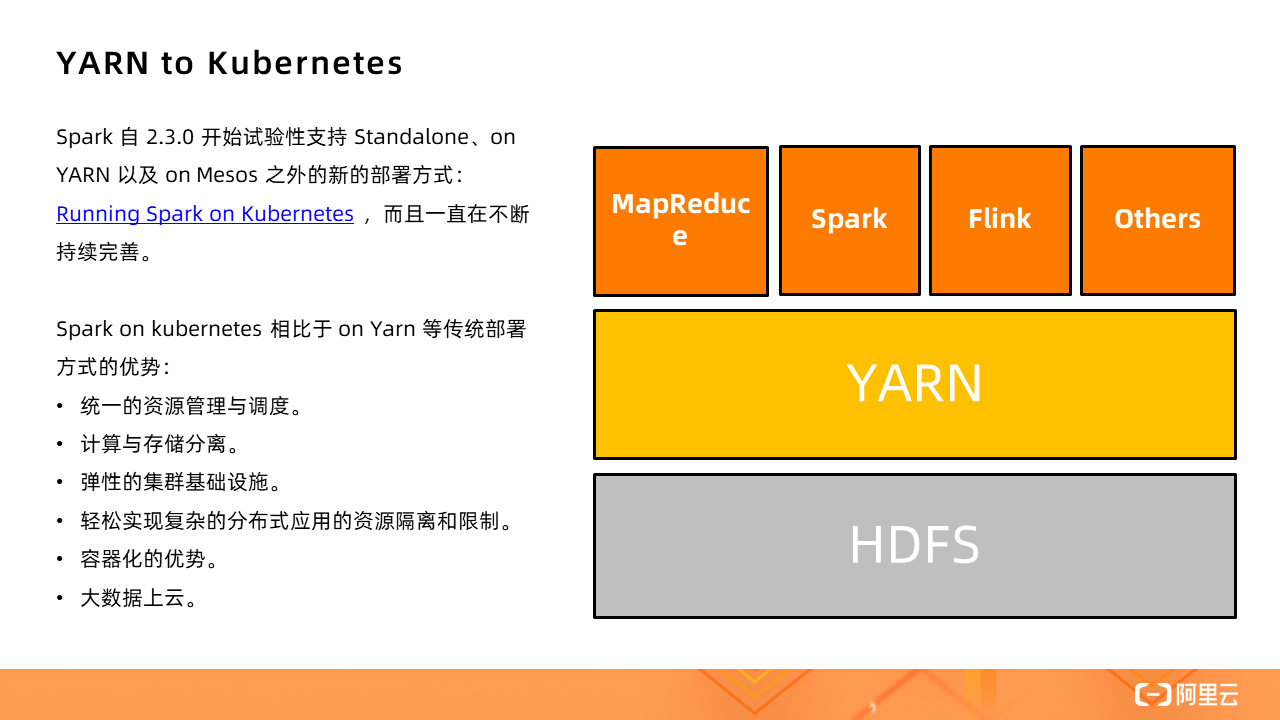
Spark on kubernetes 相比于 on Yarn 等傳統部署方式的優勢:
1、統一的資源管理。不論是什么類型的作業都可以在一個統一的 Kubernetes 集群中運行,不再需要單獨為大數據作業維護一個獨立的 YARN 集群。
2、傳統的將計算和存儲混合部署,常常會為了擴存儲而帶來額外的計算擴容,這其實就是一種浪費;同理,只為了提升計算能力,也會帶來一段時期的存儲浪費。Kubernetes 直接跳出了存儲限制,將離線計算的計算和存儲分離,可以更好地應對單方面的不足。
3、彈性的集群基礎設施。
4、輕松實現復雜的分布式應用的資源隔離和限制,從 YRAN 復雜的隊列管理和隊列分配中解脫。
5、容器化的優勢。每個應用都可以通過 Docker 鏡像打包自己的依賴,運行在獨立的環境,甚至包括 Spark 的版本,所有的應用之間都是完全隔離的。
6、大數據上云。目前大數據應用上云常見的方式有兩種:1)用 ECS 自建 YARN(不限于 YARN)集群;2)購買 EMR 服務,目前所有云廠商都有這類 PaaS,如今多了一個選擇——Kubernetes。
