翻译来源:https://gitee.com/yunwisdoms/bloom
Bloom是REST API缓存中间件,充当负载平衡器和REST API辅助程序之间的反向代理。
它与您的API实施完全无关,并且只需对现有API代码进行最少的更改即可起作用。
Bloom依赖于redis,配置为缓存来存储缓存的数据。它内置于Rust中,专注于稳定性,性能和低资源使用率。
重要提示:如果您的API实现REST约定,则Bloom会很好用。您的API需要使用HTTP阅读方式,即GET,HEAD,OPTIONS仅作为读取方法(不使用HTTP GET参数,以此来更新数据)。
在Rust版本上测试: rustc 1.37.0 (eae3437df 2019-08-13)
in在法国布雷斯特(Brest)制造。
Bloom项目最初是在我的个人日记中的帖子中宣布的。
👋您使用Bloom并希望在此处列出?与我联络。
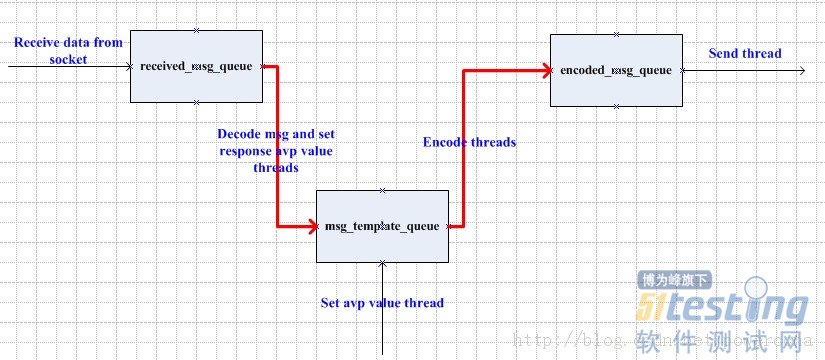
Bloom-Request-Shard(例如Main API使用shard 0,Search API使用shard 1)。Bloom-Response-Buckets。AuthorizationHTTP标头可以防止跨用户的缓存泄漏。Bloom-Request-*在请求中使用HTTP标头将负载均衡器转发到Bloom。 Bloom-Request-Shard(默认碎片为0,最大值为15)。Bloom-Response-*在对Bloom的API响应中使用HTTP标头。 Bloom-Response-Ignore(值1)的API路由的缓存。Bloom-Response-Buckets(如果有多个桶,请用逗号分隔)。Bloom-Response-TTL(默认TTL除外,以秒为单位)。304 Not Modified于非修正路线的内容,降低带宽使用和加快请求给用户。
可以将Bloom热插拔到您现有的负载均衡器(例如NGINX)和API辅助程序(例如NodeJS)之间。它最初是为了减少工作量并在API流量激增或DOS / DDoS攻击的情况下大大减少CPU使用率而构建的。
更简单的高速缓存方法可能是在负载均衡水平HTTP启用缓存读取方法(GET,HEAD,OPTIONS)。尽管作为解决方案很简单,但它不适用于REST API。REST API本质上服务于动态内容,该内容严重依赖于Authorization标头。另外,如果由于某些数据库中的数据更新而导致缓存中的内容过时,则任何时候都需要清除任何缓存。
您说,NGINX Lua脚本可以很好地完成这项工作!好吧,我坚信负载均衡器应该很简单,并且仅基于配置,而无需编写脚本。由于负载均衡器是所有HTTP / WebSocket服务的切入点,因此您要避免在那里进行频繁的部署和自定义代码,并将这种缓存复杂性移交给专用的中间件组件。
Bloom与每个API工作者都安装在同一服务器上。从您的负载均衡器可以看出,每个API工作者都有一个Bloom实例。这样,您的负载平衡设置(例如,具有运行状况检查的轮询)不会中断。可以将每个Bloom实例设置为从您的负载均衡器可以指向的自己的LAN IP可见,然后这些Bloom实例可以指向本地环回上的API工作侦听器。
布鲁姆作为它自己的反向代理,和缓存读取HTTP方法(GET,HEAD,OPTIONS),而直接进行代理HTTP写入方法(POST,PATCH,PUT等)。所有Bloom实例redis在LAN上可用的公共实例上共享相同的缓存存储。
Bloom内置Rust来实现内存安全性,代码优美性以及特别是性能。可以将Bloom编译为适用于您的服务器体系结构的本机代码。
Bloom具有最少的静态配置,并且依靠API工作人员提供的HTTP响应标头来按响应配置缓存。这些HTTP标头会被Bloom拦截,并且不会提供给您的负载均衡器响应。这些标头的格式为Bloom-Response-*。在服务响应您的负载均衡器,布鲁姆将高速缓存状态标题,即Bloom-Status可以公开在HTTP响应中可以看到(或者与价值HIT,MISS或者DIRECT-它有助于调试缓存配置)。

Bloom是在Rust中构建的。要安装它,请从Bloom发行页面下载版本,使用cargo install或从中获取源代码master。
从源安装:
如果您从Git中提取源代码,则可以使用cargo以下代码进行构建:
cargo build --release您可以在./target/release目录中找到构建的二进制文件。
从货运安装:
您可以使用cargo install以下命令直接安装Bloom :
cargo install bloom-server确保$PATH已正确配置您的资源以使用板条箱二进制文件,然后使用以下bloom命令运行Bloom 。
从软件包安装:
也提供Debian和Ubuntu软件包。请参阅如何在Debian和Ubuntu上安装它?部分。
从Docker Hub安装:
您可能会发现通过Docker运行Bloom十分方便。您可以在Docker Hub上以valeriansaliou / bloom找到预构建的Bloom映像。
