本文主要探讨了机器学习算法中一些比较容易理解的分类算法,包括二次判别分析QDA,线性判别分析LDA,朴素贝叶斯Naive Bayes,以及逻辑回归Logistic Regression,还会给出在irsi数据集上相应的手写python代码以及在sklearn上运用的实例。在本文的讨论中,我们强调了简单分类模型,是为了区别于树模型以及支持向量基模型,这两类模型将单独在以后的文章中跟大家分享,而本文也是深度学习的理论引入,后面的文章中将给大家从两个分支继续讨论机器学习,包括我们的深度学习和树模型等。(本文章部分图片引用李宏毅老师的机器学习课程,侵权即删)
我们先来看看iris数据集:
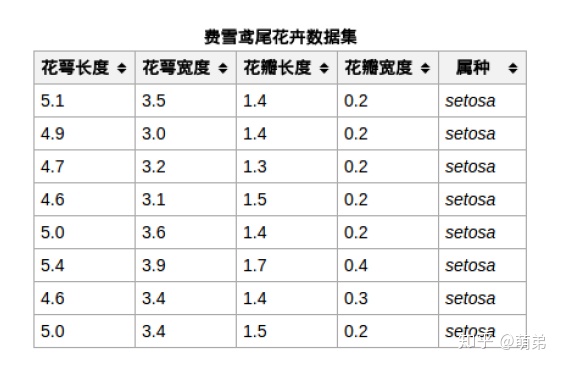
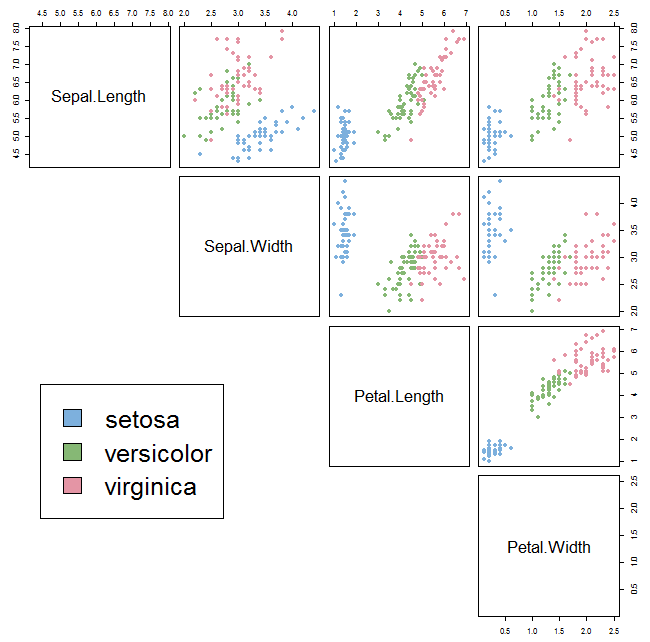
我们的任务是:给定一个样本,这个样本包含花萼长度,花萼宽度,花瓣长度,花瓣宽度的值,我们需要预测这个样本是属于哪个品种的鸢尾花。