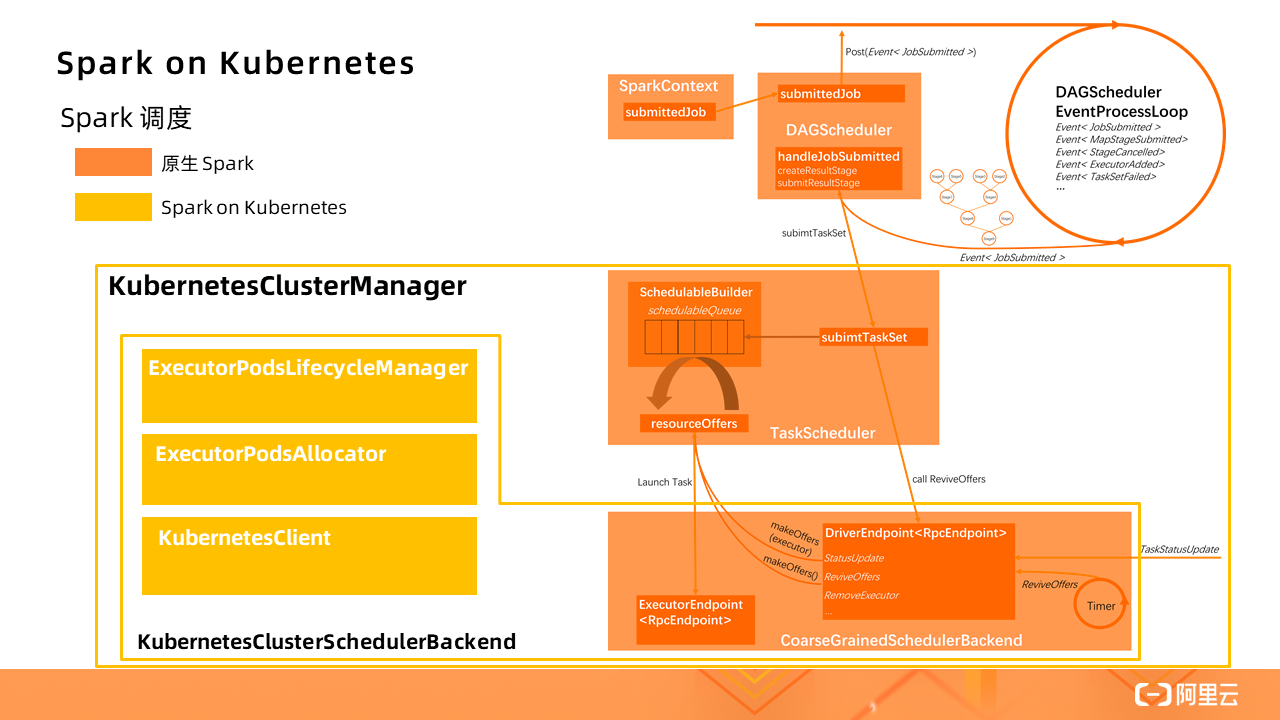
圖中橙色部分是原生的 Spark 應用調度流程,而 Spark on Kubernetes 對此做了一定的擴展(黃色部分),實現了一個 KubernetesClusterManager。其中 **KubernetesClusterSchedulerBackend 擴展了原生的CoarseGrainedSchedulerBackend,**新增了 **ExecutorPodsLifecycleManager、ExecutorPodsAllocator 和KubernetesClient **等組件,實現了將標準的 Spark Driver 進程轉換成 Kubernetes 的 Pod 進行管理。
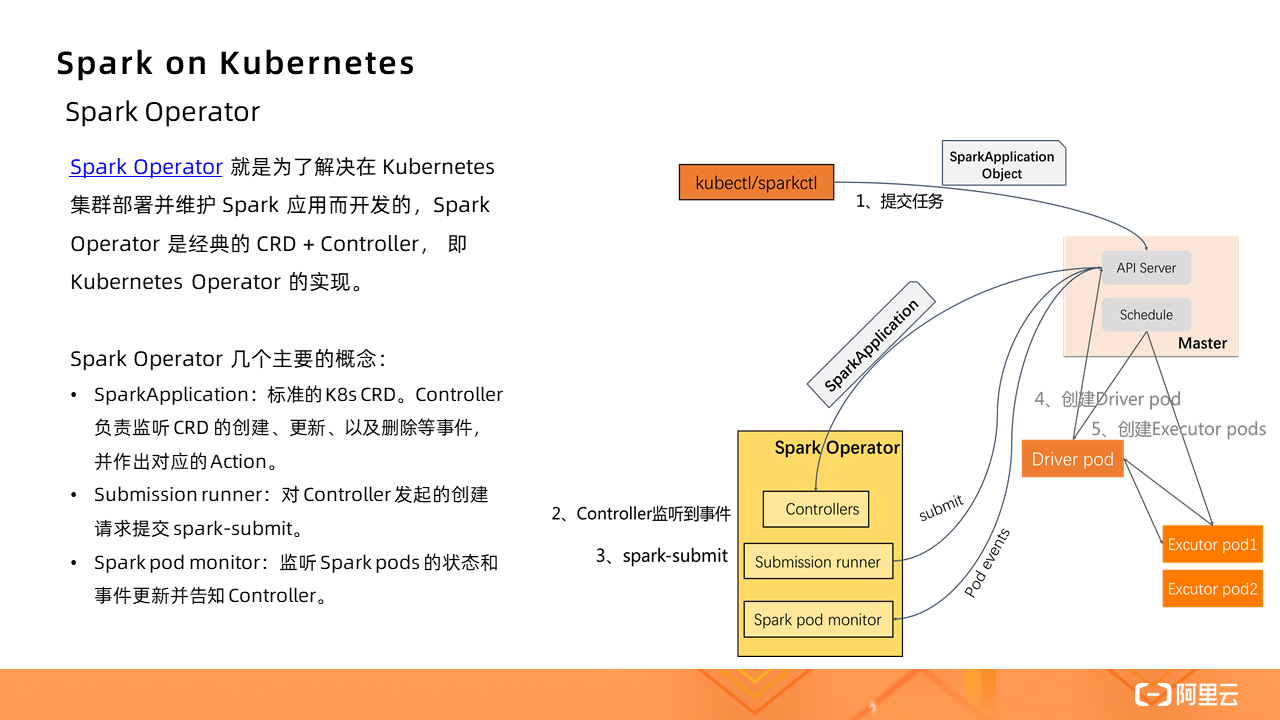
在 Spark Operator 出現之前,在 Kubernetes 集群提交 Spark 作業只能通過 Spark submit 的方式。創建好 Kubernetes 集群,在本地即可提交作業。
作業啟動的基本流程:
1、Spark 先在 K8s 集群中創建 Spark Driver(pod)。
