线程。
聊一下为什么要使用线程池?
程序的运行本质,就是通过使用系统资源(CPU、内存、网络、磁盘等等)来完成信息的处理,比如在JVM中创建一个对象实例需要消耗CPU的和内存资源,如果你的程序需要频繁创建大量的对象,并且这些对象的存活时间短就意味着需要进行频繁销毁,那么很有可能这段代码就成为了性能的瓶颈。总结下来其实就以下几点。
线程池 java,简单言之,线程池就是将用过的对象保存起来,等下一次需要这个对象的时候,直接从对象池中拿出来重复使用,避免频繁的创建和销毁。在Java中万物皆对象,那么线程也是一个对象,Java线程是对于操作系统线程的封装,创建Java线程也需要消耗操作系统的资源,因此就有了线程池。
首先了解一下线程池创建以及工作原理。线程池创建主要由ThreadPoolExecutor类完成。
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null :AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}各个参数说明:
corePoolSize:线程池中核心线程数的数量
maximumPoolSize:在线程池中允许存在的最大线程数
keepAliveTime:如果当前线程池中的线程数超过了corePoolSize,那么如果在keepAliveTime时间内都没有新的任务需要处理,那么超过corePoolSize的这部分线程就会被销毁。默认情况下是不会回收core线程的,可以通过设置allowCoreThreadTimeOut改变这一行为。
unit:时间单位
workQueue:工作队列,线程池中的当前线程数大于核心线程的话,那么接下来的任务会放入到队列中
threadFactory:通过工厂模式来生产线程。创建线程都是通过ThreadFactory来实现的,如果没指定的话,默认会使用Executors.defaultThreadFactory(),一般来说,我们会在这里对线程设置名称、异常处理器等。
handler:如果超过了最大线程数,那么就会执行我们设置的拒绝策略。
线程池工作流程图如下:
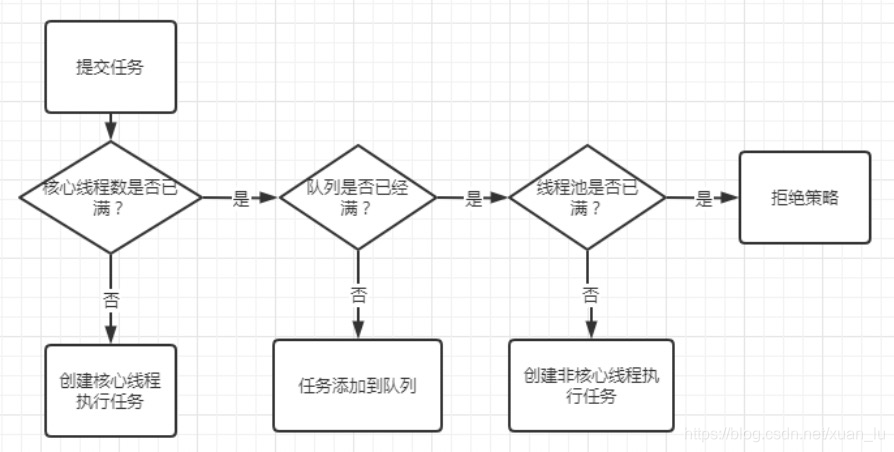
1-> 当任务提交时,线程池先检查当前线程数;如果当前线程数小于核心线程数(corePoolSize),则创建线程并执行任务;比如开始提交任务时,线程数为0;
2->当线程任务不断增加时,创建的线程数等于核心线程数(corePoolSize),则新增的任务将会被添加到工作队列中(workQueue),等待核心线程将当前任务执行结束,重新从工作队列中获取任务执行;
3->当任务非常多时,并且达到工作队列的最大容量,但是当前线程数小于最大线程数(maximumPoolSize),线程池会在核心线程的基础上继续创建线程(非核心线程)执行任务;
4->当任务继续增加时,线程池的线程数达到最大线程数;如果任务继续增加,此时线程池则会采取拒绝策略拒绝执行任务,默采用AbortPolicy策略,抛出异常。
ThreadPoolExecutor提供了四种拒绝策略:
public static class AbortPolicy implements RejectedExecutionHandler {/*** Creates an {@code AbortPolicy}.*/public AbortPolicy() { }/***直接抛异常出去*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());}
}public static class CallerRunsPolicy implements RejectedExecutionHandler {/*** Creates a {@code CallerRunsPolicy}.*/public CallerRunsPolicy() { }/***将此任务交给调用者直接执行*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}}
}public static class DiscardOldestPolicy implements RejectedExecutionHandler {/*** Creates a {@code DiscardOldestPolicy} for the given executor.*/public DiscardOldestPolicy() { }/*** 丢弃最老的任务*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}}
}
对于当前任务不做任何操作,简单言之:直接丢弃。public static class DiscardPolicy implements RejectedExecutionHandler {/*** Creates a {@code DiscardPolicy}.*/public DiscardPolicy() { }/***不执行任何操作*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}
}除了以上四种拒绝策略,Java还支持自定义拒绝策略,我们实现RejectExecutionHandler接口即可;
上面我们了解了线程池的参数、工作流程、拒绝策略,下面我们了解一下如何设置参数能够达到线程池的最大利用率呢?
正确的定制线程池的长度,需要了解当前计算机配置、所需资源的情况以及任务的特性。比如部署的计算机安装了多少个CPU?多少的内存?任务主要执行是IO密集型还是CPU密集型?所执行任务是否需要数据库连接这样的稀缺资源?
N:CPU的数量
U:目标CPU的使用率,0<=U<=1
W/C:等待时间与计算时间的比率
那么最优的线程池的大小就是=NU(1+W/C)
newCachedThreadPool
创建可缓存无限制数量的线程池。如果线程中没有空闲线程池的话此时再来任务会新建线程,如果超过60秒此线程无用,那么就会将此线程销毁。简单来说就是忙不来的时候无限制创建临时线程,闲下来再回收。

newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。

newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。

newScheduledThreadPool
创建一个固定大小的核心线程。此线程池支持定时以及周期性执行任务的需求。

了解了上面四种线程池后,大家应该会明白阿里巴巴规约中为什么会推荐手动创建线程池。

解释
FixedThreadPool和SingleThreadExecutor:这两个线程池的实现方式,可以看到它设置的工作队列都是LinkedBlockingQueue,该队列是一个链表形式的队列,此队列是没有长度限制的,是一个无界队列,那么此时如果有大量请求,就有可能造成OOM。
CachedThreadPool和ScheduledThreadPool:这两个线程池的实现方式,可以看到它设置的最大线程数都是Integer.MAX_VALUE,那么就相当于允许创建的线程数量为Integer.MAX_VALUE。此时如果有大量请求来的时候也有可能造成OOM。
手动创建一个线程池,并实现多线程执行任务。
public class ThreadPoolTask {private static final Logger LOG = LoggerFactory.getLogger(ThreadPoolTask.class);public static void main(String[] args) {List<String> idList = new LinkedList<>();for (int i =0; i < 20; i ++) {idList.add("i" + i);}//默认20个任务未被执行falseMap<String, Object> taskMap = new LinkedHashMap<>();idList.forEach(e -> taskMap.put(e, Boolean.FALSE));//自定义线程池ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 5,0L, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<>(4));//多线程执行任务idList.forEach(id -> {Future<?> taskResult = threadPoolExecutor.submit(new HandlerTask(taskMap, id));try {taskResult.get();} catch (Exception e) {e.printStackTrace();}});//关闭线程池threadPoolExecutor.shutdown();}
}class HandlerTask implements Runnable {private final Map<String, Object> taskMap;private final String id;public HandlerTask(Map<String, Object> taskMap, String id) {this.taskMap = taskMap;this.id = id;}@Overridepublic void run() {System.out.println("start=" + Thread.currentThread().getName());handler(id);System.out.println("end=" + Thread.currentThread().getName());}private void handler(String id) {Object o = taskMap.get(id);//判断是否被执行过if (!Boolean.TRUE.equals(o)) {//省略业务逻辑taskMap.put(id, true);}}
}版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态