首先,拉出valeriansaliou/bloom图像:
docker pull valeriansaliou/bloom:v1.28.0然后,将其作为配置文件的种子并运行(替换/path/to/your/bloom/config.cfg为配置文件的路径):
docker run -p 8080:8080 -p 8811:8811 -v /path/to/your/bloom/config.cfg:/etc/bloom.cfg valeriansaliou/bloom:v1.28.0在配置文件中,确保:
server.inet设置为0.0.0.0:8080(这样可以从容器外部访问Bloom)control.inet设置为0.0.0.0:8811(这使得可以从容器外部访问Bloom Control)从可以到达Bloom,从可以到达http://localhost:8080Bloom Control tcp://localhost:8811。
使用样本config.cfg配置文件,并将其调整到您自己的环境。
确保正确配置该[proxy]部分,以使Bloom指向您的API工作程序主机和端口。
下面列出了可用的配置选项以及允许的值:
[服务器]
log_level(类型:字符串,允许:debug,info,warn,error,缺省error) -日志的详细程度,将其设置为error在生产inet(类型:字符串,允许:IPv4 / IPv6 +端口,默认值:[::1]:8080)-Bloom服务器应侦听的主机和TCP端口[控制]
inet(类型:字符串,允许:IPv4 / IPv6 +端口,默认值:[::1]:8811)-主机和TCP端口Bloom Control应该侦听tcp_timeout(类型:integer,允许:秒,默认值:300)—与Bloom Control的空闲/死客户端连接超时[代理]
[[proxy.shard]]
shard(类型:整数,允许:0至15,默认值0:) —分片索引(使用Bloom-Request-Shardin请求路由至Bloom)host(类型:字符串,允许:主机名,IPv4,IPv6,默认值:localhost)—目标主机,以代理此分片(即,API侦听的位置)port(类型:integer,允许的:TCP端口,默认值:3000)—目标用于代理此分片的TCP端口(即API侦听的位置)[快取]
ttl_default(类型:integer,允许的:秒,默认值:600)-默认的缓存TTL,以秒为单位,如果未Bloom-Response-TTL提供executor_pool(类型:整数,允许:0至(2^16)-1,默认值16:) —高速缓存执行程序池大小(可以同时执行多少个高速缓存请求)disable_read(类型:布尔值,允许:true,false,默认:false) -是否禁用缓存中读取(用于测试)disable_write(类型:布尔值,允许:true,false,默认:false) -是否禁用缓存写入(用于测试)compress_body(类型:布尔,允许:true,false,缺省true) -是否在商店压缩体(使用Brotli;通常是由40%减少身体尺寸)[重复]
host(类型:字符串,允许:主机名,IPv4,IPv6,默认值:localhost)—目标Redis主机port(类型:整数,允许:TCP端口,默认值:6379)—目标Redis TCP端口password(类型:字符串,允许:密码值,默认值:无)— Redis密码(如果没有密码,请不要设置此键)database(类型:整数,允许:0至255,默认值:0)—目标Redis数据库pool_size(类型:integer,允许的:0to (2^32)-1,默认值:80)— Redis连接池的大小(应该比cache.executor_poolBloom代理和Bloom Control都使用更大)max_lifetime_seconds(类型:integer,允许的:秒,默认值:60)—与Redis的连接的最大生存时间(您希望其在5分钟以下,因为如果连接断开,这会影响与Redis的重新连接延迟)idle_timeout_seconds(类型:integer,允许:秒,默认值:600)—与Redis的空闲/死池连接超时connection_timeout_seconds(类型:integer,允许的:秒,默认值:1)—以秒为单位的超时,以考虑Redis死并DIRECT在不使用缓存的情况下发出与API 的连接(保持此低值,因为当Redis停机时,它决定了忽略Redis响应之前要等待的时间。并直接代理)max_key_size(类型:integer,允许的:字节,默认值:256000)—要存储在密钥的Redis中的最大数据大小(以字节为单位)(保护措施,以防止缓存很大的响应)max_key_expiration(类型:integer,允许:秒,默认值:2592000)— Redis中缓存的密钥的最大TTL(防止错误的Bloom-Response-TTL值)Bloom可以这样运行:
./bloom -c /path/to/config.cfg