2、Driver 起來后,調用 K8s API 創建 Executors(pods),Executors 才是執行作業的載體。
3、作業計算結束,Executor Pods 會被自動回收,Driver Pod 處于 Completed 狀態(終態)。可以供用戶查看日志等。
4、Driver Pod 只能被用戶手動清理,或者被 K8s GC 回收。
直接通過這種 Spark submit 的方式,參數非常不好維護,而且不夠直觀,尤其是當自定義參數增加的時候;此外,沒有 Spark Application 的概念了,都是零散的 Kubernetes Pod 和 Service 這些基本的單元,當應用增多時,維護成本提高,缺少統一管理的機制。
Spark Operator?就是為了解決在 Kubernetes 集群部署并維護 Spark 應用而開發的,Spark Operator 是經典的 CRD + Controller,即 Kubernetes Operator 的實現。
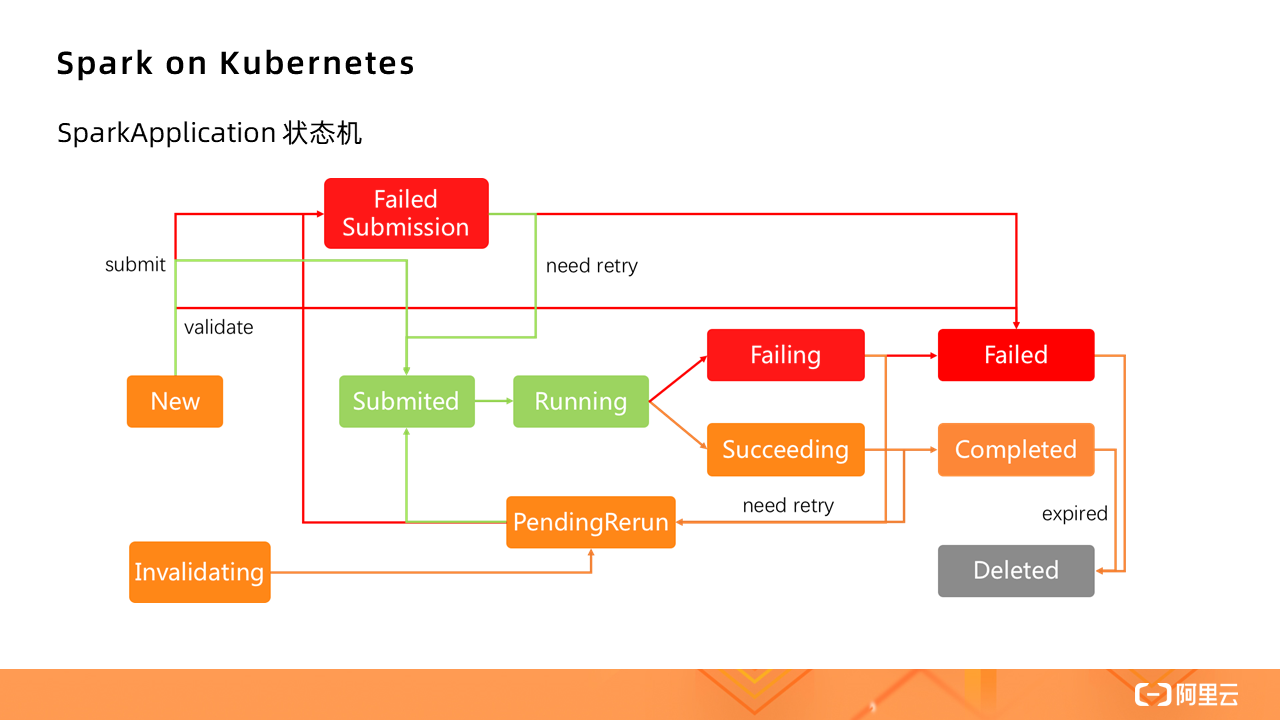
下圖為 SparkApplication 狀態機:
那么,如果在 Serverless Kubernetes 集群中運行 Spark,其實際上是對原生 Spark 的進一步精簡。
