本案計劃實現:通過網絡請求,獲取豆瓣電影TOP250的數據,并存儲到Json文件中。
案例應用技巧:
總體來說,簡單的單線程爬蟲的實現流程如下:
下面我們按著以上步驟來依次完成。
在Chrome瀏覽器中打開豆瓣電影TOP250,其Url為:https://movie.douban.com/top250。
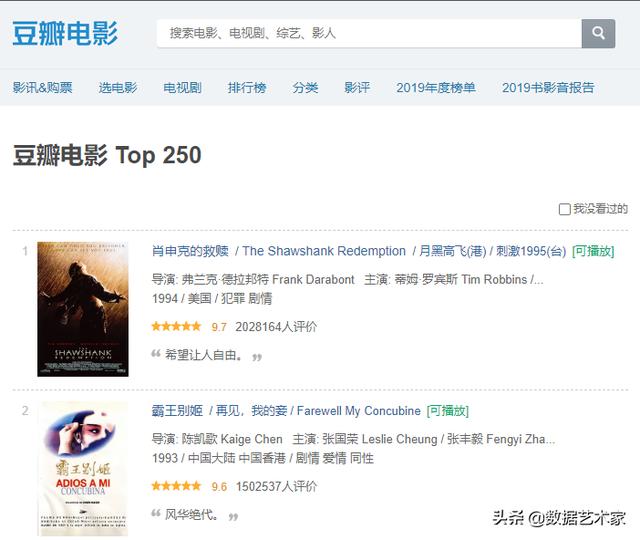
通過觀察,可以發現目標數據是存在于網頁源代碼中的,直接請求網頁Url即可獲得。
同時,第1頁僅顯示了25部電影,說明我們需要請求10次不同的頁面才能完成所有250部電影的抓取。于是我們在頁面上點擊打開第2頁,發現第2頁的Url是:
https://movie.douban.com/top250?start=25&filter=
相較于第1頁的Url,第2頁增加了start參數和filter參數,因為filter參數內容為空值,很可能是用來”我沒看過的“選項的篩選的,因此start參數應該是實際起作用的。因為第1頁有25個電影,而第2頁的start參數為25,說明start很可能是指當前頁面是從第多少部電影開始顯示的。
為了檢驗這個結果,我們使用瀏覽器打開start參數值為0的頁面,果然正確地打開了第1頁。因此,我們只需要修改start參數就可以有效地實現翻頁了。
下面我們開始嘗試使用Python實現請求,在這個過程中,建議大家使用IDLE或PyCharm的Python Console模式來進行測試,減少網站的實際請求次數,以減少對目標網站的影響,以免被IP封鎖。
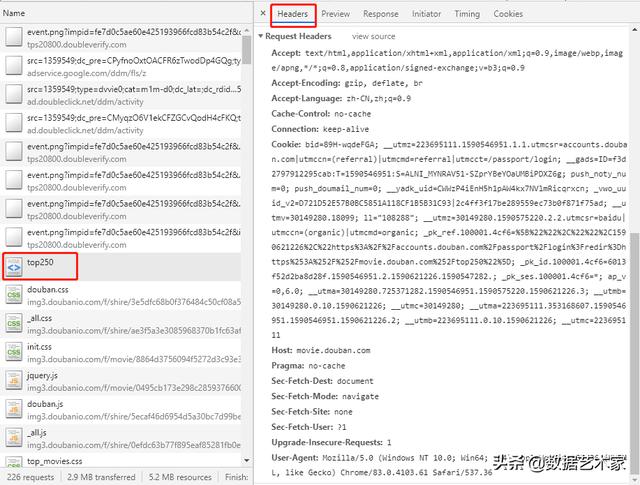
我們先以第1頁為例進行嘗試,發現直接使用requests的請求并不能獲得數據,說明我們的請求被拒絕了。因此,我們可以打開Chrome控制臺中訪問頁面時的請求,選擇headers選項卡,查看其中的Request Headers,并依據這個headers來偽裝我們的請求。實現代碼如下:
?import requests???headers = {? ? ?"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",? ? ?"accept-language": "zh-CN,zh;q=0.9",? ? ?"cache-control": "no-cache",? ? ?"Connection": "keep-alive",? ? ?"host": "movie.douban.com",? ? ?"pragma": "no-cache",? ? ?"Sec-Fetch-Dest": "document",? ? ?"Sec-Fetch-Mode": "navigate",? ? ?"Sec-Fetch-Site": "none",? ? ?"Sec-Fetch-User": "?1",? ? ?"Upgrade-Insecure-Requests": "1",? ? ?"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36",?}???response = requests.get("https://movie.douban.com/top250", headers=headers)???print(response.content.decode(errors="ignore"))暫時先不要在headers中添加“Accept-Encoding”,否則請求結果可能會被壓縮,影響解析。
在打印出的內容中,我們通過搜索可以找到我們需要的數據。
下面,我們使用CSS選擇器將電影的各類信息解析出來(先定位到每個電影的標簽,再定位到各類信息的標簽,最后將各類信息從標簽中提取出來)。在解析過程中,我們要隨時考慮到我們當前解析的標簽可能不存在,并努力避免因標簽不存在而報錯。實現代碼如下:
?from bs4 import BeautifulSoup???bs = BeautifulSoup(response.content.decode(errors="ignore"), 'lxml')?for movie_label in bs.select("#content > div > div.article > ol > li"): ?# 定位到電影標簽? ? ?url = movie_label.select_one("li > div > div.pic > a")["href"] ?# 獲取電影鏈接(標簽的href屬性)? ? ?title_text = movie_label.select_one("li > div > div.info > div.hd > a").text ?# 獲取標題行內容? ? ?info_text = movie_label.select_one("li > div > div.info > div.bd > p:nth-child(1)").text ?# 獲取說明部分內容? ? ?rating_num = movie_label.select_one("li > div > div.info > div.bd > div > span.rating_num").text ?# 獲取評分? ? ?rating_people = movie_label.select_one("li > div > div.info > div.bd > div > span:nth-child(4)").text ?# 獲取評分人數? ? ?if quote_label := movie_label.select_one("li > div > div.info > div.bd > p.quote"):? ? ? ? ?quote = quote_label.text ?# 獲取評價? ? ?print(url, title_text, info_text, rating_num, rating_people, quote)通過以上代碼,我們成功地將各部分的數據都解析出來了,但是解析出的標題行內容、說明部分內容、評分、評分人數和評價中格式相對混亂,包括很多不需要的內容,需要進一步的清洗。
