为什么80%的码农都做不了架构师?>>> 
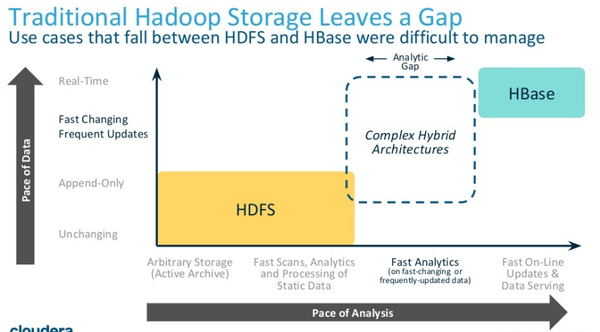
上图是 Hadoop 生态体系中,存储引擎和应用场景的对应关系。
横轴代表数据查询分析的频度(Pace of Analysis),依次为:
- 归档
- 基于静态数据的扫描/分析(一次写入多次读取)
- 基于频繁更新数据的快速分析
- 实时访问/更新(OLTP)
纵轴代表的是数据的更新频度(Pace of Data),依次为
- 只读
- 追加(Append-Only)
- 频繁更新
- 实时更新
我们知道,HDFS 特别适合归档和基于静态数据的扫描/分析的场景(一次写入多次读取),也就是上图中左下角的黄色区域,而HBase擅长实时高并发的读写应用,也就是右上角的蓝色区域。但是对于需要在频繁更新的数据之上做快速分析,也就是上图中间的虚线区域,Hadoop社区却一直没有比较好的存储层产品来满足。Kudu正是出于填补这个空白而诞生的。
视频中提到,Kudu的设计借鉴了Parque和HBase一些理念 / 思想。
Kudu产品的几个要点:
- 数据模型和关系数据库类似,为结构化的表;列的数量有限(和HBase/Cassandra相比较而言)
- 内部数据组织方式为列式存储
- 很好的横向扩展能力,目前测试的是275个节点(3PB),计划支持到上千个节点(几十PB)
- 不错的性能,集群能达到百万级别的TPS,单节点吞吐为几个GB/s
- 本身不提供SQL接口,只支持类似NoSQL的接口,如 Insert(), Update(), Delete() and Scan() 等
- 通过与 Spark 和 Impala 等(Drill,Hive的支持还在进行中)的集成,对外提供基于 SQL 的查询分析服务
Kudu 和 Spark 集成后,能带来的好处:
- 带来和 Parquet 相似的扫描性能,但却不存在数据更新/插入的延迟,也就是说,对数据的实时更新/插入,对分析应用来说是即时可见的,无延迟。
- Spark对数据的过滤条件(基于判定的过滤条件,即 predicate)可以下推到 Kudu 这一存储层,能提高数据读取/扫描的性能
- 相对 Parquet,基于主键索引的查询,性能更高
Spark Datasource
这部分比较简单,介绍Kudu与Spark集成的代码片段。基本上就创建一个kuduDataFrame后,后续的操作就和普通的Spark DataFrame API没什么差别了
Quick Demo
Demo也比较简单,有兴趣大家可以自己看一下视频(位置在视频的 18分26秒),就是在 Spark Shell 中操作一个 kuduDataFrame
Use Cases
Kudu 最适合的场景包含这两个特点:
- 同时有顺序和随机读写的场景
- 对数据更新的时效性要求比较高
这样的场景有:
- 和时间序列相关的数据分析:对市场/销售数据的实时分析;反欺诈;网络监控等
- 在线报表和数据仓库应用:如ODS(Operational Data Store)
片中还介绍了小米使用Kudu的一个具体场景,需求是要收集手机App和后台服务发送的 RPC 跟踪事件数据,然后构建一个服务监控和问题诊断的工具,要求:
- 高写入吞吐:每天大于200亿条记录
- 为了能够尽快定位和解决问题,要求系统能够查询最新的数据并能快速返回结果
- 为了方便问题诊断,要求系统能够查询/搜索明细数据(而不只是统计信息)