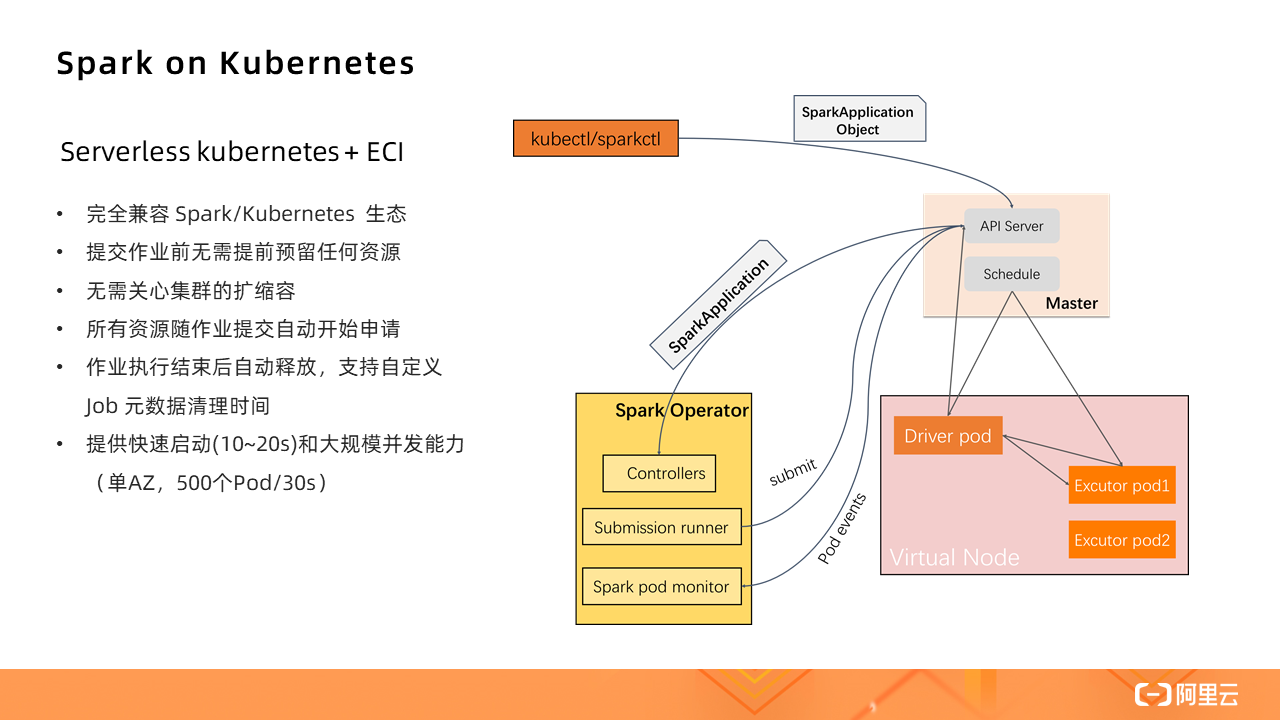

對于批量處理的數據源,由于集群不是基于 HDFS 的,所以數據源會有不同,需要計算與存儲分離,Kubernetes 集群只負責提供計算資源。
本次實操分別展示 TPC-DS 和 WordCount 兩個應用,點擊即可觀看具體操作演示過程
Serverless 公眾號,發布 Serverless 技術最新資訊,匯集 Serverless 技術最全內容,關注 Serverless 趨勢,更關注你落地實踐中的遇到的困惑和問題。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态


![[Wayland] (二) 代码结构 [FW]](https://images2015.cnblogs.com/blog/753004/201607/753004-20160720100837341-320217114.png)





![centsos7修改主机名 [root@st152 ~]# cat /etc/hostname](http://static.blog.csdn.net/images/save_snippets.png)