重要提示:请确保为基础结构上运行的每个API工作程序启动一个Bloom实例。Bloom本身并不管理负载平衡逻辑,因此每个API辅助实例都应具有Bloom实例,并且仍然依赖于。NGINX用于负载平衡。
Bloom运行并指向您的API后,您可以将负载均衡器配置为指向Bloom IP和端口(而不是以前的API IP和端口)。
NGINX指令
➡️配置您现有的代理规则集
Bloom要求将Bloom-Request-Shard客户端请求代理到Bloom时,Load Balancer设置HTTP标头。此标头告诉Bloom用来存储数据的缓存碎片(通过这种方式,您可以为在同一服务器上侦听的不同API子系统使用单个Bloom实例)。
#您现有的规则集转到此处
proxy_pass http://(...)#为Bloom
proxy_set_header Bloom-Request-Shard 0 添加'Bloom-Request-Shard'标头;Adjust️调整您现有的CORS规则(如果使用)
如果在专用主机名的API运行(如https://api.crisp.chat用于酥),不要忘记调整你的CORS相应的规则,使API Web客户端(即浏览器)可以利用ETag的是被布卢姆添加标题。这将有助于在速度较慢的网络上加快API读取请求的速度。如果您没有现有的CORS规则,则可能不需要它们,因此请忽略它。
# Merge those headers with your existing CORS rules
add_header 'Access-Control-Allow-Headers' 'If-Match, If-None-Match' always;
add_header 'Access-Control-Expose-Headers' 'Vary, ETag' always;
请注意,分片号是0到15之间的整数(8位无符号数字,上限为16个分片)。
Bloom添加的响应头是:
浏览器添加的请求标头是Bloom添加上述请求标头的结果:
请注意,您需要将新的请求和响应标头都添加到CORS规则中。如果您忘记了其中任何一个,则对您的API的请求可能会在某些浏览器(例如带有PATCH请求的Chrome )上开始失败。
现在,Bloom在您的API之前运行,并代表它处理请求;您的API可以指示Bloom如何根据每个响应进行操作。
您的API可以在Bloom的响应中发送专用的HTTP标头,该标头由Bloom使用,并从提供给请求客户端的响应中删除(Bloom-Response-*HTTP标头)。
请注意,您的API不应以压缩格式提供响应。请在您的应用程序服务器上禁用任何Gzip或Brotli中间件,因为Bloom将无法解码压缩的响应主体。动态内容的压缩应由负载均衡器本身来处理。
➡️不要缓存响应:
要告诉Bloom不缓存响应,请发送以下HTTP标头作为API响应的一部分:
Bloom-Response-Ignore: 1
默认情况下,Bloom会保留所有可安全缓存的响应,只要它们都符合以下条件即可:
1.缓存方法:
GETHEADOPTIONS2.可缓存状态:
OKNon-Authoritative InformationNo ContentReset ContentPartial ContentMulti-StatusAlready ReportedMultiple ChoicesMoved PermanentlyFoundSee OtherPermanent RedirectUnauthorizedPayment RequiredForbiddenNot FoundMethod Not AllowedGoneURI Too LongUnsupported Media TypeRange Not SatisfiableExpectation FailedI'm A TeapotLockedFailed DependencyPrecondition RequiredRequest Header Fields Too LargeNot ImplementedNot Extended如果要查找匹配的状态码,请参考Wikipedia上的状态码列表。
➡️在响应缓存上设置过期时间:
要告诉Bloom在响应缓存上使用一定的到期时间(该时间过后缓存将失效,从而根据客户端请求获取新的响应),请将以下HTTP标头作为API响应的一部分发送(此处的TTL为60秒):
Bloom-Response-TTL: 60
默认情况下,Bloom将TTL设置为600秒(10分钟),尽管可以从进行配置config.cfg。
➡️标记缓存的响应(用于Bloom Control缓存清除):
如果您想使用Bloom Control以编程方式清除缓存的响应(请参阅缓存可以以编程方式过期吗?),则需要在缓存时对这些响应进行标记。您可以告诉Bloom在1个或多个存储桶中标记缓存的响应,如下所示:
Bloom-Response-Buckets: user_id:10012, heavy_route:1203