在没有使用kudu之前,方案的架构如下图所示。
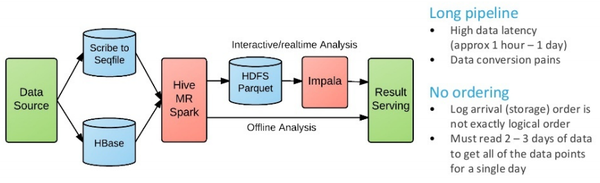
这是典型的Lambda架构(存在两套相对独立的数据流水线:批处理和流处理),一部分源系统数据是通过Scribe(日志聚合系统)把数据写到HDFS,另一部分源系统数据(实时性要求较高的?)是直接写入HBase,然后:
- 为了能支持交互式/实时的查询,需要通过Hive/MR/Spark作业把这两部分数据合并成 Parquet 格式存放在HDFS,通过 Impala 对外提供交互式查询服务
- 线下分析的就直接通过运行 Hive/MR/Spark 作业来完成
我们可以看到,这样的数据线比较长,带来两个问题:
- 其一是数据时效性较差(一个小时到一天);
- 其二是需要多次数据转换(如:HFile + seqfile ==> Parquet)
还有一个问题,存储层中数据不是按照时间戳来排序,如果有部分数据没有及时到达,那么为了统计某一天的数据,可能就要读取好几天的数据才能得到。
使用了Kudu以后,方案的架构如下图所示。
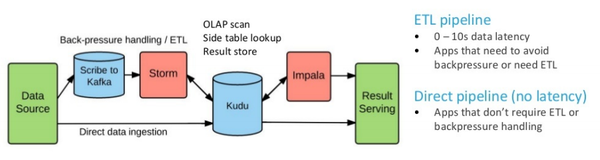
数据都存储在Kudu中,分两条线进入Kudu:
- 对于需要做加工(ETL)的数据或来自压力较大的系统的数据(产生的数据较多,源系统无法长时间缓存)可以先进入Kafka缓存,然后通过Storm做实时的ETL后进入Kudu,这种情况的延时在 0~10秒的区间
- 反之,源系统的数据可以直接写入 Kudu,这种情况数据没有任何延迟
然后,一方面可以通过 Impala 对外提供交互式查询服务(基于SQL),另一方面也可以直接通过 Kudu API 直接访问数据
这样的架构带来的好处比较明显,一方面是大大提高数据的时效性,另一方面大大简化系统架构
PPT中还有一张 Kudu + Impala 的方案与 MPP 数据库产品(如 Greenplum,Vertica 和 Teradata)进行对比,但是由于时间关系视频中没有讲,这里简单提一下:
他们有存在相似之处:
- 提供基于SQL的交互式快速查询/分析
- 能够提供插入、更新和删除操作
相对于 MPP 数据库,Kudu + Impala 方案的优势:
- 更快的流式数据插入(streaming insert)
- 和 Hadoop 生态体系有较好的集成:
- 把 Kudu 和 HDFS 部署在同一个集群,可以关联分别存储在 Kudu 和 HDFS 上的表
- 和 Spark,Flume等的集成度较好
相对于 MPP 数据库,Kudu + Impala 方案的劣势:
- 批量插入的性能相对较慢
- 不支持数据装载的原子操作,不支持跨行的原子操作,不支持二级索引
Kudu Roadmap
相对 HDFS 和 HBase,Kudu还是一个比较新的项目,视频介绍了产品路线图的一些想法:
安全方面:
- 和 Kerberos 的集成
- 力度更细的权限控制
- 基于组和角色的权限管理
- ...
运维方面:
- 稳定性的增强
- 一些恢复工具
- 故障诊断辅助工具
性能和扩展性:
- 具体一些读写性能提升的想法
- 扩展性的提升(短期到400节点,长期上千节点)
客户端方面:
- 目前支持Java、C++ 和 python,Python目前还是短板,有些功能还没支持
- 文档、教程和日志等方面