说在前面的话
hive的正则表达式,是非常重要!作为大数据开发人员,用好hive,正则表达式,是必须品!
Hive中的正则表达式还是很强大的。数据工作者平时也离不开正则表达式。对此,特意做了个hive正则表达式的小结。所有代码都经过亲测,正常运行。
语法: A REGEXP B
操作类型: strings
描述: 功能与RLIKE相同
select count(*) from olap_b_dw_hotelorder_f where create_date_wid not regexp '\\d{8}' 与下面查询的效果是等效的:
select count(*) from olap_b_dw_hotelorder_f where create_date_wid not rlike '\\d{8}';
语法: regexp_extract(string subject, string pattern, int index)
返回值: string
说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
hive> select regexp_extract('IloveYou','I(.*?)(You)',1) from test1 limit 1;
Total jobs = 1
...
Total MapReduce CPU Time Spent: 7 seconds 340 msec
OK
love
Time taken: 28.067 seconds, Fetched: 1 row(s)
hive> select regexp_extract('IloveYou','I(.*?)(You)',2) from test1 limit 1;
Total jobs = 1
...
OK
You
Time taken: 26.067 seconds, Fetched: 1 row(s)
hive> select regexp_extract('IloveYou','(I)(.*?)(You)',1) from test1 limit 1;
Total jobs = 1
...
OK
I
Time taken: 26.057 seconds, Fetched: 1 row(s)
hive> select regexp_extract('IloveYou','(I)(.*?)(You)',0) from test1 limit 1;
Total jobs = 1
...
OK
IloveYou
Time taken: 28.06 seconds, Fetched: 1 row(s)
hive> select regexp_replace("IloveYou","You","") from test1 limit 1;
Total jobs = 1
...
OK
Ilove
Time taken: 26.063 seconds, Fetched: 1 row(s)
语法: regexp_replace(string A, string B, string C)
返回值: string
说明:将字符串A中的符合Java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似Oracle中的regexp_replace函数。
hive> select regexp_replace("IloveYou","You","") from test1 limit 1;
Total jobs = 1
...
OK
Ilove
Time taken: 26.063 seconds, Fetched: 1 row(s)
hive> select regexp_replace("IloveYou","You","lili") from test1 limit 1;
Total jobs = 1
...
OK
Ilovelili
Hive里的正则表达式
如,https://cwiki.apache.org/confluence/display/Hive/GettingStarted
输入regex可查到
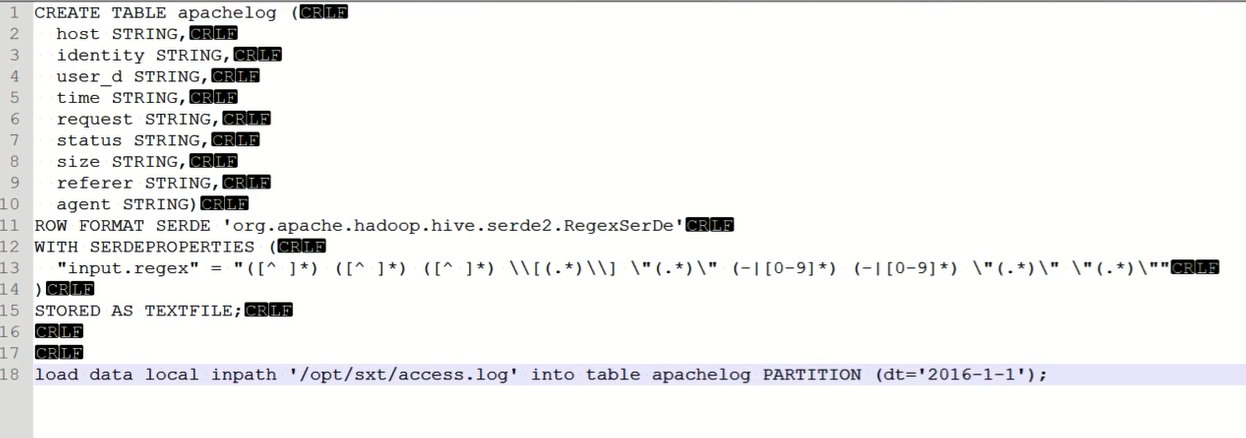
CREATE TABLE apachelog (
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^]*) \[()\] ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;
下面就是hive里的正则表达式,9个字段,对应定义那边也要9个
"input.regex" = "([^ ]*) ([^ ]*) ([^.]*) \[(.*)\] "(.*)" (-|[0-9]*) (-|[(0-9]*) "(.*)" "(.*)""
([^ ]*) ([^ ]*) ([^.]*) \[(.*)\] "(.*)" (-|[0-9]*) (-|[(0-9]*) "(.*)" "(.*)"
([^ ]*) ([^ ]*) ([^.]*) \\[(.*)\\] "(.*)" (-|[0-9]*) (-|[(0-9]*) \"(.*)\" \"(.*)\"
数据来源,
yarn-root-nodemanager-master.log
或
yarn-spark-nodemanager-master.log
yarn-hadoop-nodemanager-master.log
这里,有个正则表达式的好工具!
RegexBuddy.exe