然后,当您需要为带有标识符的用户清除标记的响应时10012,可以在bucket上调用Bloom Control缓存清除user_id:10012。桶的流量相似heavy_route:1203。
默认情况下,缓存的响应没有标签,因此无法按原样通过Bloom Control清除它。
Bloom为基于Debian的系统(Debian,Ubuntu等)提供了预先构建的软件包。
重要信息:Bloom现在仅提供Debian 8 64位软件包(Debian Jessie)。您仍然可以在其他Debian版本以及Ubuntu上使用它们。
1️⃣添加Bloom APT存储库(例如,对于Debian Jessie):
echo “ deb https://packagecloud.io/valeriansaliou/bloom/debian/ jessie main” > /etc/apt/sources.list.d/valeriansaliou_bloom.list
curl -L https://packagecloud.io/valeriansaliou/bloom/ gpgkey 2>/dev/null | apt-key add -&> /dev/null
apt-get update2️⃣安装Bloom软件包:
apt-get install Bloom3️⃣编辑预填充的Bloom配置文件:
nano /etc/bloom.cfg4️⃣重新启动Bloom:
service bloom restart
Bloom是Rust内置的,可以将其编译为适用于您的体系结构的本机代码。不像例如 Golang不带有GC(垃圾收集器),这对于高吞吐量/高负载的生产系统通常是一件坏事(因为GC会暂停所有程序指令的执行时间,具体时间取决于有多少个引用)保留在内存中)。
请注意,相对于Bloom管理内存的方式,已经做出了一些妥协。为了简化起见,大量使用了堆分配的对象。即。您的API工作人员的响应在被提供给客户端之前已在内存中完全缓冲;这样做的好处是,即使请求者客户端的带宽很慢,API工作者也可以尽快以回送/ LAN的速度耗尽数据。
在Crisp的生产中,我们正在运行多个Bloom实例(针对我们的每个API工作者)。每个服务器处理约250个HTTP RPS(每秒请求),以及约500个Bloom Control RPS(例如,缓存清除)。每个Bloom实例都在单个2016 Xeon vCPU上运行,该CPU与512MB RAM配对。那种HTTP请求的手柄布鲁姆是平衡的读取之间(GET,HEAD,OPTIONS)和写入(POST,PATCH,PUT等)。
htop在以这种负载运行Bloom的服务器上,我们得到以下反馈:
如您所见,Bloom仅占用很小的CPU时间(少于5%),而占用的RAM较小(〜5%,即〜25MB)。在如此小的服务器上,我们可以预测Bloom可以扩展到更高的速率(例如10k RPS),而不会给系统带来太大的压力(底层的NodeJS API工作者将首先过热,因为它要比Bloom重得多)。
如果您希望Bloom处理非常高的RPS,请确保将cache.executor_pool和redis.pool_size选项设置为更高的值(如果Redis链接上有几毫秒的延迟,这可能会限制RPS-因为Redis连接正在阻塞)。
REST API通常使用经过身份验证的路由来返回请求者用户专用的数据。Bloom是一个缓存系统,至关重要的是,不会发生来自经过身份验证的路由的缓存泄漏。Bloom通过为发送HTTP Authorization标头的请求隔离名称空间中的缓存,轻松解决了该问题。这是默认的安全行为。
如果请求的路由没有HTTP Authorization标头(即请求是匿名的/公共的),则无论HTTP响应代码如何,该响应都将由Bloom缓存。
由于您的HTTP Authorization标头包含敏感的身份验证数据(即用户名和密码),因此Bloom将存储散列到其中的那些值redis(使用加密散列函数)。这样,redis您身边的数据库泄漏将使攻击者无法恢复身份验证密钥对。
是。当您现有的API工作人员在其末端执行数据库更新时,他们已经很清楚何时可能由Bloom缓存的数据变旧了。因此,Bloom提供了一种有效的方法来告诉它使给定存储桶的缓存过期。该系统称为Bloom Control。
可以将Bloom配置为侦听TCP套接字以公开缓存控制接口。默认的TCP端口为8811。Bloom实现基本的Command-ACK协议。
这样,您的API工作者(或基础架构中的任何其他工作者)可以告诉Bloom:
Authorization标头的缓存的变体,因此,当您清除存储桶的缓存时,将同时清除所有身份验证令牌的存储桶缓存。Authorization标头的缓存过期。如果用户注销并撤消其身份验证令牌,则很有用。Available️可用命令:
FLUSHB <namespace>:给定存储桶名称空间的刷新缓存FLUSHA <authorization>:刷新给定授权的缓存SHARD <shard>:选择用于连接的碎片PING:ping服务器QUIT:停止连接Control️控制流程示例:
telnet bloom.local 8811
正在尝试:: 1 ...
