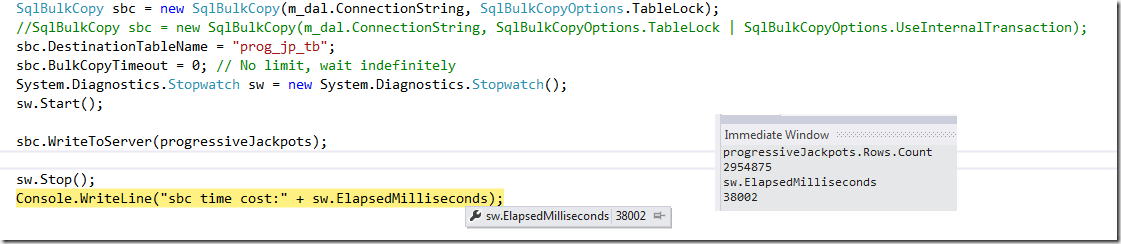
废话少说,先看效果。295万多条业务数据一次性插入数据库的一个表中,数据大小大约为280M,总耗时38秒。上图,
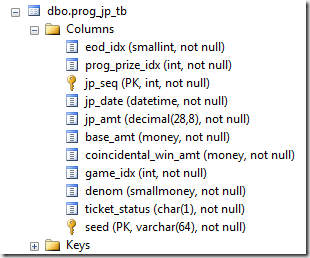
python for,表的定义是这样的,
如果使用事务,那么时间增长到46s,也就是多了8s。我用SqlBulkCopy的InternalTransaction做的测试,
SqlBulkCopy sbc = new SqlBulkCopy(m_dal.ConnectionString, SqlBulkCopyOptions.TableLock | SqlBulkCopyOptions.UseInternalTransaction);
几点特殊说明: SqlBulkCopy只适合做Insert操作,需要Upate数据的就别尝试了。
BatchSize我没设置,默认为0, 是一次全部提交所有数据。
表有个Clustered Index。
把数据全部读取到内存的一个DataTable中(作为SqlBulkCopy的输入、数据源),比较耗费内存。可以IDataReader读取数据的方式。
测试程序和数据库在一台机器上,没有网络延时。
国外有网友做了更为详细的测试,请移步“SqlBulkCopy-Performance-1.0”。文中有几个重要的结论这里摘录一下:
Batch Size The results are quite surprising. If we use the BatchSize parameter, performance get worse and worse as we set it to lower values.
When we reach 10.000 of Batch Size, then the difference in time among the various tests becomes very small.
the best performance is obtained when we use 0 as BatchSize
TABLOCK needed to get minimal logged operations.
to get best speed BULK INSERT operations.
Clustered vs Heap it is interesting to note that the loading time of a clustered table is roughly 4 times the loading of a heap.
it is always better to first drop the index and re- create it afterwards. The gain in performance is tremendous.
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态