很好用的这款软件!双击它即可。
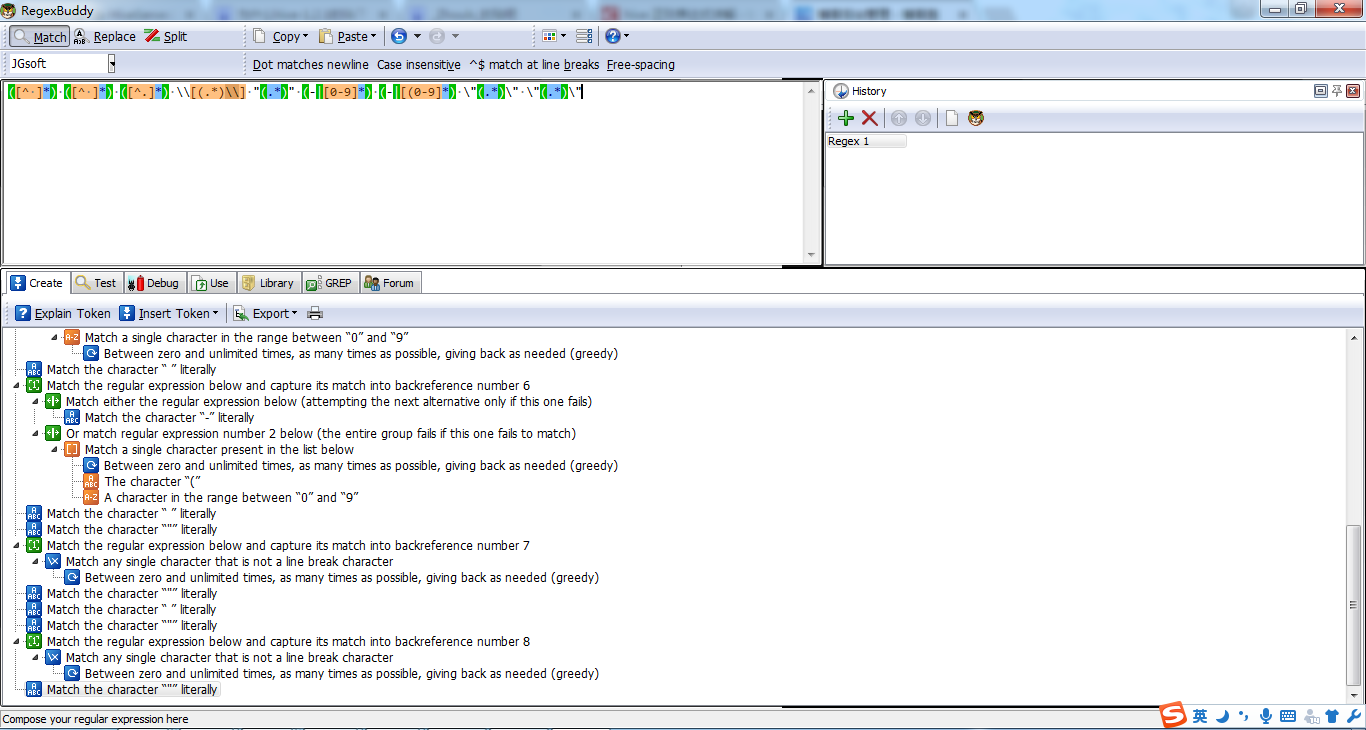
如上图所示颜色,代表我们测试的正则表达式,是正确的!

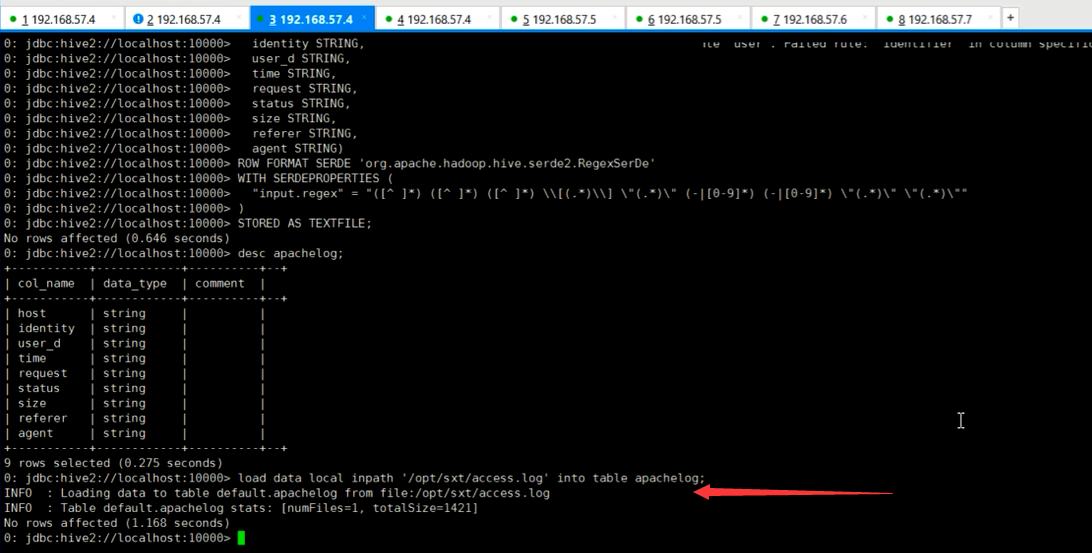

本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6102789.html,如需转载请自行联系原作者
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态