已连接到bloom.local。
转义字符为'^]' 。
CONNECTED <盛开V1.0.0>
HASHREQ hxHw4AXWSS
HASHRES 753a5309
STARTED
碎片1
行
FLUSHB 2eb6c00c
行
FLUSHA b44c6f8e
行
PING
PONG
QUIT
截至不干
连接由外部主机关闭。注意:在发出任何命令之前,Bloom要求客户端针对Bloom内部哈希器(用HASHREQand HASHRES交换完成)验证其哈希器功能。FarmHash使用FarmHash.fingerprint32()来对密钥进行哈希处理,其计算结果可能在不同体系结构之间有所不同。这样,可以提前防止大多数怪异的Bloom Control问题。
📦Bloom Control库:
👉无法找到您的编程语言的库?建立自己的并在这里引用!(与我联系)
如果在Bloom中发现漏洞,欢迎通过向valerian@valeriansaliou.name发送加密的电子邮件直接将其报告给@valeriansaliou。不要在公共GitHub问题中报告漏洞,因为恶意人员可能利用这些漏洞来针对运行未打补丁的Bloom实例的生产服务器。
您必须使用@valeriansaliou GPG公共密钥
valeriansaliou.gpg.pub.asc加密电子邮件。
根据漏洞的严重程度,我可能会向举报该漏洞的人提供200美元的奖金。
Bloom is a REST API caching middleware, acting as a reverse proxy between your load balancers and your REST API workers.
It is completely agnostic of your API implementation, and requires minimal changes to your existing API code to work.
Bloom relies on redis, configured as a cache to store cached data. It is built in Rust and focuses on stability, performance and low resource usage.
Important: Bloom works great if your API implements REST conventions. Your API needs to use HTTP read methods, namely GET, HEAD, OPTIONS solely as read methods (do not use HTTP GET parameters as a way to update data).
Tested at Rust version: rustc 1.37.0 (eae3437df 2019-08-13)
🇫🇷 Crafted in Brest, France.
The Bloom project was initially announced in a post on my personal journal.
| Crisp |
👋 You use Bloom and you want to be listed there? Contact me.
Bloom-Request-Shard (eg. Main API uses shard 0, Search API uses shard 1).Bloom-Response-Buckets.Authorization HTTP header.Bloom-Request-* HTTP headers in the requests your Load Balancers forward to Bloom. Bloom-Request-Shard (default shard is 0, maximum value is 15).Bloom-Response-* HTTP headers in your API responses to Bloom. Bloom-Response-Ignore (with value 1).Bloom-Response-Buckets (comma-separated if multiple buckets).Bloom-Response-TTL (other than default TTL, number in seconds).304 Not Modified to non-modified route contents, lowering bandwidth usage and speeding up requests to your users.Bloom can be hot-plugged to sit between your existing Load Balancers (eg. NGINX), and your API workers (eg. NodeJS). It has been initially built to reduce the workload and drastically reduce CPU usage in case of API traffic spike, or DOS / DDoS attacks.
A simpler caching approach could have been to enable caching at the Load Balancer level for HTTP read methods (GET, HEAD, OPTIONS). Although simple as a solution, it would not work with a REST API. REST API serve dynamic content by nature, that rely heavily on Authorization headers. Also, any cache needs to be purged at some point, if the content in cache becomes stale due to data updates in some database.
NGINX Lua scripts could do that job just fine, you say! Well, I firmly believe Load Balancers should be simple, and be based on configuration only, without scripting. As Load Balancers are the entry point to all your HTTP / WebSocket services, you'd want to avoid frequent deployments and custom code there, and handoff that caching complexity to a dedicated middleware component.
Bloom is installed on the same server as each of your API workers. As seen from your Load Balancers, there is a Bloom instance per API worker. This way, your Load Balancing setup (eg. Round-Robin with health checks) is not broken. Each Bloom instance can be set to be visible from its own LAN IP your Load Balancers can point to, and then those Bloom instances can point to your API worker listeners on the local loopback.
Bloom acts as a Reverse Proxy of its own, and caches read HTTP methods (GET, HEAD, OPTIONS), while directly proxying HTTP write methods (POST, PATCH, PUT and others). All Bloom instances share the same cache storage on a common redis instance available on the LAN.
Bloom is built in Rust for memory safety, code elegance and especially performance. Bloom can be compiled to native code for your server architecture.
Bloom has minimal static configuration, and relies on HTTP response headers served by your API workers to configure caching on a per-response basis. Those HTTP headers are intercepted by Bloom and not served to your Load Balancer responses. Those headers are formatted as Bloom-Response-*. Upon serving response to your Load Balancers, Bloom sets a cache status header, namely Bloom-Status which can be seen publicly in HTTP responses (either with value HIT, MISS or DIRECT — it helps debug your cache configuration).
Bloom is built in Rust. To install it, either download a version from the Bloom releases page, use cargo install or pull the source code from master.
Install from source:
If you pulled the source code from Git, you can build it using cargo:
cargo build --releaseYou can find the built binaries in the ./target/release directory.