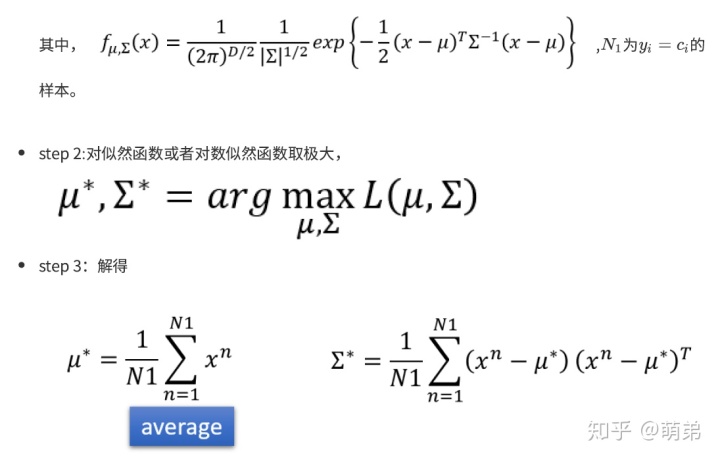
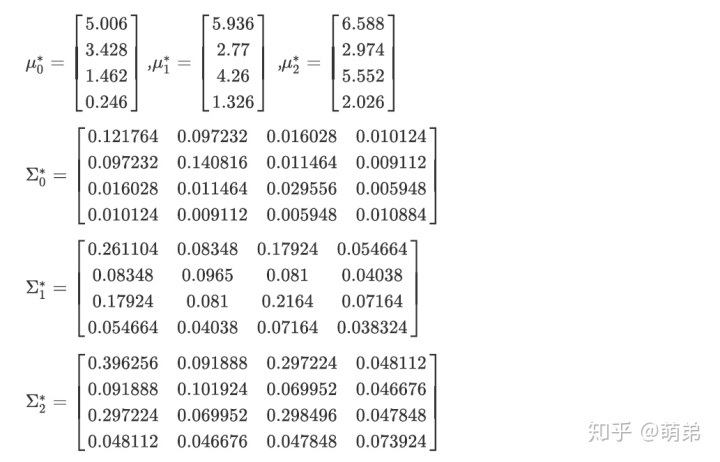
对于以上的iris分类问题,我们按照以上步骤解得:
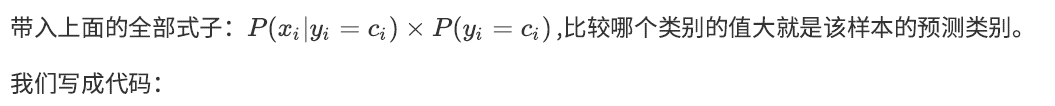
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
%matplotlib inline
class QDA():def __init__(self):self.data = dataself.target = targetdef find_mean(self):target_unique = np.unique(self.target)self.means = []for i in target_unique:self.means.append(np.sum(self.data[self.target==i,],axis=0)/np.sum(self.target==i))print("u为:n",self.means)return self.meansdef find_sigma(self):target_unique = np.unique(self.target)self.sigmas = []for k,i in enumerate(target_unique):self.sigmas.append(((self.data[self.target==i,]-self.means[k]).T.dot((self.data[self.target==i,]-self.means[k])))/np.sum(self.target==i))print("sigma为:n",self.sigmas)return self.sigmasdef find_f(self):self.f_i = []self.f_ii = []for i in range(len(np.unique(target))):for j in range(len(target)):self.f_ii.append(self.p_ci[i]*1/(((2*np.pi)**self.data.shape[1])*(np.linalg.det(self.sigmas[i])**0.5))*np.exp(-0.5*(self.data[j,:]-self.means[i]).dot(np.linalg.inv(self.sigmas[i])).dot((self.data[j,:]-self.means[i]).T)))self.f_i.append(np.array(self.f_ii))self.f_ii = []return(self.f_i)def p_c(self):self.p_ci = []for i in np.unique(self.target):self.p_ci.append(sum(self.target==i)/len(self.target))return self.p_cidef arg_max(self):self.final_p = np.array(self.f_i)self.max_p = np.argmax(self.final_p,axis=0)return self.max_pdef score(self):self.classification_score = sum(target==self.max_p)/len(target)print("预测分类准确率为:{} %".format(self.classification_score*100))return self.classification_scoredef start(self):mean = self.find_mean()sigma = self.find_sigma()p_c1 = self.p_c()f = self.find_f()predict = self.arg_max()c_score = self.score()if __name__=='__main__':iris = load_iris()data = iris.datatarget = iris.targetfeatures = iris.feature_namesqda = QDA()qda.start()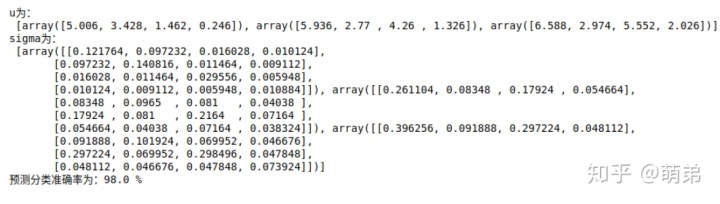
预测准确率98%,还是不错的。接着我们使用sklearn验证我们写的对不对:
# 我们使⽤sklearn验证我们写的对不对
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
clf = QDA()
clf.fit(data,target)
clf.score(data,target)
由于我们的判别边界P=0.5是⼀个⼆次函数,所以叫⼆次判别分析。