解析、清洗標題行:
?title_text = movie_label.select_one("li > div > div.info > div.hd > a").text.replace("", "") ?# 提取標題行內容+清除換行符?title_chinese = clear_space_in_polar(title_text.split("/")[0]) ?# 提取中文標題+清除前后空格?title_other = [clear_space_in_polar(title) for title in title_text.split("/")[1:]] ?# 提取其他標題+清除前后空格解析導演信息(因長度原因,大部分主演名字不全暫不解析):
?info_text = movie_label.select_one("li > div > div.info > div.bd > p:nth-child(1)").text ?# 獲取說明部分內容?info_text = re.sub(" *", "", info_text) ?# 清除行前多余的空格?info_text = re.sub("^", "", info_text) ?# 清除開頭的空行?info_line_1 = info_text.split("")[0] ?# 獲取第1行內容信息:包括導演和主演?info_line_2 = info_text.split("")[1] ?# 獲取第2行內容信息:包括年份、國家和類型?director = re.sub(" *(主演|主.{3}|.{3}).*$", "", info_line_1) ?# 僅保留導演部分?year = int(re.search("[0-9]+", info_line_2.split("/")[0]).group()) ?# 提取電影年份并轉換為數字?country = clear_polar_space(info_line_2.split("/")[1]) if len(info_line_2.split("/")) >= 2 else None ?# 提取電影國家?classify = clear_polar_space(info_line_2.split("/")[2]) if len(info_line_2.split("/")) >= 3 else None ?# 提取電影類型?classify = re.split(" +", classify) ?# 將電影類型轉換為list形式解析評分、評分人數和評價:
?# 解析評分?rating_num = movie_label.select_one("li > div > div.info > div.bd > div > span.rating_num").text ?# 提取評分?rating_num = float(re.search("[0-9.]+", rating_num).group()) ?# 將評分轉換為浮點型數字???# 解析評分人數?rating_people = movie_label.select_one("li > div > div.info > div.bd > div > span:nth-child(4)").text ?# 提取評分人數?rating_people = int(re.search("[0-9]+", rating_people).group()) ?# 將評分人數轉換為數字???# 解析評價(該標簽可能會不存在)?if quote_label := movie_label.select_one("li > div > div.info > div.bd > p.quote"):? ? ?quote = quote_label.text.replace("", "") ?# 提取評價+清除換行符?else:? ? ?quote = None在解析的過程中,我們將每個電影解析的結果臨時存儲在循環前定義的movie_list列表中。
?movie_list.append({? ? ?"title": {? ? ? ? ?"chinese": title_chinese,? ? ? ? ?"others": title_other? ? },? ? ?"director": director,? ? ?"year": year,? ? ?"country": country,? ? ?"classify": classify,? ? ?"rating": {? ? ? ? ?"num": rating_num,? ? ? ? ?"people": rating_people? ? },? ? ?"quote": quote?})在完成了單頁面的解析后,我們開始實現翻頁。根據之前對頁面的了解,我們只需要將頁面的請求和解析嵌套到一個循環中即可。在每次循環中均需進行延遲,以免請求頻率過高。實現代碼如下:
?import time?for page_num in range(10):? ? ?url = "https://movie.douban.com/top250?start={0}&filter=".format(page_num * 25)? ? ?response = requests.get(url, headers=headers)? ? ......? ? ?time.sleep(5)最后,我們將存儲在臨時變量movie_list列表中的數據存儲到本地Json文件(若使用IDLE或PyCharm的Python Console模式,建議使用絕對路徑)。
?import json?with open("豆瓣TOP250電影.json", "w+", encoding="UTF-8") as file:? ? ?file.write(json.dumps({"data": movie_list}, ensure_ascii=False))本系列案例采集的一切數據僅可用于學習、研究用途!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