Install from Cargo:
You can install Bloom directly with cargo install:
cargo install bloom-serverEnsure that your $PATH is properly configured to source the Crates binaries, and then run Bloom using the bloom command.
Install from packages:
Debian & Ubuntu packages are also available. Refer to the How to install it on Debian & Ubuntu? section.
Install from Docker Hub:
You might find it convenient to run Bloom via Docker. You can find the pre-built Bloom image on Docker Hub as valeriansaliou/bloom.
First, pull the valeriansaliou/bloom image:
docker pull valeriansaliou/bloom:v1.28.0Then, seed it a configuration file and run it (replace /path/to/your/bloom/config.cfg with the path to your configuration file):
docker run -p 8080:8080 -p 8811:8811 -v /path/to/your/bloom/config.cfg:/etc/bloom.cfg valeriansaliou/bloom:v1.28.0In the configuration file, ensure that:
server.inet is set to 0.0.0.0:8080 (this lets Bloom be reached from outside the container)control.inet is set to 0.0.0.0:8811 (this lets Bloom Control be reached from outside the container)Bloom will be reachable from http://localhost:8080, and Bloom Control will be reachable from tcp://localhost:8811.
Use the sample config.cfg configuration file and adjust it to your own environment.
Make sure to properly configure the [proxy] section so that Bloom points to your API worker host and port.
Available configuration options are commented below, with allowed values:
[server]
log_level (type: string, allowed: debug, info, warn, error, default: error) — Verbosity of logging, set it to error in productioninet (type: string, allowed: IPv4 / IPv6 + port, default: [::1]:8080) — Host and TCP port the Bloom server should listen on[control]
inet (type: string, allowed: IPv4 / IPv6 + port, default: [::1]:8811) — Host and TCP port Bloom Control should listen ontcp_timeout (type: integer, allowed: seconds, default: 300) — Timeout of idle/dead client connections to Bloom Control[proxy]
[[proxy.shard]]
shard (type: integer, allowed: 0 to 15, default: 0) — Shard index (routed using Bloom-Request-Shard in requests to Bloom)host (type: string, allowed: hostname, IPv4, IPv6, default: localhost) — Target host to proxy to for this shard (ie. where the API listens)port (type: integer, allowed: TCP port, default: 3000) — Target TCP port to proxy to for this shard (ie. where the API listens)[cache]
ttl_default (type: integer, allowed: seconds, default: 600) — Default cache TTL in seconds, when no Bloom-Response-TTL providedexecutor_pool (type: integer, allowed: 0 to (2^16)-1, default: 16) — Cache executor pool size (how many cache requests can execute at the same time)disable_read (type: boolean, allowed: true, false, default: false) — Whether to disable cache reads (useful for testing)disable_write (type: boolean, allowed: true, false, default: false) — Whether to disable cache writes (useful for testing)compress_body (type: boolean, allowed: true, false, default: true) — Whether to compress body upon store (using Brotli; usually reduces body size by 40%)[redis]
host (type: string, allowed: hostname, IPv4, IPv6, default: localhost) — Target Redis hostport (type: integer, allowed: TCP port, default: 6379) — Target Redis TCP portpassword (type: string, allowed: password values, default: none) — Redis password (if no password, dont set this key)database (type: integer, allowed: 0 to 255, default: 0) — Target Redis databasepool_size (type: integer, allowed: 0 to (2^32)-1, default: 80) — Redis connection pool size (should be a bit higher than cache.executor_pool, as it is used by both Bloom proxy and Bloom Control)max_lifetime_seconds (type: integer, allowed: seconds, default: 60) — Maximum lifetime of a connection to Redis (you want it below 5 minutes, as this affects the reconnect delay to Redis if a connection breaks)idle_timeout_seconds (type: integer, allowed: seconds, default: 600) — Timeout of idle/dead pool connections to Redisconnection_timeout_seconds (type: integer, allowed: seconds, default: 1) — Timeout in seconds to consider Redis dead and emit a DIRECT connection to API without using cache (keep this low, as when Redis is down it dictates how much time to wait before ignoring Redis response and proxying directly)max_key_size (type: integer, allowed: bytes, default: 256000) — Maximum data size in bytes to store in Redis for a key (safeguard to prevent very large responses to be cached)max_key_expiration (type: integer, allowed: seconds, default: 2592000) — Maximum TTL for a key cached in Redis (prevents erroneous Bloom-Response-TTL values)Bloom can be run as such:
./bloom -c /path/to/config.cfg
Important: make sure to spin up a Bloom instance for each API worker running on your infrastructure. Bloom does not manage the Load Balancing logic itself, so you should have a Bloom instance per API worker instance and still rely on eg. NGINX for Load Balancing.