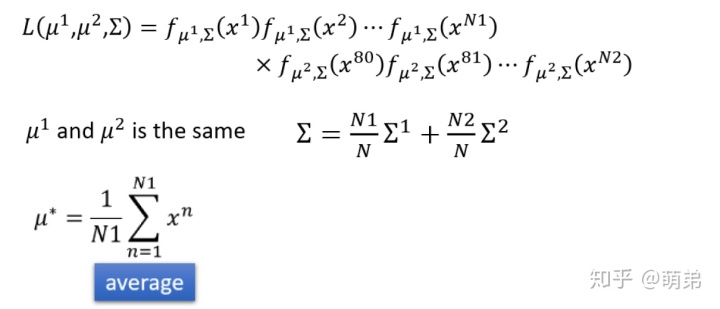
因此我们写成python程序:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
%matplotlib inline
class LDA():def __init__(self):self.data = dataself.target = targetdef find_mean(self):target_unique = np.unique(self.target)self.means = []for i in target_unique:self.means.append(np.sum(self.data[self.target==i,],axis=0)/np.sum(self.target==i))return self.meansdef find_sigma(self):target_unique = np.unique(self.target)self.sigmas = []for k,i in enumerate(target_unique):self.sigmas.append(((self.data[self.target==i,]-self.means[k]).T.dot((self.data[self.target==i,]-self.means[k])))/np.sum(self.target==i))self.sigma_k = []for i in range(len(np.unique(self.target))):self.sigma_k.append(sum(target==i)/len(target))self.sigma_com = []for i in range(len(np.unique(self.target))):self.sigma_com.append(self.sigma_k[i]*self.sigmas[i])self.sigmas1 = []for i in range(len(np.unique(self.target))):self.sigmas1.append(sum(self.sigma_com))self.sigmas = self.sigmas1print("我们的共同的sigma为:n{}".format(self.sigmas[0]))return self.sigmasdef find_f(self):self.f_i = []self.f_ii = []for i in range(len(np.unique(target))):for j in range(len(target)):self.f_ii.append(self.p_ci[i]*1/(((2*np.pi)**self.data.shape[1])*(np.linalg.det(self.sigmas[i])**0.5))*np.exp(-0.5*(self.data[j,:]-self.means[i]).dot(np.linalg.inv(self.sigmas[i])).dot((self.data[j,:]-self.means[i]).T)))self.f_i.append(np.array(self.f_ii))self.f_ii = []return(self.f_i)def p_c(self):self.p_ci = []for i in np.unique(self.target):self.p_ci.append(sum(self.target==i)/len(self.target))return self.p_cidef arg_max(self):self.final_p = np.array(self.f_i)self.max_p = np.argmax(self.final_p,axis=0)return self.max_pdef score(self):self.classification_score = sum(target==self.max_p)/len(target)print("预测分类准确率为:{} %".format(self.classification_score*100))return self.classification_scoredef start(self):mean = self.find_mean()sigma = self.find_sigma()p_c1 = self.p_c()f = self.find_f()predict = self.arg_max()c_score = self.score()if __name__=='__main__':iris = load_iris()data = iris.datatarget = iris.targetfeatures = iris.feature_nameslda = LDA()lda.start()
我们使⽤sklearn验证:
# 我们使用sklearn验证我们写的对不对
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
clf = LDA()
clf.fit(data,target)
clf.score(data,target)
由于我们的LDA判别边界是线性的,所以我们叫做线性判别分析。
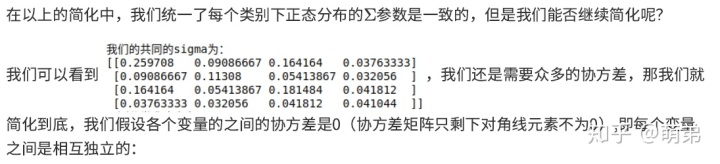

因此,我们写成python代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
%matplotlib inline
class Naive():def __init__(self):self.data = dataself.target = targetdef find_mean(self):target_unique = np.unique(self.target)self.means = []for i in target_unique:self.means.append(np.sum(self.data[self.target==i,],axis=0)/np.sum(self.target==i))return self.meansdef find_sigma(self):target_unique = np.unique(self.target)self.sigmas = []for k,i in enumerate(target_unique):self.sigmas.append(((self.data[self.target==i,]-self.means[k]).T.dot((self.data[self.target==i,]-self.means[k])))/np.sum(self.target==i))self.sigma_k = []for i in range(len(np.unique(self.target))):self.sigma_k.append(sum(target==i)/len(target))self.sigma_com = []for i in range(len(np.unique(self.target))):self.sigma_com.append(self.sigma_k[i]*self.sigmas[i])self.sigmas1 = []for i in range(len(np.unique(self.target))):s = sum(self.sigma_com)s = np.diagonal(s)s = np.identity(self.data.shape[1])*sself.sigmas1.append(s)self.sigmas = self.sigmas1print("我们的共同的sigma为:n{}".format(self.sigmas[0]))return self.sigmasdef find_f(self):self.f_i = []self.f_ii = []for i in range(len(np.unique(target))):for j in range(len(target)):self.f_ii.append(self.p_ci[i]*1/(((2*np.pi)**self.data.shape[1])*(np.linalg.det(self.sigmas[i])**0.5))*np.exp(-0.5*(self.data[j,:]-self.means[i]).dot(np.linalg.inv(self.sigmas[i])).dot((self.data[j,:]-self.means[i]).T)))self.f_i.append(np.array(self.f_ii))self.f_ii = []return(self.f_i)def p_c(self):self.p_ci = []for i in np.unique(self.target):self.p_ci.append(sum(self.target==i)/len(self.target))return self.p_cidef arg_max(self):self.final_p = np.array(self.f_i)self.max_p = np.argmax(self.final_p,axis=0)return self.max_pdef score(self):self.classification_score = sum(target==self.max_p)/len(target)print("预测分类准确率为:{} %".format(self.classification_score*100))return self.classification_scoredef start(self):mean = self.find_mean()sigma = self.find_sigma()p_c1 = self.p_c()f = self.find_f()predict = self.arg_max()c_score = self.score()if __name__=='__main__':iris = load_iris()data = iris.datatarget = iris.targetfeatures = iris.feature_namesnaive = Naive()naive.start()
我们⾸先对LDA的式⼦做⼀个变形转化:(不喜欢看推导的可以直接跳过,直接看结论)
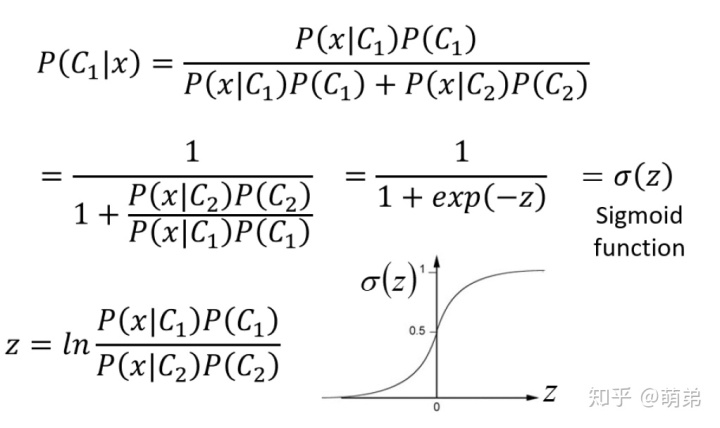



从上⾯的结论中,我们很惊讶的发现了我们之前千⾟万苦需要找的正态分布其实就是⼀个线性函数复合⼀个sigmoid函数,在LDA的估计中,我们怎么找出w和b呢?emmmm那还是找到样本估计均值和⽅差等。
我们这⾥有个想法,那就是能不能通过样本直接像线性回归⼀样直接使⽤梯度下降法求出w和b呢?答案是肯定的,但是求出来的w跟b⼀般跟LDA求出来的不太⼀样。
我们和之前步骤⼀样,先写出似然函数:

写出来后我们得到⼀个发现,这个表达式不就是交叉熵吗?(上下图对⽐)
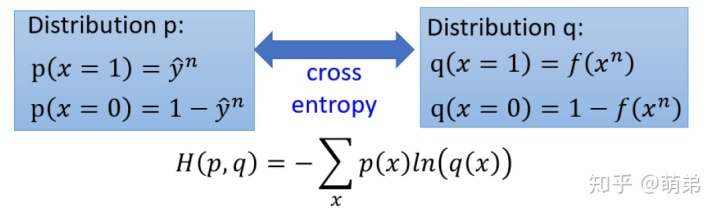
接下来求梯度:

接着迭代就算完成啦!(梯度下降的代码在之前的⽂章最优化当中有,想看的可以去找找我写的那篇⽂章)
那我们反思⼀下刚刚的步骤,我们对付分类问题上来就⽤了极⼤似然估计,误打误撞推出了交叉熵cross-entropy,那我们为什么不使⽤最⼩⼆乘法⾥⾯的平⽅和作为我们的损失函数呢?
那我们使⽤最⼩⼆乘法试试解决逻辑回归:

我们可以发现,如果真实值是0,我们预测为1,那梯度接近0;同理,我们预测为0,梯度也接近与0,我们的梯度仿佛消失了。

为了⼀探究竟,我们画个图表⽰⼀下:
红⾊的是平⽅损失,⿊⾊的是交叉熵,很明显差距就出来了,红色的很靠近0,且很平缓。
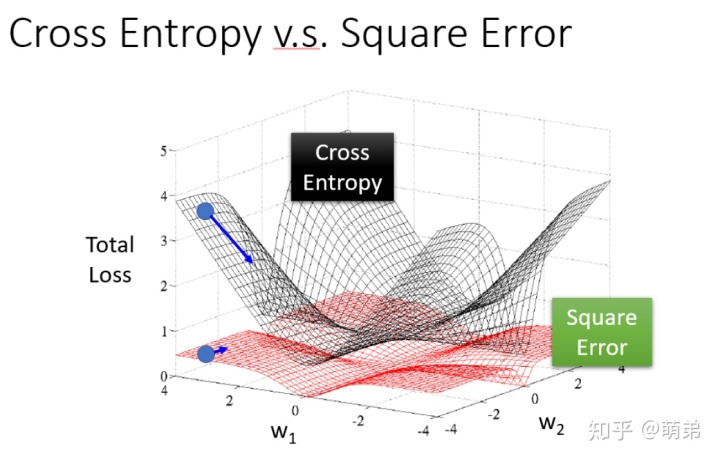
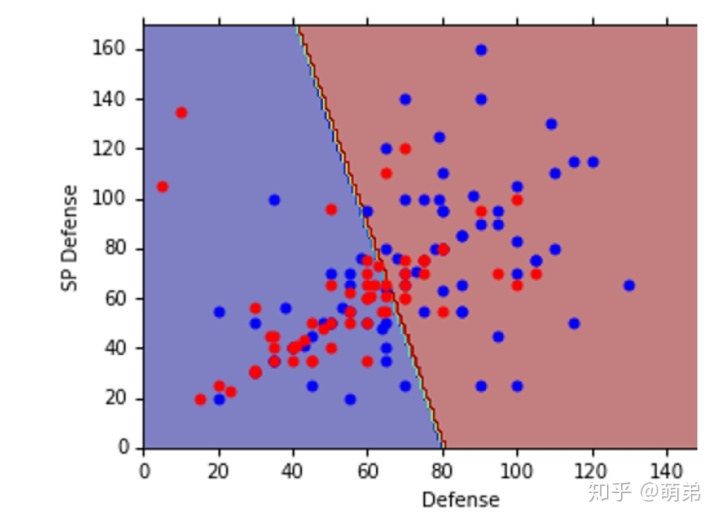
最后,我们回到LDA与Logistic Regression的⽐较中,我们发现:(左边是Logistic Regression,右边是LDA),他们的分界线不⼀样,也就是他们通过不同⽅式得出来的w和b是不⼀样的。
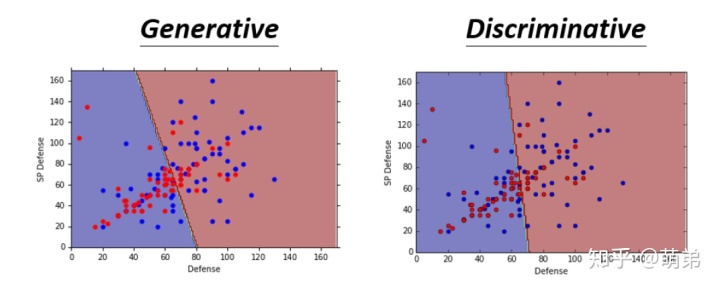
⼀般来说,在⼩样本⾥⾯LDA会显得更加优秀,⼤样本中Logistic Regression会先更更加鲁棒。
在本次分享中,我们已经把简单分类模型的前世今⽣都说清楚了,以及他们之间难以割舍的联系也讲明⽩了,我们还知道了怎么⾃⼰编写代码实现这些模型。那在下一次我们将从两个不同的发展方向给大家讲清楚机器学习的复杂的分类和回归问题是怎么做的,包括我们的深度学习和树模型支持向量机等。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态









![bzoj1639[Usaco2007 Mar]Monthly Expense 月度开支*](/upload/rand_pic/2-229.jpg)