Once Bloom is running and points to your API, you can configure your Load Balancers to point to Bloom IP and port (instead of your API IP and port as previously).
NGINX instructions
➡️ Configure your existing proxy ruleset
Bloom requires the Bloom-Request-Shard HTTP header to be set by your Load Balancer upon proxying a client request to Bloom. This header tells Bloom which cache shard to use for storing data (this way, you can have a single Bloom instance for different API sub-systems listening on the same server).
# Your existing ruleset goes here
proxy_pass http://(...)# Adds the 'Bloom-Request-Shard' header for Bloom
proxy_set_header Bloom-Request-Shard 0;➡️ Adjust your existing CORS rules (if used)
If your API runs on a dedicated hostname (eg. https://api.crisp.chat for Crisp), do not forget to adjust your CORS rules accordingly, so that API Web clients (ie. browsers) can leverage the ETag header that gets added by Bloom. This will help speed up API read requests on slower networks. If you don't have existing CORS rules, you may not need them, so ignore this.
# Merge those headers with your existing CORS rules
add_header 'Access-Control-Allow-Headers' 'If-Match, If-None-Match' always;
add_header 'Access-Control-Expose-Headers' 'Vary, ETag' always;Note that a shard number is an integer from 0 to 15 (8-bit unsigned number, capped to 16 shards).
The response headers that get added by Bloom are:
The request headers that get added by the browser, as a consequence of Bloom adding the request headers above are:
Note that you need to add both new request and response headers to your CORS rules. If you forget either one, requests to your API may start to fail on certain browsers (eg. Chrome with PATCH requests).
Now that Bloom is running in front of your API and serving requests on behalf of it; your API can instruct Bloom how to behave on a per-response basis.
Your API can send private HTTP headers in responses to Bloom, that are used by Bloom and removed from the response that is served to the request client (the Bloom-Response-* HTTP headers).
Note that your API should not serve responses in a compressed format. Please disable any Gzip or Brotli middleware on your application server, as Bloom will not be able to decode compressed response bodies. Compression of dynamic content should be handled by the load balancer itself.
➡️ Do not cache response:
To tell Bloom not to cache a response, send the following HTTP header as part of the API response:
Bloom-Response-Ignore: 1
By default, Bloom retains all responses that are safe to cache, as long as they match both:
1. Cacheable methods:
GETHEADOPTIONS2. Cacheable status:
OKNon-Authoritative InformationNo ContentReset ContentPartial ContentMulti-StatusAlready ReportedMultiple ChoicesMoved PermanentlyFoundSee OtherPermanent RedirectUnauthorizedPayment RequiredForbiddenNot FoundMethod Not AllowedGoneURI Too LongUnsupported Media TypeRange Not SatisfiableExpectation FailedI'm A TeapotLockedFailed DependencyPrecondition RequiredRequest Header Fields Too LargeNot ImplementedNot ExtendedRefer to the list of status codes on Wikipedia if you want to find the matching status codes.
➡️ Set an expiration time on response cache:
To tell Bloom to use a certain expiration time on response cache (time after which the cache is invalidated and thus a new response is fetched upon client request), send the following HTTP header as part of the API response (here for a TTL of 60 seconds):
Bloom-Response-TTL: 60
By default, Bloom sets a TTL of 600 seconds (10 minutes), though this can be configured from config.cfg.
➡️ Tag a cached response (for Bloom Control cache purge):
If you'd like to use Bloom Control to programatically purge cached responses (see Can cache be programatically expired?), you will need to tag those responses when they get cached. You can tell Bloom to tag a cached response in 1 or more bucket, as such:
Bloom-Response-Buckets: user_id:10012, heavy_route:1203
Then, when you need to purge the tagged responses for user with identifier 10012, you can call a Bloom Control cache purge on bucket user_id:10012. The flow is similar for bucket heavy_route:1203.
By default, a cached response has no tag, thus it cannot be purged via Bloom Control as-is.
Bloom provides pre-built packages for Debian-based systems (Debian, Ubuntu, etc.).
Important: Bloom only provides Debian 8 64 bits packages for now (Debian Jessie). You will still be able to use them on other Debian versions, as well as Ubuntu.
1️⃣ Add the Bloom APT repository (eg. for Debian Jessie):
echo "deb https://packagecloud.io/valeriansaliou/bloom/debian/ jessie main" > /etc/apt/sources.list.d/valeriansaliou_bloom.list
curl -L https://packagecloud.io/valeriansaliou/bloom/gpgkey 2> /dev/null | apt-key add - &>/dev/null
apt-get update2️⃣ Install the Bloom package:
apt-get install bloom3️⃣ Edit the pre-filled Bloom configuration file:
nano /etc/bloom.cfg4️⃣ Restart Bloom:
service bloom restartBloom is built in Rust, which can be compiled to native code for your architecture. Rust, unlike eg. Golang, doesn't carry a GC (Garbage Collector), which is usually a bad thing for high-throughput / high-load production systems (as a GC halts all program instruction execution for an amount of time that depends on how many references are kept in memory).
Note that some compromises have been made relative to how Bloom manages memory. Heap-allocated objects are heavily used for the sake of simplicify. ie. responses from your API workers are fully buffered in memory before they are served to the client; which has the benefit of draining data from your API workers as fast as your loopback / LAN goes, even if the requester client has a very slow bandwidth.
In production at Crisp, we're running multiple Bloom instances (for each of our API worker). Each one handles ~250 HTTP RPS (Requests Per Second), as well as ~500 Bloom Control RPS (eg. cache purges). Each Bloom instance runs on a single 2016 Xeon vCPU paired with 512MB RAM. The kind of HTTP requests Bloom handles is balanced between reads (GET, HEAD, OPTIONS) and writes (POST, PATCH, PUT and others).
We get the following htop feedback on a server running Bloom at such load:
As you can see, Bloom consumes only a fraction of the CPU time (less than 5%) for a small RAM footprint (~5% which is ~25MB). On such a small server, we can predict Bloom could scale to even higher rates (eg. 10k RPS) without putting too much pressure on the system (the underlying NodeJS API worker would be overheating first as it's much heavier than Bloom).
If you want Bloom to handle very high RPS, make sure to adjust the cache.executor_pool and the redis.pool_size options to higher values (which may limit your RPS if you have a few milliseconds of latency on your Redis link — as Redis connections are blocking).
Authenticated routes are usually used by REST API to return data that's private to the requester user. Bloom being a cache system, it is critical that no cache leak from an authenticated route occur. Bloom solves the issue easily by isolating cache in namespaces for requests that send an HTTP Authorization header. This is the default, secure behavior.
If a route is being requested without HTTP Authorization header (ie. the request is anonymous / public), whatever the HTTP response code, that response will be cached by Bloom.
As your HTTP Authorization header contains sensitive authentication data (ie. username and password), Bloom stores those values hashed in redis (using a cryptographic hash function). That way, a redis database leak on your side will not allow an attacker to recover authentication key pairs.
Yes. As your existing API workers perform the database updates on their end, they are already well aware of when data - that might be cached by Bloom - gets stale. Therefore, Bloom provides an efficient way to tell it to expire cache for a given bucket. This system is called Bloom Control.
Bloom can be configured to listen on a TCP socket to expose a cache control interface. The default TCP port is 8811. Bloom implements a basic Command-ACK protocol.
This way, your API worker (or any other worker in your infrastructure) can either tell Bloom to:
Authorization headers, bucket cache for all authentication tokens is purged at the same time when you purge cache for a bucket.Authorization header. Useful if an user logs-out and revokes their authentication token.➡️ Available commands:
FLUSHB <namespace>: flush cache for given bucket namespaceFLUSHA <authorization>: flush cache for given authorizationSHARD <shard>: select shard to use for connectionPING: ping serverQUIT: stop connection⬇️ Control flow example:
telnet bloom.local 8811
Trying ::1...
Connected to bloom.local.
Escape character is '^]'.
CONNECTED <bloom v1.0.0>
HASHREQ hxHw4AXWSS
HASHRES 753a5309
STARTED
SHARD 1
OK
FLUSHB 2eb6c00c
OK
FLUSHA b44c6f8e
OK
PING
PONG
QUIT
ENDED quit
Connection closed by foreign host.Notice: before any command can be issued, Bloom requires the client to validate its hasher function against the Bloom internal hasher (done with the HASHREQ and HASHRES exchange). FarmHash is used to hash keys, using the FarmHash.fingerprint32(), which computed results may vary between architectures. This way, most weird Bloom Control issues are prevented in advance.
📦 Bloom Control Libraries:
👉 Cannot find the library for your programming language? Build your own and be referenced here! (contact me)
If you find a vulnerability in Bloom, you are more than welcome to report it directly to @valeriansaliou by sending an encrypted email to valerian@valeriansaliou.name. Do not report vulnerabilities in public GitHub issues, as they may be exploited by malicious people to target production servers running an unpatched Bloom instance.
You must encrypt your email using @valeriansaliou GPG public key:
valeriansaliou.gpg.pub.asc.
Based on the severity of the vulnerability, I may offer a $200 (US) bounty to whomever reported it.
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态


![[Wayland] (二) 代码结构 [FW]](https://images2015.cnblogs.com/blog/753004/201607/753004-20160720100837341-320217114.png)





![centsos7修改主机名 [root@st152 ~]# cat /etc/hostname](http://static.blog.csdn.net/images/save_snippets.png)